2020年 6月 20日にAthenaに追加された機能Partition Projectionについて紹介していきたいと思います。
Partition Projectionについて
通常Athenaはパーティショニングされたテーブルに対してクエリを実行する際にAWS GlueのデータカタログやHive Metastoreからテーブルのメタデータ情報(パーティション情報やカラム情報など)を取得し、クエリを処理します。
その際にパーティションが多数存在する場合、メタデータを取得する時間がボトルネックとなる可能性があります。
一方、Partition Projectionを用いた場合、GlueやHive Metastoreへメタデータを取得せずにAthenaのテーブル設定を参照してパーティション情報を取得します。そのため、パーティションが多数存在することによるボトルネックを緩和することが可能になります。
また、Partition Projectionはパーティション管理を自動化することも可能です。
パーティションを更新する主流な方法は、
① AthenaでMSCK REPAIR TABLE {table}; を実行する
② GlueのClawlerを実行する
などが挙げられます。
データの特性にもよりますが、Patition Projectionを用いることでこれらの方法を採用せずとも自動でパーティション管理を行うことが可能です。
データの準備
以下のcsvファイルを用意します。
2020-07.csv
name,age,registration_date
Aoki,19,2020/7/14
Saito,22,2020/7/2
Tanaka,21,2020/7/22
2020-08.csv
name,age,registration_date
Aogasa,27,2020/8/26
Suzuki,32,2020/8/6
Fujiwara,18,2020/8/18
2020-09-birthday.csv
name,age,registration_date
Irie,33,2020/9/11
Sato,22,2020/9/9
Yoshida,21,2020/9/5
この3つのファイルのうち、2つのファイルをS3へ配置します。
- s3://inu-is-dog/registration-dataset/year=2020/month=7/2020-07.csv
- s3://inu-is-dog/registration-dataset/year=2020/month=8/2020-08.csv
CTASを使ってテーブルの作成
AthenaのCTASを用いてPartition Projectionを適用されたテーブルを作成します。
CTASについてはこちらの記事をご参考ください。
CREATE EXTERNAL TABLE default.registration_table (
name string,
age int,
registration_date string
)
PARTITIONED BY (
`year` int,
`month` int
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://inu-is-dog/registration-dataset/'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.year.type' = 'integer',
'projection.year.range' = '2018,2020',
'projection.year.interval' = '1',
'projection.month.type' = 'integer',
'projection.month.range' = '1,12',
'projection.month.interval' = '1',
'storage.location.template' = 's3://inu-is-dog/registration-dataset/year=${year}/month=${month}/',
'classification'='csv',
'delimiter'=',',
'typeOfData'='file',
'skip.header.line.count'='1',
'serialization.encoding'='utf8'
)
今回ポイントとなるのがTBLPROPERTIESの以下の項目です。
-
projection.enabled:Partition Projectionが有効かどうか(true or false) -
projection.{partition_name}.type:パーティションのデータ型 -
projection.{partition_name}.range:パーティションの値の範囲 今回はyearが2018~2020、monthが1~12が範囲となります。 -
projection.{partition_name}.interval:パーティションの間隔になります。今回はyearもmonthも設定値が1ですが、例えばprojection.month.interval=3とするとmonthのパーティションはmonth=1,4,7,10になります。 -
storage.location.template:s3パスの中のどこがパーティションの値なのかを指定する。
projection.{partition_name}.typeにはdate型も使用できて範囲を現在日時(UTC)で制限できる点が特徴的です。
Supported Types for Partition Projection 公式ドキュメント
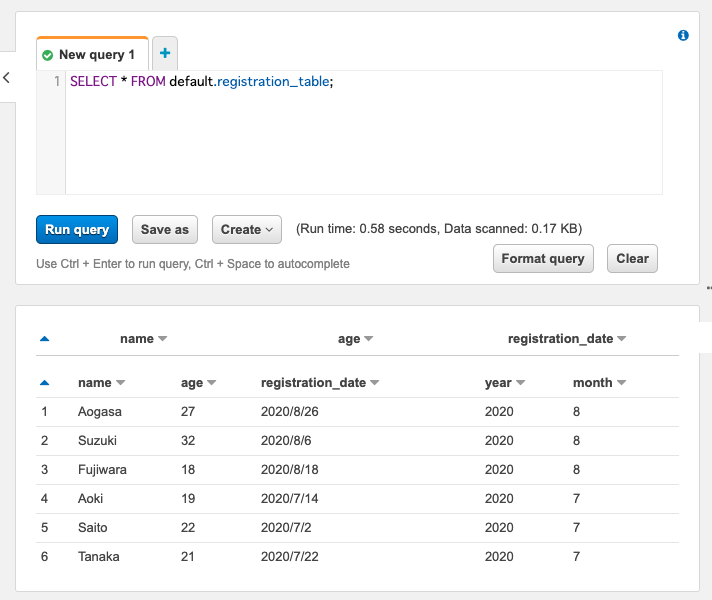
テーブルを作成できたのでクエリを投げてみます。
SELECT * FROM default.registration_table;
検証
s3://inu-is-dog/registration-dataset/year=2020/month=9/2020-09.csv にデータを配置して改めてクエリを実行します。
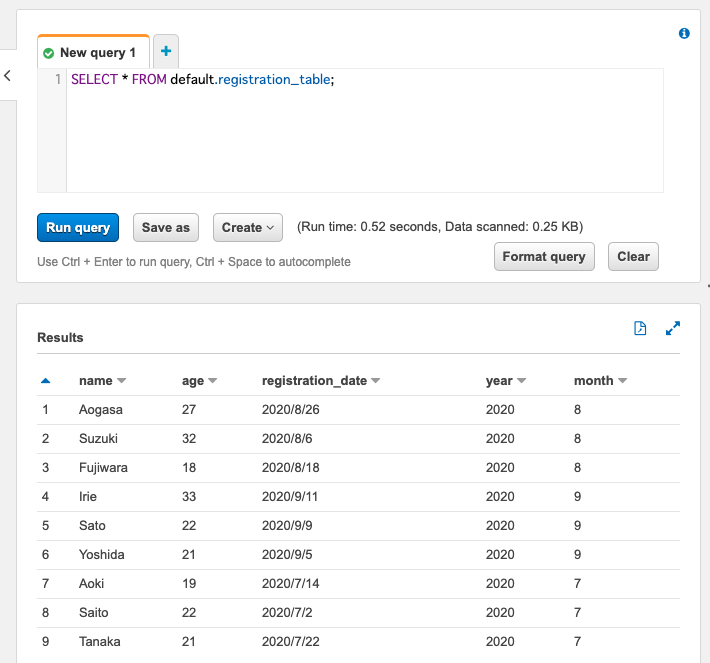
無事、9月分のデータが読み込まれていますね。
Partition Projectionを設定していない場合、MSCK REPAIR TABLE default.registration; 等を実行してメタデータを更新しなければ9月のデータはAthenaで読み取ることができません。
したがって、パーティションの範囲や値がある程度予想できる場合はPartition Projectionを設定することでメタデータを更新する手間を省くことができます。
※Partiton Projectionで登録されたパーティション情報はAWS Glueのデータカタログ もしくは Hive metastoreに反映されないので注意が必要です。
動的なパーティション
device_idといった動的なパーティションを作成する場合はInjected TypeのProjectionを使用することがおすすめです
例えば、s3://<bucket_name>/<prefix>/${device_id}/../.. といった配置になるケースですね
Dynamic ID Partitioning 公式ドキュメント
GlueからPartition Projectionを設定
GlueからもPartition Projectionを設定することができます。
コンソールからGlueのサービスに遷移して
[データカタログ>データベース>テーブル] → [対象のテーブルを選択] → [テーブルの編集]
Partition Projectionに必要な項目を入力
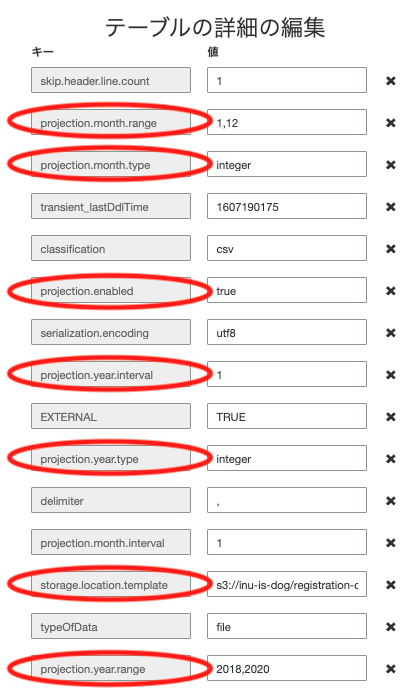
これでPartition Projectionを設定したテーブルへ変更することができます。
最後に
今回はAthenaのPartition Projectionについて紹介させていただきました。
個人的にはQuickSightのデータセット更新でAthenaを使用することが多く、新しいパーティションが追加されるたびにメタデータを更新するということを手動で行っていたのでこの機能は大変助かりました。