しばらく触ってなかったらすっかり忘れてしまったKusto。
最近またログ解析が忙しくなったのでチートシート作成。
ちなみにサンプルに使用したデータテーブルは流行のChatGPTで生成。
今回はデータテーブルもリテラルで定義するのでKustoクエリ実行環境さえあれば良い状態にしてあります。ログ解析中ならエディタのどこかにコピペすれば随時実行してみて参考に出来ると思います。
よく使う便利な処理
まずは以下のスニペットをそっくりコピペして実行します。結果が6つ出るはずです。
let sales = datatable(TransactionId:int, TransactionDate:datetime, Category:string, SKU:string)
[
1, datetime(2022-03-01T09:30:00Z), "Laptop", "SKU1001",
2, datetime(2022-03-01T10:00:00Z), "Phone", "SKU1002",
3, datetime(2022-03-01T11:30:00Z), "Tablet", "SKU1003",
4, datetime(2022-03-01T12:00:00Z), "Desktop", "SKU1004",
5, datetime(2022-03-01T13:30:00Z), "Smartwatch", "SKU1005",
6, datetime(2022-03-01T14:00:00Z), "Earbuds", "SKU1006",
7, datetime(2022-03-01T15:30:00Z), "Phone", "SKU1002",
8, datetime(2022-03-02T16:00:00Z), "Laptop", "SKU1001",
9, datetime(2022-03-02T17:30:00Z), "Tablet", "SKU1003",
10, datetime(2022-03-02T18:00:00Z), "Desktop", "SKU1004",
11, datetime(2022-03-02T19:30:00Z), "Smartwatch", "SKU1005",
12, datetime(2022-03-02T20:00:00Z), "Earbuds", "SKU1006",
13, datetime(2022-03-02T21:30:00Z), "Laptop", "SKU1001",
14, datetime(2022-03-02T22:00:00Z), "Phone", "SKU1002",
15, datetime(2022-03-03T23:30:00Z), "Desktop", "SKU1004",
16, datetime(2022-03-03T00:00:00Z), "Tablet", "SKU1003",
17, datetime(2022-03-03T01:30:00Z), "Smartwatch", "SKU1005",
18, datetime(2022-03-03T02:00:00Z), "Earbuds", "SKU1006",
19, datetime(2022-03-03T03:30:00Z), "Phone", "SKU1002",
20, datetime(2022-03-03T04:00:00Z), "Laptop", "SKU1001",
21, datetime(2022-03-03T05:30:00Z), "Tablet", "SKU1003",
22, datetime(2022-03-03T06:00:00Z), "Desktop", "SKU1004",
23, datetime(2022-03-03T07:30:00Z), "Smartwatch", "SKU1005",
24, datetime(2022-03-03T08:00:00Z), "Earbuds", "SKU1006",
25, datetime(2022-03-03T09:30:00Z), "Virtual Reality Headset", "SKU100"
];
let device = datatable(DeviceCategory:string, SKU:string, Manufacturer:string, Model:string, ScreenSize:string, Weight:string)
[
"Laptop", "SKU1001", "Dell", "Latitude 5501", "15.6 inches", "3.5 lbs",
"Phone", "SKU1002", "Samsung", "Galaxy S21", "6.2 inches", "0.3 lbs",
"Tablet", "SKU1003", "Apple", "iPad Pro", "11 inches", "1.0 lbs",
"Desktop", "SKU1004", "HP", "EliteOne 800 G6", "27 inches", "25 lbs",
"Smartwatch", "SKU1005", "Fitbit", "Versa 3", "1.58 inches", "0.05 lbs",
"Earbuds", "SKU1006", "Apple", "AirPods Pro", "-", "0.19 lbs",
];
// [Query 1]
sales
| join kind=inner device on $left.Category == $right.DeviceCategory, SKU;
// [Query 2]
sales
| join kind=leftouter device on $left.Category == $right.DeviceCategory, SKU
| project SoldOn=TransactionDate, Category, Brand=Manufacturer, Name=Model;
// [Query 3]
sales
| summarize count() by Category;
// [Query 4]
sales
| summarize arg_min(TransactionDate, *) by Category, SKU;
// [Query 5]
sales
| join kind=inner (device) on SKU
| summarize count() by bin(TransactionDate, 1d), Model;
// [Query 6]
sales
| join kind=inner (device) on SKU
| summarize count() by bin(TransactionDate, 1d), Model
| render columnchart
以下、それぞれのクエリの解説とその結果
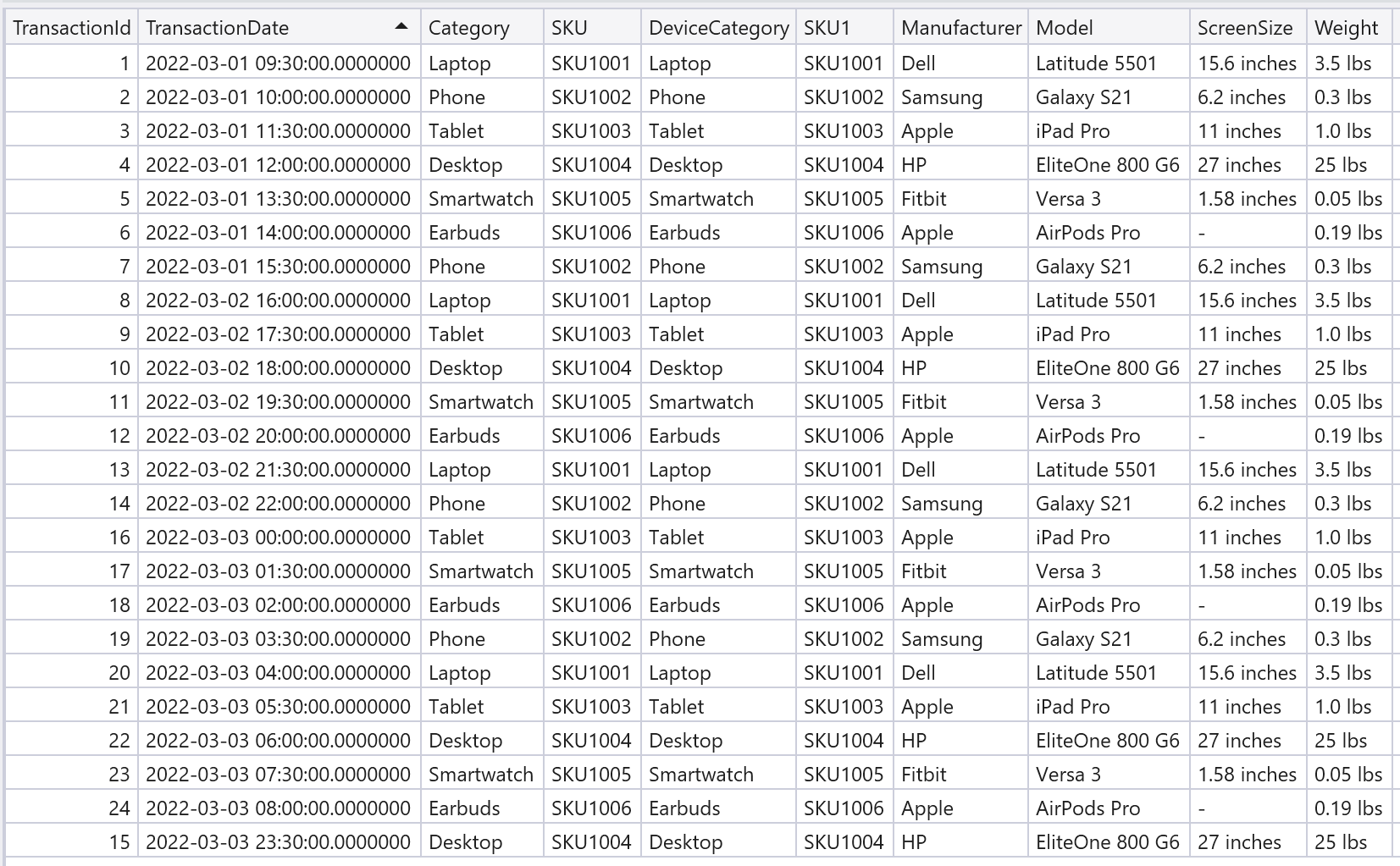
Query 1. inner join の例
左右のテーブルでJoinするカラム名が異なる場合を想定してます。
// [Query 1]
sales
| join kind=inner device on $left.Category == $right.DeviceCategory, SKU;
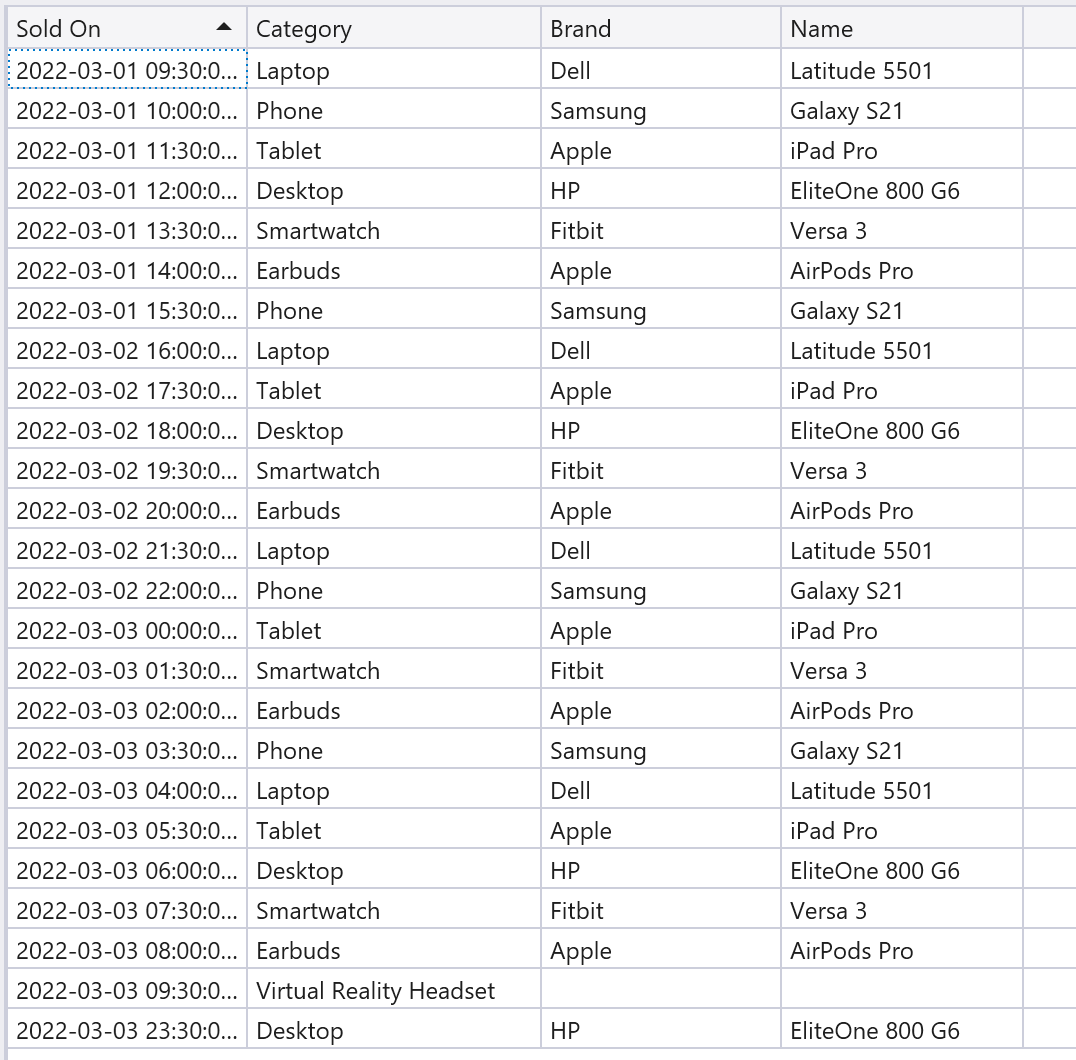
Query 2. leftouter join の例
結果にVirtual Reality Headset があるけれどdeviceテーブルに対応する行がないのでBrandとNameのデータが無いのが分かります。あとprojectで結果に含むカラムを絞っています。
// [Query 2]
sales
| join kind=leftouter device on $left.Category == $right.DeviceCategory, SKU
| project SoldOn=TransactionDate, Category, Brand=Manufacturer, Name=Model;
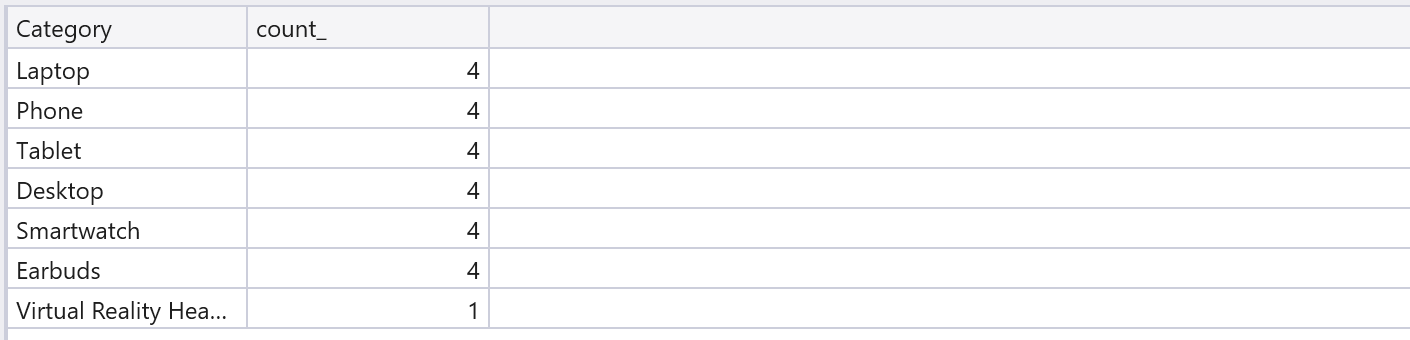
Query 3. カテゴリ毎の総数の例
典型的なcount()関数の使い方を示しています。
// [Query 3]
sales
| summarize count() by Category;
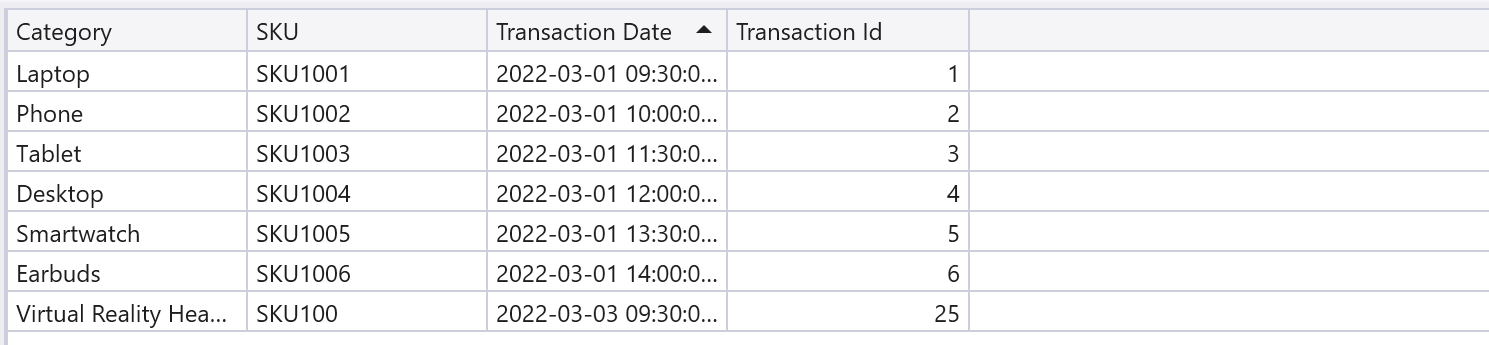
Query 4. 各デバイスが最初に売れた行だけ出力する例
arg_min()関数を使ってCategoryとSKUでグループ化した行のうち、TransactionDateが一番小さい(一番古い)ものだけを結果に含むようにしています。
// [Query 4]
sales
| summarize arg_min(TransactionDate, *) by Category, SKU;
Query 5. 1日ごとのデバイスの売り上げ数
bin()関数の典型的な利用方。Modelの代わりにManufacturerを使ったり、カラムのコンビネーションでグループ化も出来ます。
// [Query 5]
| join kind=inner (device) on SKU
| summarize count() by bin(TransactionDate, 1d), Model;
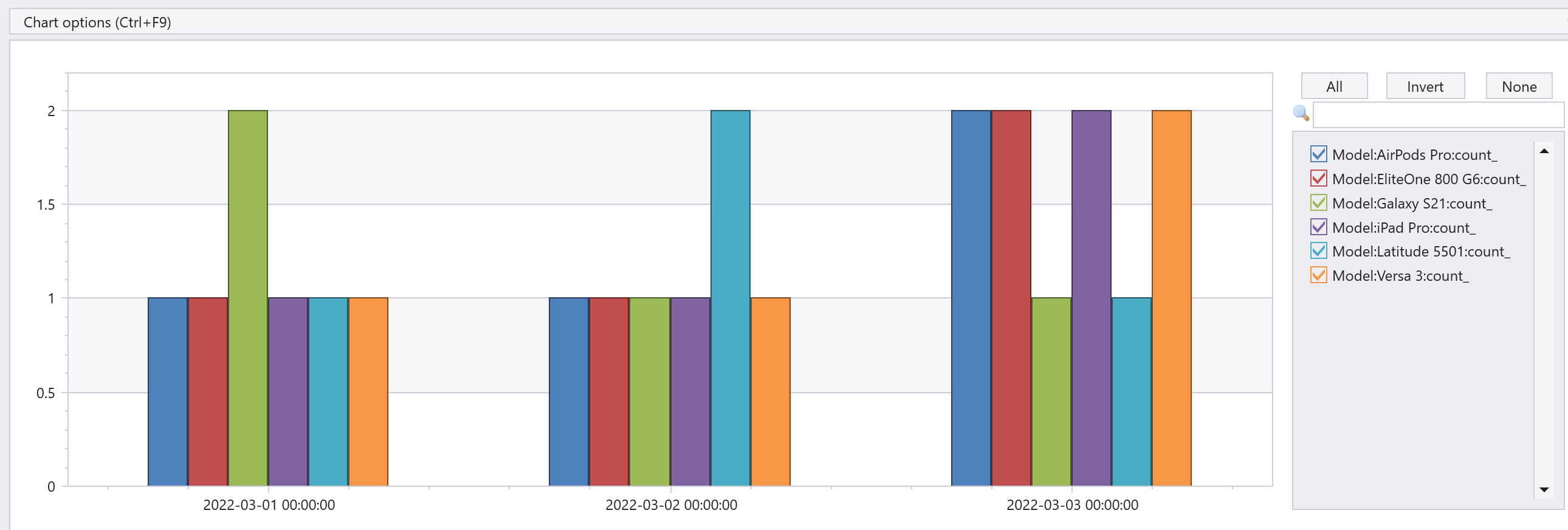
Query 6. 可視化の例
クエリは5と同じだけど、最後にrender columnchartを指定してグラフを生成しています。
パターンマッチング
let table1 = datatable(Name:string, Email:string)
[
"Alice", "alice@example.com",
"Bob", "bob@example.com",
"Cathy", "cathy@example.org",
"David", "david@example.net",
"Eva", "eva@example.com",
"Frank", "frank@example.org",
"Grace", "grace@example.net"
];
// Pattern Matching 1
table1
| where Email matches regex "@example\\.com$";
// Pattern Matching 2
table1
| where Email like "@example.com"
Pattern matching 1 正規表現の使用例
// Pattern Matching 1
table1
| where Email matches regex "@example\\.com$";

Pattern matching 1 like の使用例
全く同じ結果です。正規表現より扱いやすい。
// Pattern Matching 2
table1
| where Email like "@example.com"
Pattern mactching 3 has の使用例
もっともカジュアルに使えてパフォーマンスも良い。ほとんど場合これで済む。
datatable(Name:string, Description:string)
[
"Alice", "Alice loves playing basketball",
"Bob", "Bob enjoys reading books",
"Cathy", "Cathy likes swimming",
"David", "David is interested in art",
"Eva", "Eva loves cooking",
"Frank", "Frank likes hiking",
"Grace", "Grace is a fan of football"
]
| where Description has "loves"
データの抽出
文字列内の特定のパターンに当てはまるデータを抜き取る。
let table1 = datatable(Description:string)
[
"The product with ID 12345 has a price of $200.",
"Product 67890 is priced at $150.",
"ID 11121 has a price tag of $300."
];
// Data extraction 1
table1
| extend ProductID = extract("ID (\\d+)", 1, Description), Price = extract("\\$(\\d+)", 1, Description);
// Data extraction 2
table1
| parse Description with * "ID " ProductID:int " " * "$" Price:int *
Data extraction 1 正規表現の使用例
table1
| extend ProductID = extract("ID (\\d+)", 1, Description), Price = extract("\\$(\\d+)", 1, Description);

Data extraction 1 extract()関数の使用例
これも全く同じ結果ですし、やはり正規表現より扱いやすいかな。
// Data extraction 2
table1
| parse Description with * "ID " ProductID:int " " * "$" Price:int *
まとめ
初歩的な使用法より少しだけ高度な使い方をすぐに利用できるようにコピペしてすぐ実行出来るようにしました。