JJUG CCC 2023 の発表の時に紹介した、デモ・アプリの概要を下記にまとめます。
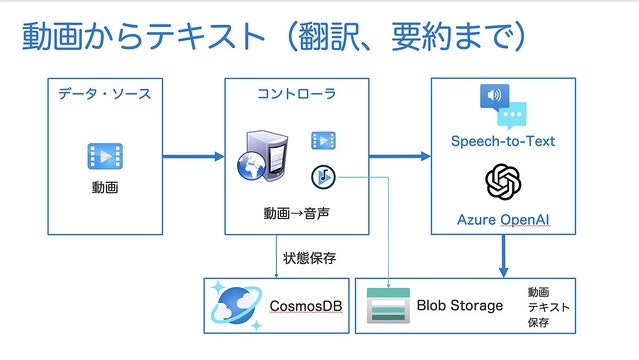
このアプリケーションは、主に自分のために作成したアプリです。なぜなら、英語が苦手で、YouTube 動画を見るよりも、その内容をテキスト化し、いつでもどこでも見られるようにしたかったためです。
しかし、このデモは実際のビジネスでも活用できる場面があります。
- 議事録の自動生成
- コールセンター分析
例えば、議事録の自動生成や、コールセンター分析などが可能です。Azure Cognitive の Speech to Text は、ファイルからだけでなく、リアルタイムで音声からテキストの生成もできます。そこでコールセンターの会話をテキスト化し、30 秒ごとに GPT-4 に送信して感情分析などもできます。また、音声データから議事録を簡単に作成する事もできます。
これ以外にも、この仕組みは、さまざまなアイデアで応用ができるのではないかと思います。
内部で利用した機能
このアプリケーションをお試して動かすためには、下記のコマンドやツールが必要です。
- Java 11 or 17
- Maven 3.6.3
- Azure Account
- Azure Cognitive Speech to Text Service : 音声・テキスト変換
- Azure Blob Storage : 結果の保存先 (動画・音声、JSON, Markdown)
- Azure Cosmos DB : 処理状況・状態情報の保存先
- Azure OpenAI : GPT-4 モデルが利用可能な Azure OpenAI インスタンス
- yt-dlp : YouTube の動画をダウンロードするためのツール
- ffmpeg : 音声フォーマット変換のために利用 (AAC -> MP3 の変換で利用)
- ffprobe : 動画の情報を取得するためのツール(ffmpeg から内部的に利用)
- Python 3.7+ : ffmpeg と ffprobe の実行に必要
備考: ソースコードは、現時点で諸事情により公開していません。
デモ用に急ぎ作ったため、ファイルのダウンロード、音声変換は外部ツールを使っています。
実行画面
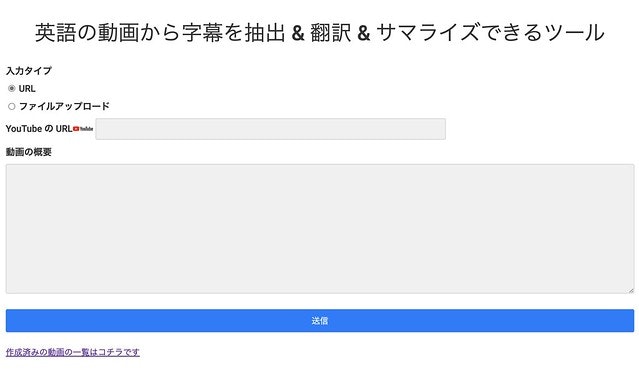
アプリを実行すると、動画ファイルを指定する画面が表示されます。
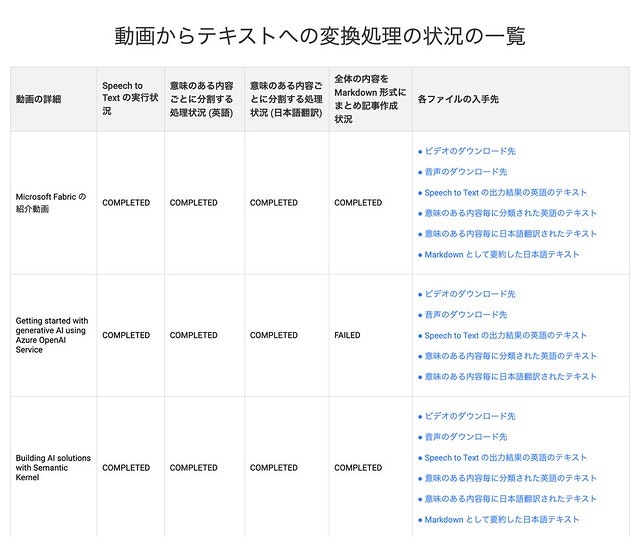
また、実行結果の一覧は下記の画面で確認できます。
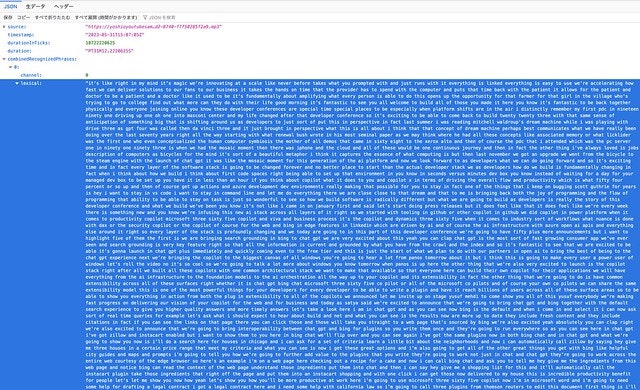
Speech to Text
Azure Cognitive Service の Speech to Text を利用し音声データをテキストに変換すると、JSONファイルが生成されます。
今回は、Azure Cognitive Speech to Text を使いましたが、OpenAI 社も同様の機能を作っているようですね。
* ご参考: OpenAI Speech to text (Beta)
意味のある塊ごとに JSON 配列に分割
上記の Speech to Text の実行結果は、文字の羅列になっているため、このままではとても理解しづらい状況です。
そこで上記のデータを元に、以降で Azure OpenAI ChatGPT-4 を利用して、意味のある単位に分割し、翻訳やサマリーを作成します。
まず、意味のある単位に分割します。実行結果は下記のような JSON を生成します。
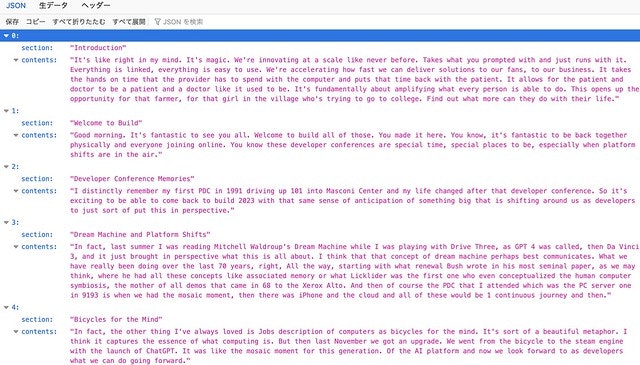
上記の、JSON を生成するために GPT に送信した問い合わせ内容は下記です。
- システムに事前設定したプロンプト
"I am a professional online news website editor.
I always strive to write easy-to-understand articles."
- 実際の命令プロンプト
"Please divide the above content into meaningful units
and replace the result in a JSON array.
Please output the divided content with section and contents."
意味のある塊ごとに 日本語に翻訳
次に、日本語翻訳をリクエストした結果、このような JSON 配列が生成されます。
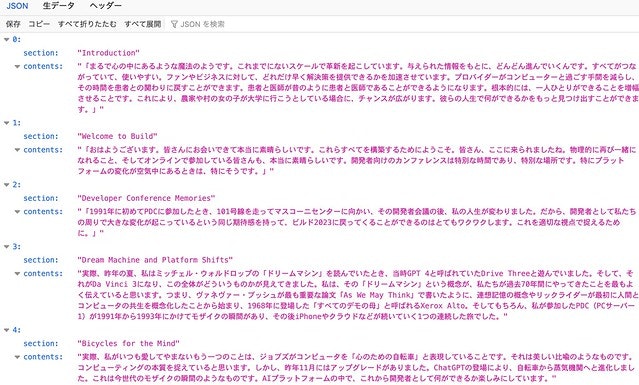
上記の翻訳を行うために、GPT に送信した問い合わせ内容は下記です。
- システム設定
"私はプロの翻訳家です。常にわかりやすい日本語で翻訳することを心がけています。"
- 実際の命令プロンプト
こちらの文章を日本語に翻訳してください
Markdown 形式でサマリーを作成した結果
最後に、まとめ記事を Markdown 形式として作成したのが、こちらです。

こちらを作成するために、GPT に送信した問い合わせ内容は下記です。
- システムプロンプト
"私はプロのオンライン・ニュース ウェブサイトの編集者です。
常にわかりやすい記事を書くことを心がけています。"
- アシスタント設定(ユーザ)
"こちらの内容を、ニュース・サイトに掲載するため、記事の内容にまとめてください。
出力形式は MarkDown 形式でお願いします。"
- アシスタント設定(アシスタント:返信例の設定)
# メイン・タイトル
## サブ・タイトル
内容
## 項目1
内容
## 項目2
内容
## まとめ
内容
実際の命令プロンプト
JSON 文字列の contents 部分から、ニュース・サイトに掲載するため、記事の内容にまとめてください。出力形式は MarkDown 形式でお願いします。
'内容'の部分の説明は 1000 文字で説明してください。
現在の課題
現在いくつかの課題があります。
-
このアプリケーションの実行にはとても時間がかかります。
- Speech to Text でテキスト化する部分で、音声データの長さに比例して時間がかかります。
- Azure OpenAI GPT-4 は、現在 Azure のプレビュー版として提供されており、世界中から非常に多くの利用リクエストをいただいています。その結果、1分当たりのリクエスト数が制限されており、制限を超えるとエラーになります。そこで GPT-4 へのリクエスト毎に 30秒のスリープを入れています。
補足:
Speech to Text は非常に負荷がかかる処理のため、自分の環境にハイエンドの CPU と Memory を搭載したマシンを用意し、コンテナ上で動かす事でパフォーマンスの改善ができるのではないかと想定しています。
ご参考:Docker で音声コンテナーをインストールして実行する -
現時点では処理は1つの動画ファイルに対して、1回実施していおり、並列実行に対応していません
並列化することで、処理時間を短縮することも将来的にはできるかと思いますが、現時点では、Azure OpenAI の GPT-4 インスタンスに対するリクエスト数の制限があるため、並列化すると、リクエスト数の制限を超えてしまいます。※リクエスト制限は、私が使用している社員用のアカウントでお客様が本番で利用する際は、リクエスト数の制限を取り除く事ができます