3. そのモデルにより残りのメールに対してプレアノテーションを実施し、その後に真面目にアノテーションする
前回からの続きです。
残りのメールをUploadします。そして、Annotation setを作成します。名前はSet2とします。残りの文書のUpload、Annotation setの作成までの処理は前章と同じです。これ以降、プレアノテーションのための作業となります。
Model Management - VersionsでRun this modelをクリックします。
Set2を選択してRunをクリックすると、プレアノテーションが実施されます。
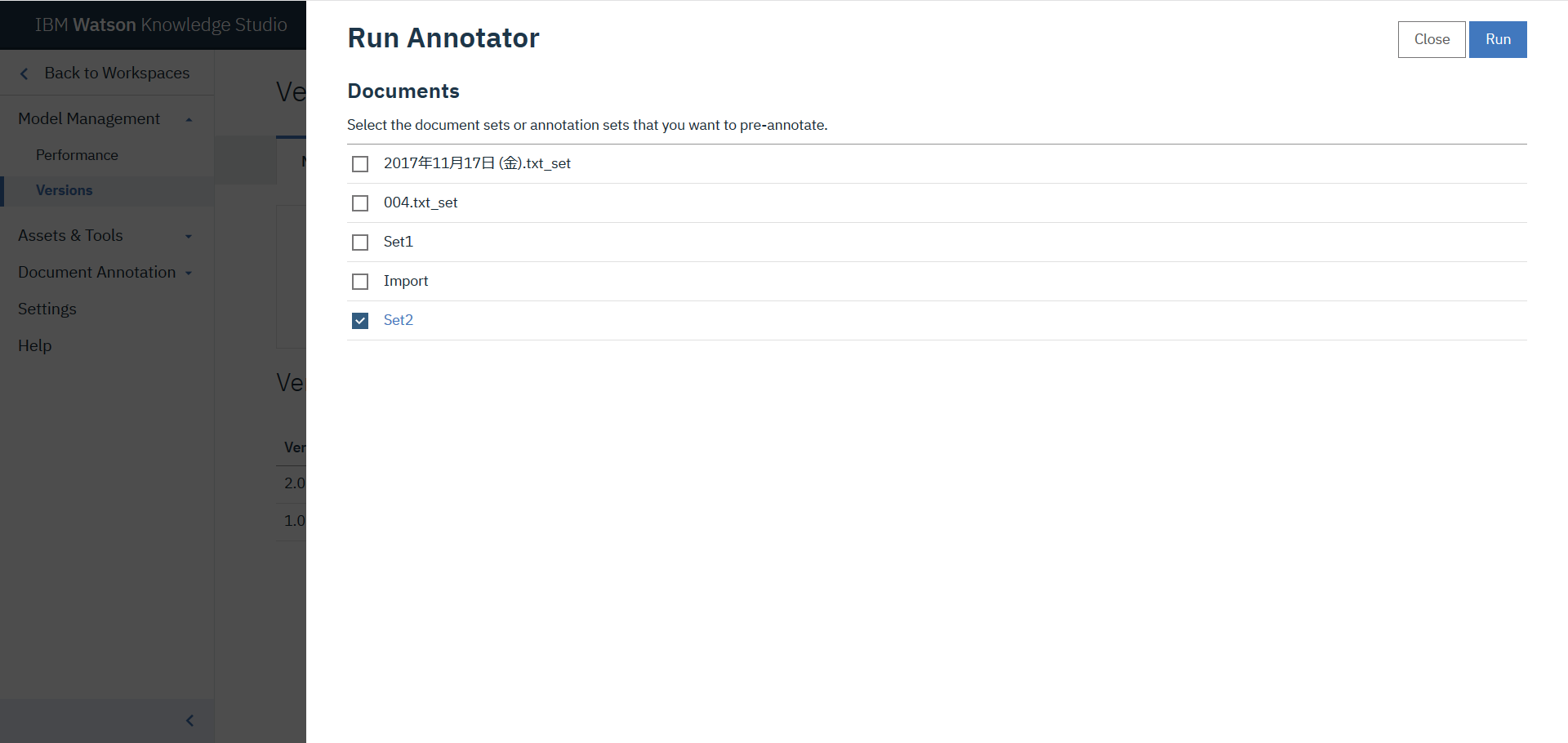
名前をSet2タスクとしてタスクを作成します。そして、アノテーションセットとして、Set2を選択します。この作業は前章と同じです。Documentを開くとプレアノテーションされていることが確認されます。アノテーション内容について確認し、必要に応じて削除や追加を行います。この画像では2017年10月31日(火)のうち、2017年10までしか選択されていませんので、残りの月31日(火)を含めるように変更する必要があります。前述のように、プレアノテーションの精度は最初に作成した機械学習モデルの精度に依存します。精度が低ければ、見当違いの単語がアノテーションされたり、必要な単語がアノテーションされなかったりする頻度が高くなります。それでも、無いよりはマシだとは思います。修正が完了したら、Submit all documentsをクリックしTrain and Evaluateの作業を開始します。これらの作業は前章と同じですので画像と説明は省略します。
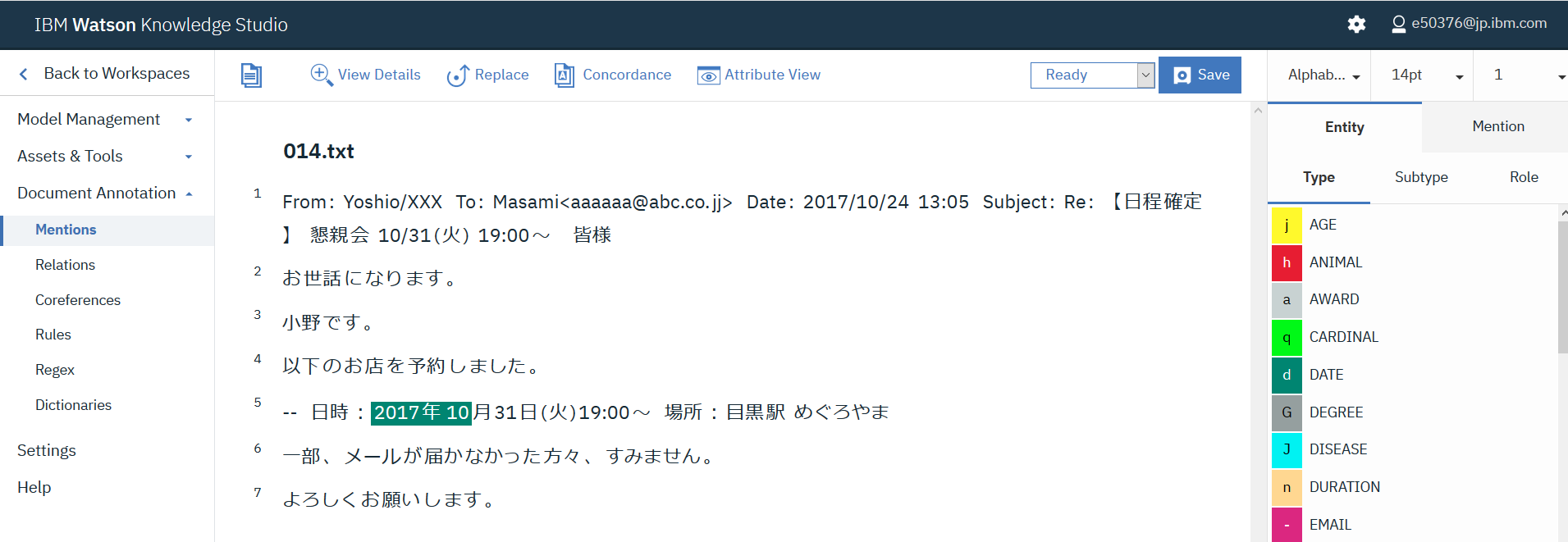
Train and evaluateではEdit settingを選択し、Set1とSet2を選択します。これにより準備したデータ全てを利用した機械学習モデルが作成されます。
これ以降の作業は前章と同じですので省略します。
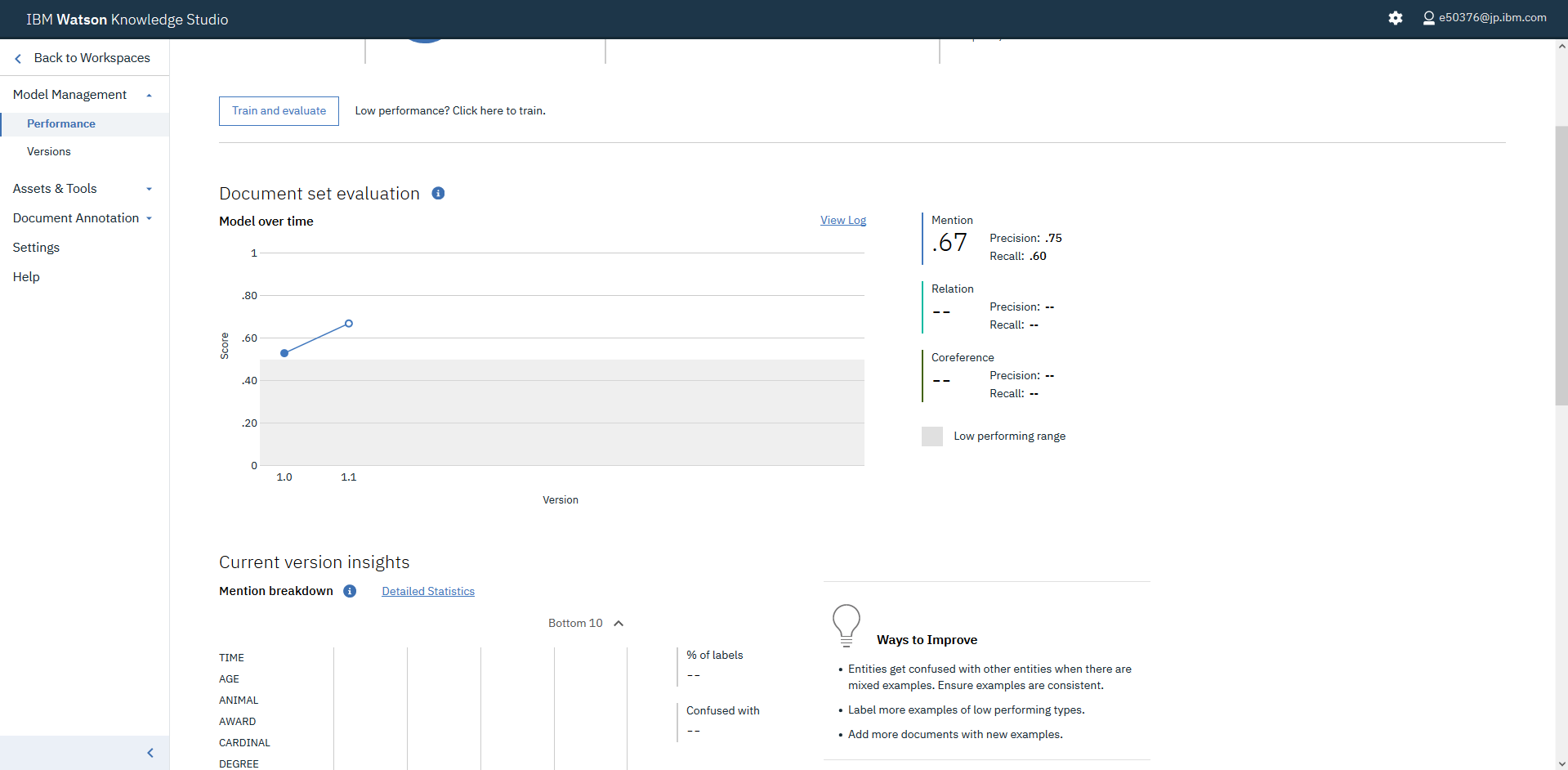
なお、ここでCurrent version insightsのDetailed Statisticsをクリックすることで、Confusion Matrixにアクセスできます。満足できるF1 scoreを達成するためには、それぞれの指標を改善する必要があり、その手順はこちらに記載されています。基本的には、アノテーションする単語数を増やす(ために、メールを追加して、アノテーションする)、Entity typeを見直す、等々となります。
また、F1 scoreを改善するためには、実際に、WKSで作成された機械学習モデルによって、どのようにアノテーションされるのだろうか?を知りたくなるかもしれません。その場合は、Train and evaluateのEdit settingの画面で、Training set 100%、Test set 100%、Blind set 100%の順でTrain and evaluateを繰り返すと、Human annotatorによるアノテーション(教師付きデータ)と機械学習モデルによるアノテーションを比較することが可能になります。
次に続きます。