概要
こちらのサイトを参考に試してみました
youtubeのデータをgpt_index(Llama_index)使って読み込みその動画で伝えたいことや登場人物を質問してみる
今後やってみたいこと
PDF、Wikipedia、Twitterなどをデータソースにしたチャットボットを作成
環境
googlecolab
前準備
OpenAIのAPIキー発行
参考URL
実装
pip install llama-index
import os
os.environ["OPENAI_API_KEY"] = "OpenAI_APIkeyを入力"
LlamaHubで「youtube_transcript」を選択
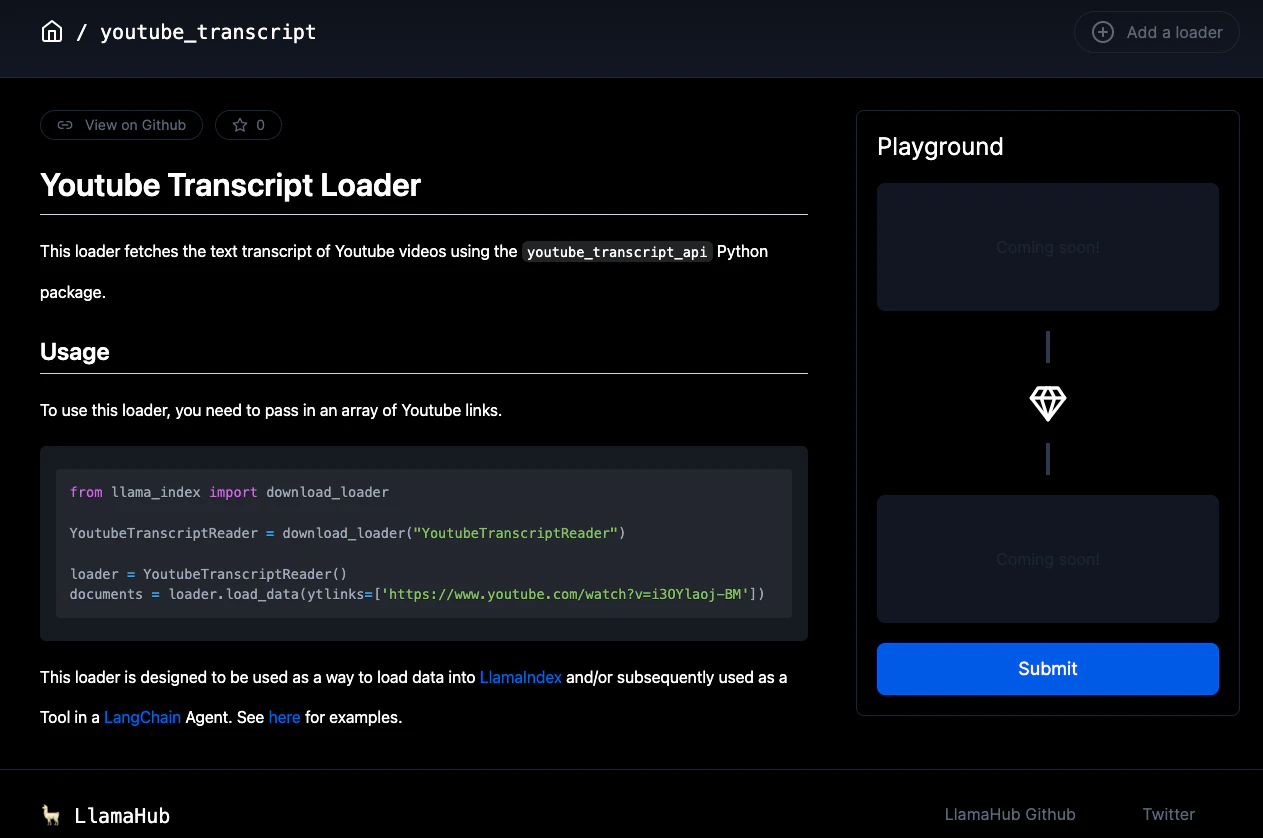
サンプルをコピー。入れたいデータのyoutubeリンクを入力する。
今回は桃太郎のyoutubeのURLを入力
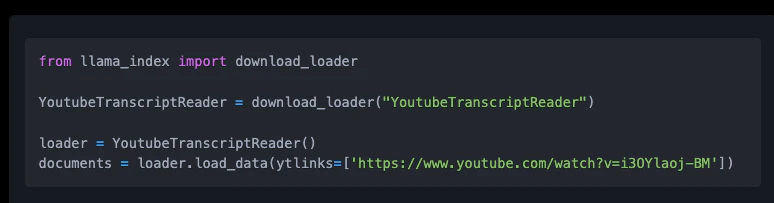
from llama_index import download_loader
YoutubeTranscriptReader = download_loader("YoutubeTranscriptReader")
loader = YoutubeTranscriptReader()
documents = loader.load_data(ytlinks=['https://www.youtube.com/watch?v=3k75rkB61Bk'])
#指定されたYouTube動画のトランスクリプトデータを読み込み、documentsという変数に格納
llama-indexパッケージからGPTSimpleVectorIndexとSimpleDirectoryReaderをインポート
GPTSimpleVectorIndexクラスを使用してインデックスを作成
from llama_index import GPTSimpleVectorIndex, SimpleDirectoryReader
index = GPTSimpleVectorIndex(documents)
質問応答
print(index.query("どんな物語?日本語で答えて"))
こちらの回答が返ってきた
この動画は、勇気と努力が報われるというメッセージを伝えようとしています。
print(index.query("桃太郎以外の登場人物を教えて?日本語で答えて"))
老夫婦、犬、猿、雉、悪魔将軍
悪魔将軍...