1はじめに
PyCaretは、Pythonのオープンソースの機械学習ライブラリです。
データの前処理、モデル(アルゴリズム)の比較、チューニングの自動化をしてくれます。
2 環境・バージョン
PyCaret 2.3.5
Google Colaboratory
3 PyCaretのインストール
!pip install pycaret
4 データセットの取得
from pycaret.regression import *
from pycaret.datasets import get_data
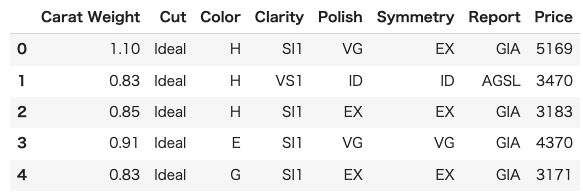
・Diamndのデータを取得
dataset = get_data('diamond')
5 集計対象を指定
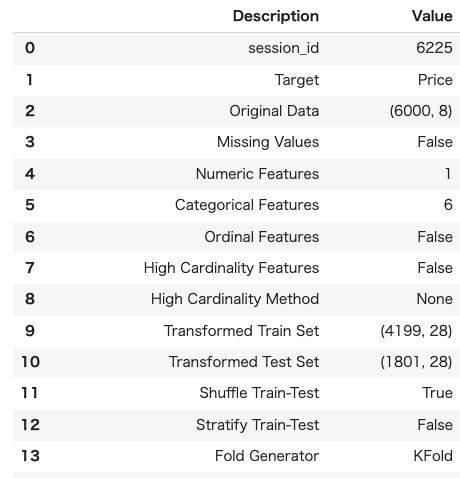
・集計対象をPriceに指定。
・項目のデータタイプがあっているかを確認して下に表示される四角い箱でEnter。
・この操作で前処理が自動でセットアップしてくれている。
・Priceの後ろに,をつけると設定情報が表示されて確認できる。
exp = setup(dataset,target='Price')
6 モデリングの比較をする
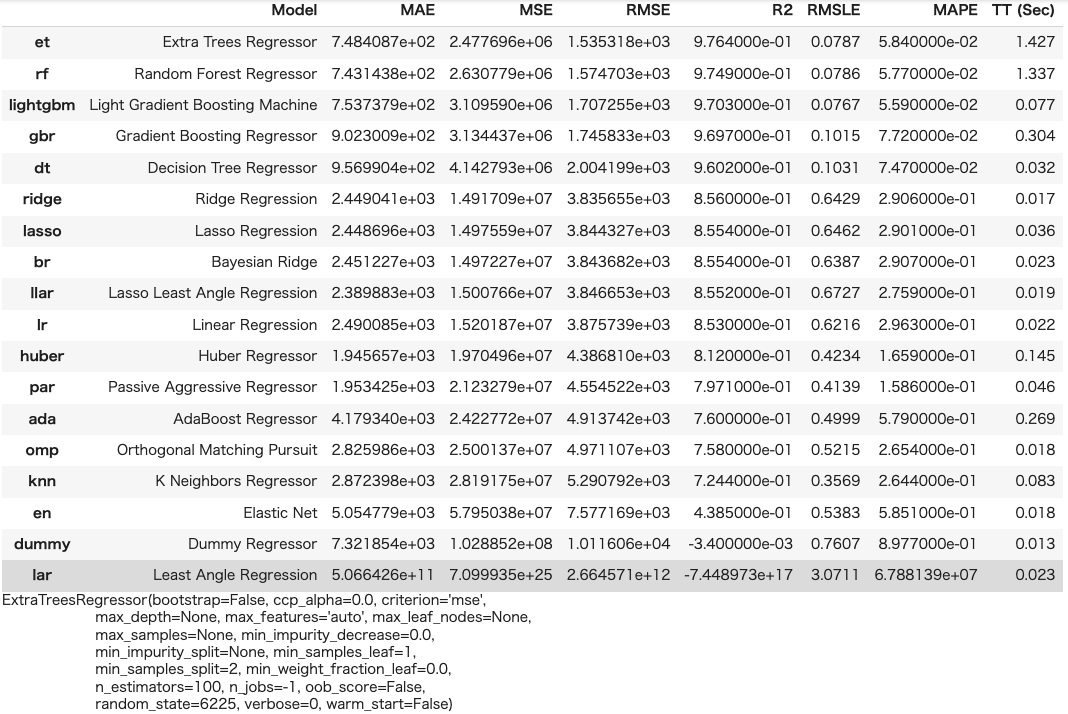
・モデリングのアルゴリズムを比較してくれる。
・R2 決定係数が高い順で並ぶ。今回は、Extra Trees Regressorが一番良い結果となった。
・一番下にExtra Trees Regressorのパラメーターが表示される。
compare_models()
7 モデルを指定する
model = create_model('et')
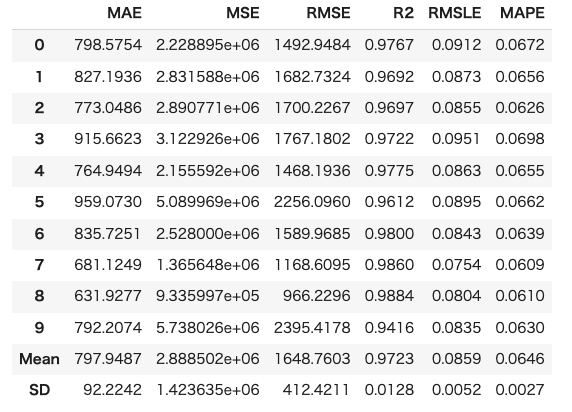
・交差検証(クロスバリデーション)を行なってくれる。
・それぞれの指標を試してみて平均の結果が出る。createを使うとクロスバリデーションを実行できる。
print(model)
print(model)でmodelのパラメーターが確認できる
8 ハイパーパラメーターのチューニング
・チューニングしたモデルをtuned_modelに入れる。
tuned_model=tune_model(model)
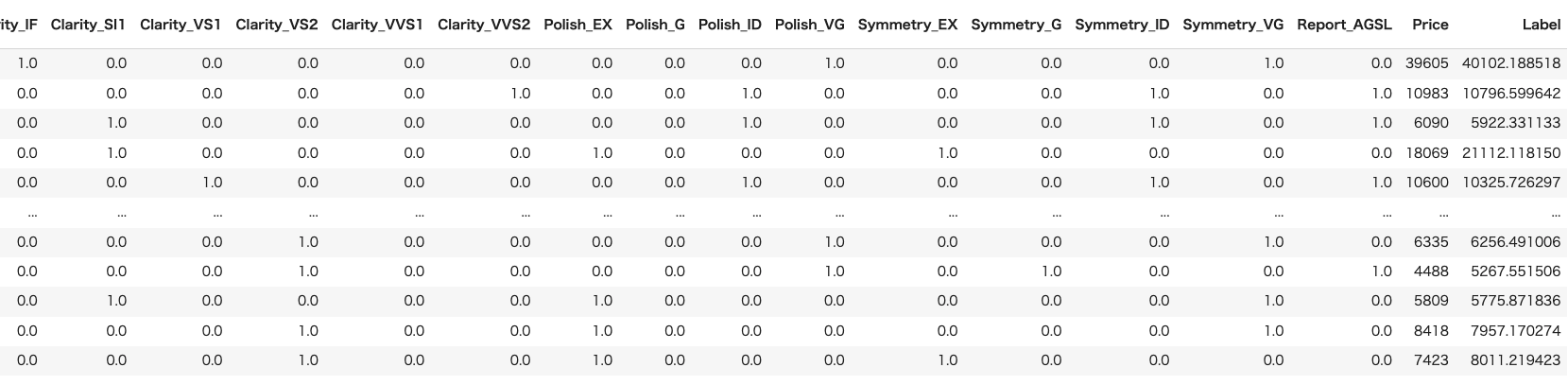
9 学習済みモデルで予測を行う
ここでは、6000行を7:3(1800行)で分けて入っていて実際のPriceに対してLabelがどれくらいずれているか確認する。このデータではおおむね価格を予想できていると言える。
predict_model(tuned_model)
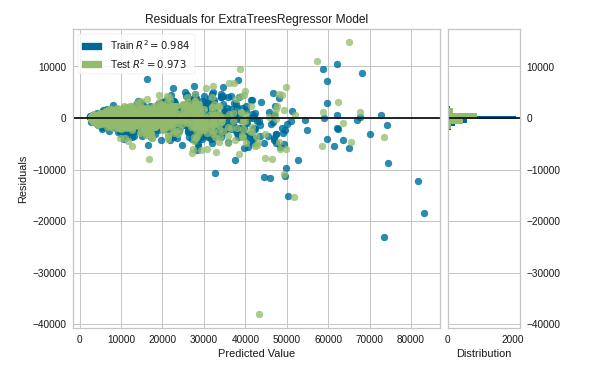
10 結果のプロット
実際の値からどれくらい離れているかの誤差について残差で表示される。0を中心にばらつきが少ない良い結果になっている。
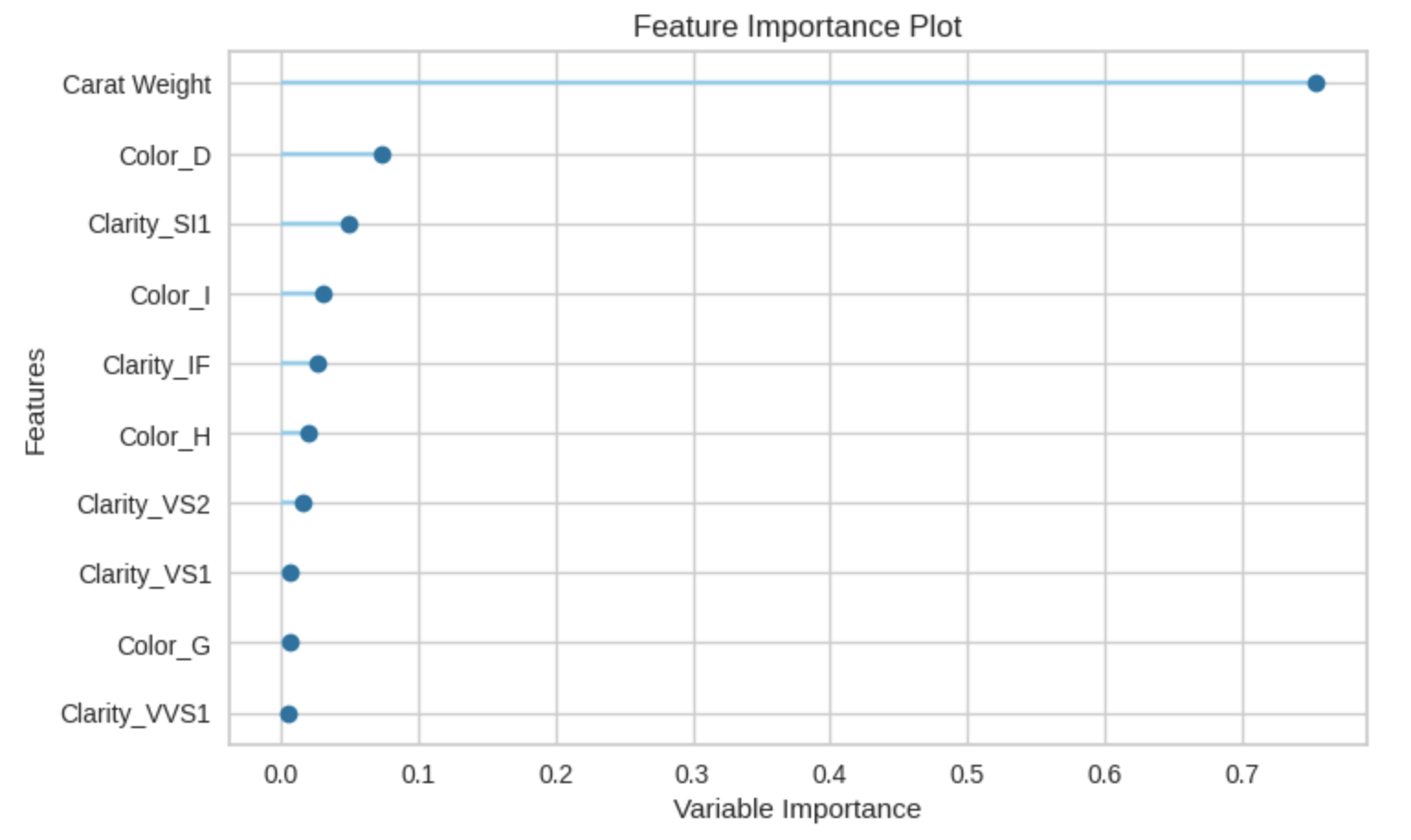
11 特徴量ごとの重要度をプロット
Carat Weightが一番重要度が高い結果となった。
plot_model(tuned_model, plot='feature')