QEMUのターゲットを追加してみた話
はじめまして、サイオステクノロジー佐藤嘉則です。
普段はLifeKeeperというHAクラスタのソフトウエアを開発していますが、それとは全く関係ないところでもひっそりと活動しております。
しばらく前からQEMUで何かやりたいなーということを年に一回くらい思って挫折していましたが、今年はその意欲がとても高くなってしまったため、夏休みの自由研究と称して始めたところ(8月だったのです)もう冬休みじゃないか?という頃になってようやく形になりました。
ということでその成果を簡単にまとめてみます。簡単なのでQEMUについて基本的な知識がある前提です。
やったこと
個人的に欲しかった機能として新しいターゲットCPUを追加してみました。
ソースはこのへんにあります
ターゲット
これです
CPUのバージョンがいくつかありますが、まずは一番基本的なv1の命令が動くことが目標です。
新しいターゲットCPUを追加するために以下の作業が必要です。
1.target/以下に対象CPUを追加
2.hw/以下に仮想ハードウエアを追加
全部書くと長くなるので今回は1の方だけです。
CPU class
CPUもハードウエアを構成する一つのデバイスであり、デバイスはQOMのクラスであるというお約束を守らないといけないので、CPUクラスを継承してターゲットCPUのクラスを作ります。
この辺はアーキテクチャ依存性はあまりないので、適当なアーキテクチャを切り貼りしてでっち上げることが出来ます。
CPURXState構造体
ざっと他CPUの定義を眺めた結果、CPU<なんとか>Stateという構造体でCPUの内部情報を保持していることがわかったので、CPUのマニュアルを読みつつ作ってみます。
必要なのは
- レジスタ(汎用・制御)
- エミュレータ内部で使う情報
です。
実際に出来上がったものはtarget/rx/cpu.hにあります。
Translate
CPUの中身を定義したので命令を解析するところにいきます。
target//translate.cがそれになりなす。
ここがTCGの実行ループから呼び出されてターゲット命令→ホスト命令に変換していきます。
まず、gen_intermediate_codeが呼ばれるので、ここからtranslator_loopを呼ぶとTranslatorOpsに登録した関数が適宜呼ばれて行きます。
TranslatorOpsには以下の関数を登録します。
| 名前 | 役目 |
|---|---|
| init_disas_context | 初期化します |
| tb_start | TranslationBlockの先頭でホスト命令を埋め込むことが出来ます |
| insn_start | ターゲット命令を変換する前にホスト命令を埋め込むことが出来ます |
| breakpoint_check | ブレイクポイントで止めるかどうか判定します |
| translate_insn | 一つのターゲット命令をホスト命令列に変換します |
| tb_stop | TranslationBlockの最後に命令を埋め込めます |
| disas_log | デバッグ用の統計情報を出力します |
まあ、breakpoint_checkとtranslate_insnを埋めれば大体のCPUは対応できるんじゃないかなと思います。
translate_insn
ということで一番面倒くさいところです。
ターゲット命令→ホスト命令てなにやればいいの?と思われるかもしれませんが、ターゲットの命令がどのように動作するかをホスト命令でひたすら書くだけです。
今回は命令のデコードがなかなかに面倒くさかったので、富豪的に65536エントリの配列で解析しています。
(256Kbyteならまあ許されるかなーと思ったんですが、64bitなので512KByteということに気がついたのはかなり後)
実際の変換処理
/* mov.[bwl] rs,dsp:[rd] / mov.[bwl] dsp:[rs],rd */
DEFINE_INSN(mov1_2)
{
TCGv mem;
int r1, r2, dsp, dir, sz;
insn >>= 16;
sz = (insn >> 12) & 3;
dsp = ((insn >> 6) & 0x1e) | ((insn >> 3) & 1);
dsp <<= sz;
r2 = insn & 7;
r1 = (insn >> 4) & 7;
dir = (insn >> 11) & 1;
mem = tcg_temp_local_new();
tcg_gen_addi_i32(mem, cpu_regs[r1], dsp);
rx_gen_ldst(sz, dir, cpu_regs[r2], mem);
tcg_temp_free(mem);
dc->pc += 2;
}
Cで書くとreg = *(reg+dsp);とか*(reg+dsp) = reg;になります。
最初の方でごちゃごちゃやってるのは、命令コードからレジスタの番号やサイズなどの付加情報を取り出しています。
memは一時的に使うレジスタで、メモリ側のアドレスを計算するために使っています。
cpu_regsはCPURXState構造体で定義したCPUレジスタをTCGから見えるようにしたものです。
TCGからC言語で定義した変数を直接アクセスすることは出来ず、事前にTCGv型というポインタのようなものを作成しておく必要があります。
tcg_gen_addi_i32がホスト命令を生成する関数で、名前の通りmem = cpu_regs[r1] + dspを計算します。
rx_gen_ldstは今回定義した関数で、メモリ←→レジスタのホスト命令を生成する関数です。
メモリアクセスの関数はサイズごとに分かれていていちいちswitch〜caseとか書くのが面倒なので専用に関数を定義しました。
関数にとして別の所でTCGに変換しても一個のTranslationBlockになるので、関数に分けてもオーバーヘッドはありません。
ホスト命令の定義はtcg/tcg-op.hにあります。アセンブラだと思えばなんとかなります。
一部命令は wiki.qemu.org に解説があります。
転送命令だけじゃつまらないので演算命令も
sbbというキャリ付きの減算です(add / subはすごい読みにくいので…)
static void rx_gen_sbb_i32(TCGv ret, TCGv arg1, TCGv arg2)
{
TCGv invc;
invc = tcg_temp_local_new();
gen_helper_psw_c(invc, cpu_env);
tcg_gen_xori_i32(invc, invc, 1);
tcg_gen_sub_i32(ret, arg1, arg2);
tcg_gen_sub_i32(ret, ret, invc);
UPDATE_ALITH_CCOP(RX_PSW_OP_SUB, arg1, arg2, ret);
tcg_temp_free(invc);
}
gen_helper_psw_cはキャリフラグの状態を取得する命令を生成します。
実際にはhelper_psw_cという関数がTranslateBlockを実行する時に呼び出されて、関数の戻り値がinvcに入ります。
CPUStateの定義を見ているとpsw_cに入っているのでは?という疑問が湧くかもしれませんが、いろいろな都合により単純には取り出せません。
その次はret = arg1 - arg2 - invcの計算をしているだけです。
その次のマクロはフラグを評価する用意をしてます。詳細は次に書きます。
分岐命令
これが若干特殊です。
DEFINE_INSN(jmpjsr)
{
int save, rd;
save = (insn >> 20) & 1;
rd = (insn >> 16) & 15;
if (save)
pc_save_stack(2, dc);
tcg_gen_mov_i32(cpu_pc, cpu_regs[rd]);
dc->base.is_jmp = DISAS_JUMP;
dc->pc += 2;
}
regのアドレスに分岐・サブルーチン呼び出しの定義です。
pcに分岐先のアドレスを設定してdc->base.is_jmp = DISAS_JUMPを設定すると、ここで一個のTranslationBlockが完結します。
PCを変更する可能性のある命令はすべてTranslationBlockを完結させる必要があります。
フラグの処理
高級言語でCPUのシミュレーションを書いた経験がある人はわかってもらえると思いますが、フラグの計算はものすごく重くなります。
しかも頑張って計算しても、その後に出てくる評価条件では使われないこともあります。
効率最重視のQEMUでそんなに重い処理を無駄に行うことは出来ないので、必要になるタイミングで遅延評価します(別にそうしないといけないわけではなく、本物のCPUと同じタイミングで計算することも出来ます)。
実際の方法としては、フラグを変化させる命令を再度実行できるような情報を保存しておいて、フラグの状態を参照する所でその情報から結果を計算します。
今回はUPDATE_ALITH_CCOPとUPDATE_LOGIC_CCOPというマクロで、再計算に必要な情報をenvに保存して、helper_psw_z / helper_psw_c / helper_psw_s / helper_psw_oという関数でその計算を行っています。
TCGv
TCGの命令で扱う値はTCGvという型になっている必要があります。数値はtcg_local_const32という関数でTCGvに変換してから使います。あとは〜i_i32 or 〜i_i64という命令の第二オペランドが数値を指定できるので、うまく使いましょう。
ヘルパ関数
TCG命令だけでは複雑な命令を書くとものすごく大変なので、適宜Cの関数を使ったほうがよいでしょう。
target//helper.h に定義を書いて、helper.c / op_helper.cあたりに実装すると、gen_helper_なんとかで呼び出すことが出来ます。
評価タイミング
translate_insnは普通のC言語なので当然ながら制御構造を使ってフローを色々操作することが出来ます。
が、実際に生成したホスト命令コードが実行されるのは全く別のタイミングです。
なので、うっかりC言語の方で式を評価してフローを制御するとよくわからない動作をすることになります。
実際にはTranslationBlockをまたがなければそれまでの状態は常に同じなので、確実にまたいでいないことを保証できれば大丈夫なはずですが、無駄に悩まないために条件式はtcg_brcondとか使って書いたほうが安全です。
デバッグ
ごりごり書いたTCGの命令列も立派なプログラムなので、当然ながらそれをデバッグしないといけない事態が発生します。
簡単なものであれば机上でどうにかなりますが、ちょっと複雑になると中間状態とか見るのが結構大変です。
私は試行錯誤の結果、ヘルパ関数でprintfデバッグするようになりました。
まとめ
とりあえずこれくらいでCPUコアの最低限必要な部分は実装できると思います。
実際に使うためにはもっと色々作る必要がありますが、全部書くとものすごく長くなるので続きは来年のAdvent Calendarで書きます。
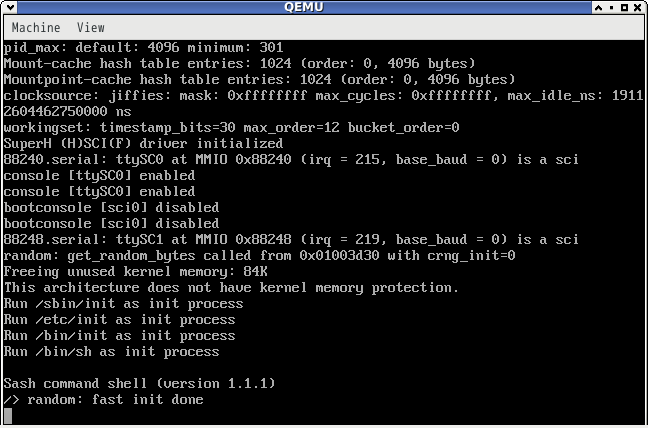
おまけ
これくらい動いてます