はじめに
今回SQL文のパフォーマンス改善をする仕事が降ってきた。
indexなど言葉は聞いたことがあるものの何もわからない。
とりあえず色々調べてみるか!ということでDBMSについて色々調べてみることにした。
まだよくわかっていない事が多々あるが、この記事にまとめた内容を知っていれば、
少なくとも少しはパフォーマンスを考えたクエリを書くことが出来るようになると思う。
※細かいところなど間違っている事が多くあるかもしれません。修正しますのでコメントしてください。
SQLが実行されるまで
ではまずSQL文がテーブルにアクセスするまでの流れを把握してみよう!
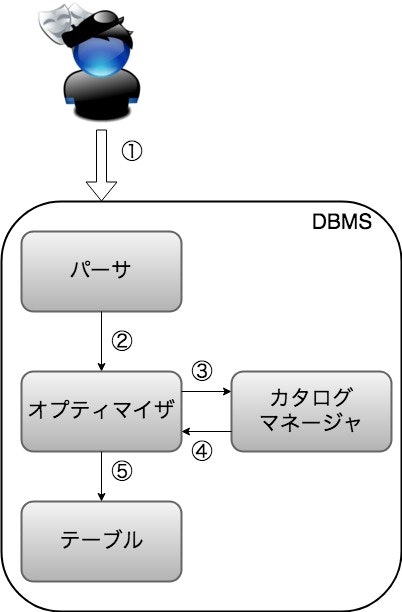
だいたいこんな感じの流れで実行される。
詳しくDBMSの中身をみてみると
①パーサではSQL文が正しく書かれているかチェックをしてくれる。
間違っていたらerrorとして返ってくる。
②パーサで構文に問題がないと判断されたらオプティマイザに行く。
ここがDBMSの頭脳と呼ばれているらしい!
ここでは統計情報を元に実行計画を立ててくれる。
③カタログマネージャに統計情報の要求をする
④オプティマイザに統計情報を渡す。
⑤オプティマイザが統計情報を元に最短でSQLを実行してくれる経路を選択した道(実行計画)を元に
テーブルにアクセスしてくれる。
ここでよくわからない単語が出てきたと思う。
統計情報と実行計画だ。
・統計情報とはSQLの最適なアクセス方法を決めるための情報のこと。
簡単にいうと車のカーナビのように、現在地からゴールまでの道のりを決めるための情報のこと
・実行計画とは統計情報を元に決まったSQLの最適なアクセス方法のこと
ということはだ、我々が書いたSQLはどんなデータが欲しいと条件を書いているだけで、
どんな方法でデータを取りに行けとは書いていないということだ。
そして実行計画を作成したオプティマイザはもしかしたら間違った道(実行計画)を教えてくるかもしれない。
だって統計情報が古かった場合は古い地図を元に道のりを教えてくれることと同じだからだ!!
統計情報は何から作られるのか?
以下が上げられる。(もちろん他にもあると思う。)
・各テーブルのレコード数
・各テーブルの列数と列のサイズ
・列値のカーディナリティ(値の個数)
・列値のデータ分布(どの値がいくつあるかのヒストグラム)
・列内のNULLの数
・インデックス情報
つまり現時点でSQLのパフォーマンスをよくするには
・統計情報の情報を常に最新の正しい情報にする事(※あえて統計情報を更新もせず、凍結させる場合もある)
・統計情報をもとに作られた実行計画を理解し、間違った道を教えていないか確認すること
・インデックス情報の正しい設定(統計情報の中でも一番重要?)
が重要だという事だ!!
まずはindex設計などの理解をしていくとしよう。
indexについて
どうも本の索引のような概念のものらしい。ただ日本語訳しただけだが、
何か調べる時に、日本語に直してみると案外ピンときたりする。
インタフェースなどもその流れで自分はピンときた!
(宣伝:https://qiita.com/yoshinori_hisakawa/items/cc094bef1caa011cb739)
話が逸れたが、indexの特徴を上げておくと以下のようなことがある。
・特定のデータがどこにあるかを教えてくれる
・DBとは関係ないのでデータの中身が影響を受けることはない
・正しく使うと劇的に性能改善をしてくれる
とりあえずわかったことはindexを使うことでSQLの性能が上がるということ。
以下のようにindexの種類もいろいろあるらしい(索引の仕方がいろいろあるのと同じように)
・B-Treeインデックス
・ビットマップインデックス
・ハッシュインデックス
indexがないとどうなるの?
本の索引がないということは、最初のページがすべてめくってお目当てのページにたどり着くまで、
探さないといけないという面倒なことになる。(シーケンシャルアクセスといったりする)
また、indexを設定していてもちゃんとつかえていない時は、シーケンシャルアクセスで探す羽目になるので、
出来るだけindexを使った探索をしたいということだ。
たまにindex効いてないなど聞くことがあるが、そいうことか!と思った。
それではインデックス設計について理解するために探索や計算量について理解を深めていく。
線形探索について
特定の値を探す方法について考えてみよう
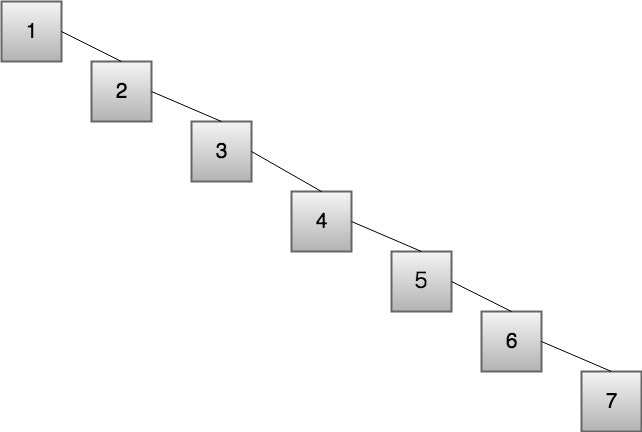
例えば5を探す場合は上から順に見ると1から進むので5回目に見つけることができる。
線形探索の計算量
計算量は一般的には最悪の場合について考えるので、線形探索は数列の長さがNの時に、最悪N回の探索が必要になる。これをO(N)と書く。
読み方は(オーダーエヌ)
二分探索木
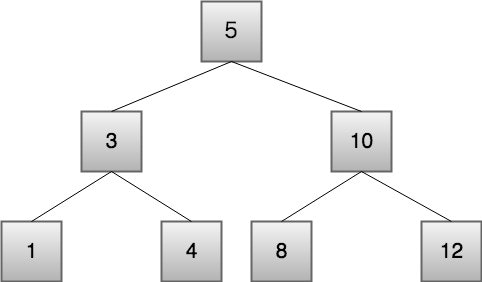
二分探索は検索する範囲を1/2に縮めながら探索をしていき、最悪の場合、探索範囲が1になるまで検索することになる。
つまり「入力される数列の長さN」を「2で割り続けて1になった時の割った回数」が「探索回数(t)」となる。
二分探索木の計算量
式で表すと
\frac{N}{2^{t}} = 1 \\
これをtについてとくと
t = \log_2 N \\
探索回数tが計算量となるので、O(log N)になる。
二分探索では入力Nが大きな数に増えていっても、計算量はO(log N)ですむため、線形探索とは違い性能があまり劣化しません。
例えばNが1024の時、線形探索の計算量は1024になるが、二分探索の計算量は10となる。
計算量がおおくなるにつれて、二分探索の方が性能の劣化がないことがわかる。
B-Treeインデックス
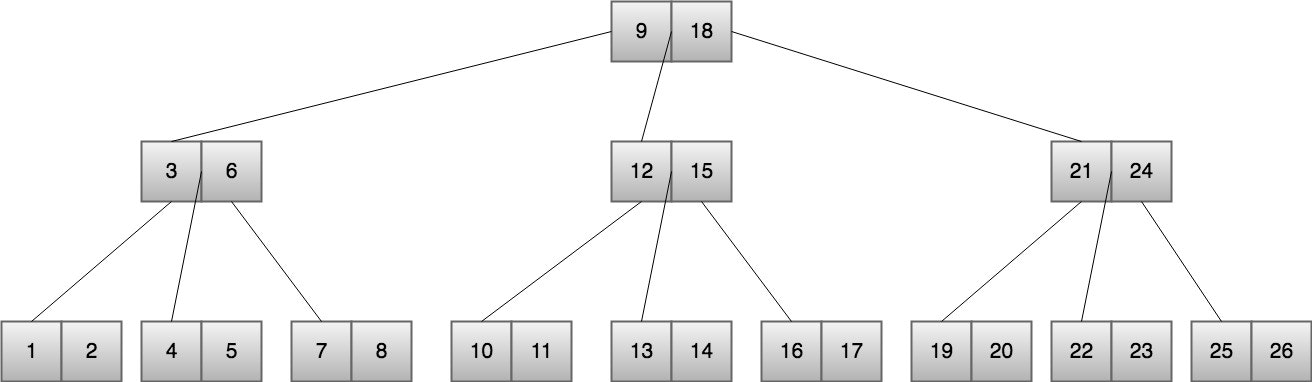
BTreeは二分探索木を変形したものらしい。
B-Treeは1つのノードがm個(m>=2)の子ノードを保持することができる。
m=2の場合が二分検索木。一般的にm個の子ノードを持つことが可能なBTreeを「m階のBTree」と呼ばれるらしい。
※ちなみに図のはm=3の場合。
各ノードは2個(m-1)の値を持ち、3個(m)の子ノードを持つ。
BTreeは探索する範囲を1/mに縮めながら探索をしていき、最悪の場合、探索範囲が1になるまで探索する。
つまり「入力される数列の長さN」を「mで割り続けて1になった時の割った回数」が「探索回数(t)」となる。
B-Treeインデックスの計算量
式で表すと
\frac{N}{m^{t}} = 1 \\
これをtについてとくと
t = \frac{log_2 N}{log_2 m} \\
これは二分探索木のlog N以下の計算量になることがわかる。
ビットマップインデックス
あまり深く知る必要がないので簡単に説明する。
データからビッドデータを作成してそれをインデックスとして使っている。
ビットデータのサイズが小さいなどの利点もあるが、インデックス更新するたびに、
全てのビットデータを更新するなど、デメリットもでかい。
いいところもあるが、更新性能がしょぼいくらいに覚えておく。
ハッシュインデックス
同様に深く知る必要はなし。
ハッシュ値をインデックスとして持つ。
ハッシュ値なので「=」で比較する際は一発で見つけてくれる。
ただ、それ以外の比較では線形探索と同じように地道に探すことになる。
なぜB-Treeインデックスが多くのDBMSで採用されているのか
3つのインデックス設計について説明してきたが、その中でもB-Treeインデックスが、
ほとんどのDBMSで採用されている。
ではなぜか、それはB-Treeインデックスは何かに秀ではいないが、全てにオールマイティだからだ。
これからオールマイティな理由を説明して行く。
・探索速度にバラツキがない
B-Treeの図をみてもらうとわかるが、平衡木になっている。
常にリーフ(一番下の値)までの距離が等しいからほとんど同じ計算量で対応できる
※更新とか削除が繰り返されることで平衡木が崩れるが一旦それは置いとく。
・データが増えてもパフォーマンスに影響が少ない
B-Treeのところで計算量を示したが、logなのでデータ量が増えてもそんなに大幅に値が増えることはない。
・挿入、更新、削除も探索と同様にlog(n)の計算量で行える。
これが結構大きい理由の一つにもなると思う。
ハッシュマップインデックスは検索は何よりも優れているが、更新に時間がかかりすぎる。
ビットマップインデックスもデータ量が変わることで全てのインデックスを振り直すため遅い。
その点B-Treeインデックスは、何に対してもオールマイティに行える。
・多くの範囲検索の条件にも対応できる。
検索の時に「where =」 とか「>,<」など使うことがあると思う。
B-Treeではある値よりも左か右かで絞ることができるため、多くの検索条件に対応できる。
・indexに指定したキーでソートした場合、大きな負荷がかからない
ここは大事なところなので詳しく説明して行く。
通常ソートはかなり負荷のかかる処理です。
ソートの種類を出して見ると
・集約関数(sum,cost,max...)
・order by句
・集合演算(union,except...)
・OLAP関数(rank,row_number...)
このソート処理をする時に、DBMSでは一時的にソートするためのメモリ領域を設ける。
もしメモリ領域に乗らなかったらディスクへデータを書き出すのでI/Oがすごくかかる。
しかしindexに指定したキーでソートをした場合は、上記のソート処理をせずにソートをすることができる。
これだけ知っているだけでも不要なソートを消すようなチューニングができたりする。
B-Treeインデックスとハードディスク
ハードディスクとの相性がいいらしい。
これは知っても知らなくてもどっちでも良さそうだからスキップ
もっと詳しく知りたい人は調べて見てください!
B-Treeインデックスのカーディナリティ
では今までインデックスが重要と話してきたが、どういった値にインデックスを付与すればいいか話して行く。
重要な指標がカーディナリティ。
カーディナリティとは特定の列がどのくらいの種類の値を持つのか?という概念のようなもの。
例えば性別の場合、「男、女、不明」なのでカーディナリティは3ということ。
そのカーディナリティの値が大きいものほどインデックスを振るのに適切な値と言える。
そして値に偏りがなく分散しているものほど良い。
ここまでがDBMSの中身の説明です。
ここから実際に実行計画を読み解き、どこに負荷がかかっているか、
どうすればその負荷を解決できるかを説明していきます。
実行計画を読み解く
疲れたのでここから先はいいねの数が多ければ書いていこうと思います。