はじめに
今回、AWSを利用し、スクラッチからプロダクトを立ち上げました。
記憶が新鮮なうちに、どのように考え、どのような構成にしたのかを残しておこうと思います。
シード期のスタートアップの方や、個人開発で規模の大きいものをゼロから作ろうとしている方の参考になれば嬉しいと思ってます。
前提の整理
どんなプロダクトか?
作成したプロダクトの概要としては
「顧客のwebアプリ上でサーベイを配信する」 ことが出来るプロダクトです。
もちろんただ配信するのではなく以下の機能などもあります。
- 高精度なユーザーの属性ターゲティング
- 適切なタイミングで配信するための行動ログターゲティング
- 広告配信システムのようなフリークエンシーなどの多数の機能
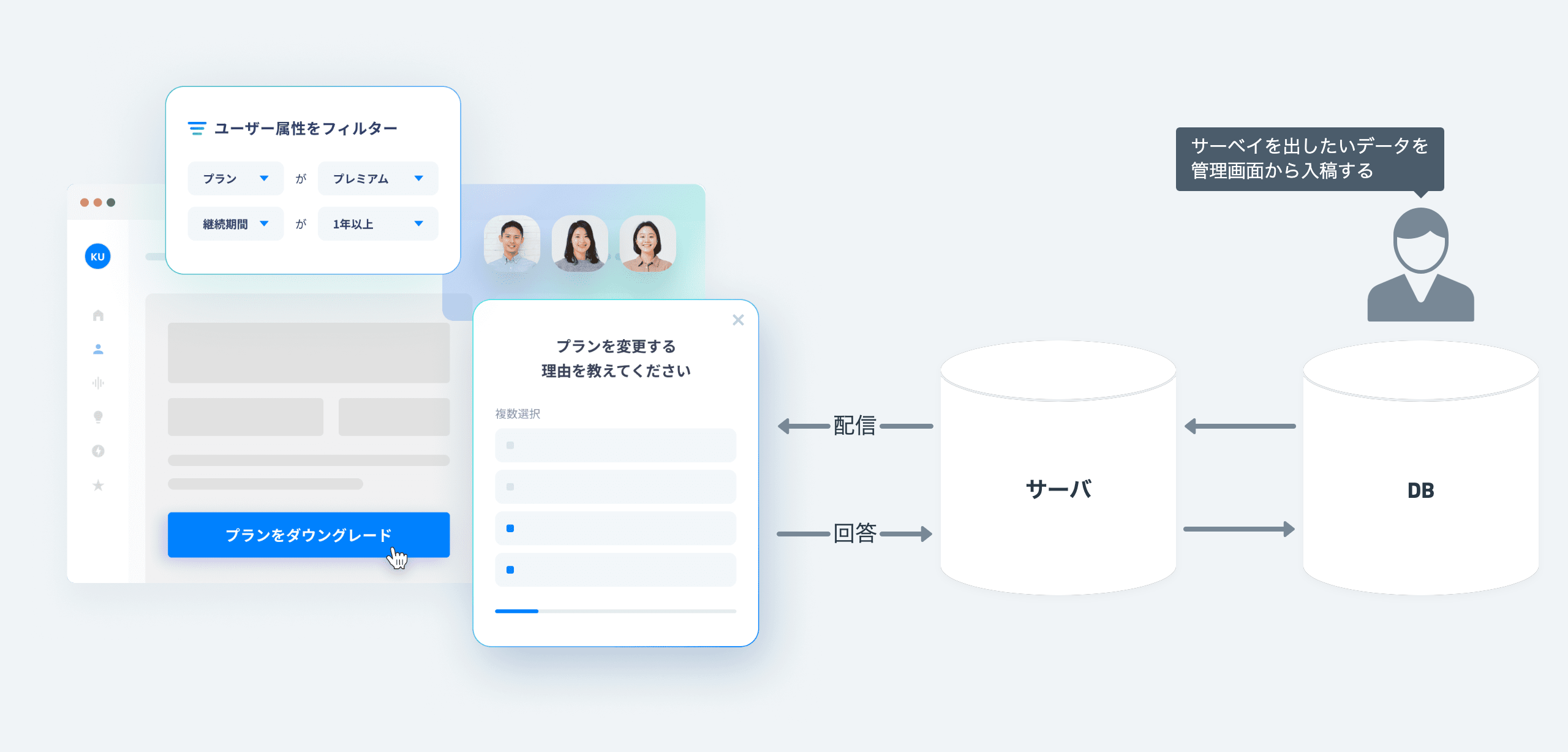
※ ざっくりイメージを捉えてもらえたらと思います
どんな要求を求められているのか?
ここでは、今回のインフラ構成に影響があるような重要な要求だけに留めておきます
- Javascriptを導入頂いた画面での、行動ログは全て取得するので非常に高いトラフィック量と大規模なデータを扱うことになります
- サーベイを同一ユーザーに何度も出すことは許されないのでリアルタイムな配信制御が必要です
- サーベイの回答が一定の時間に突発的に来たり負荷が予測しずらい状況でした
インフラ構成について
そこで今回構築したインフラ構成はこのようになっています。
なぜこのような構成にしているのかなどはこの後細かく説明していきます。
また、今回は説明用に多少インフラ構成をシンプルにしているので、実際に動いているものとは完全には異なりますが、
大部分は同様です。VPCやSubnet、WAF周りなどはもちろん対応していますがこちらも割愛してます。
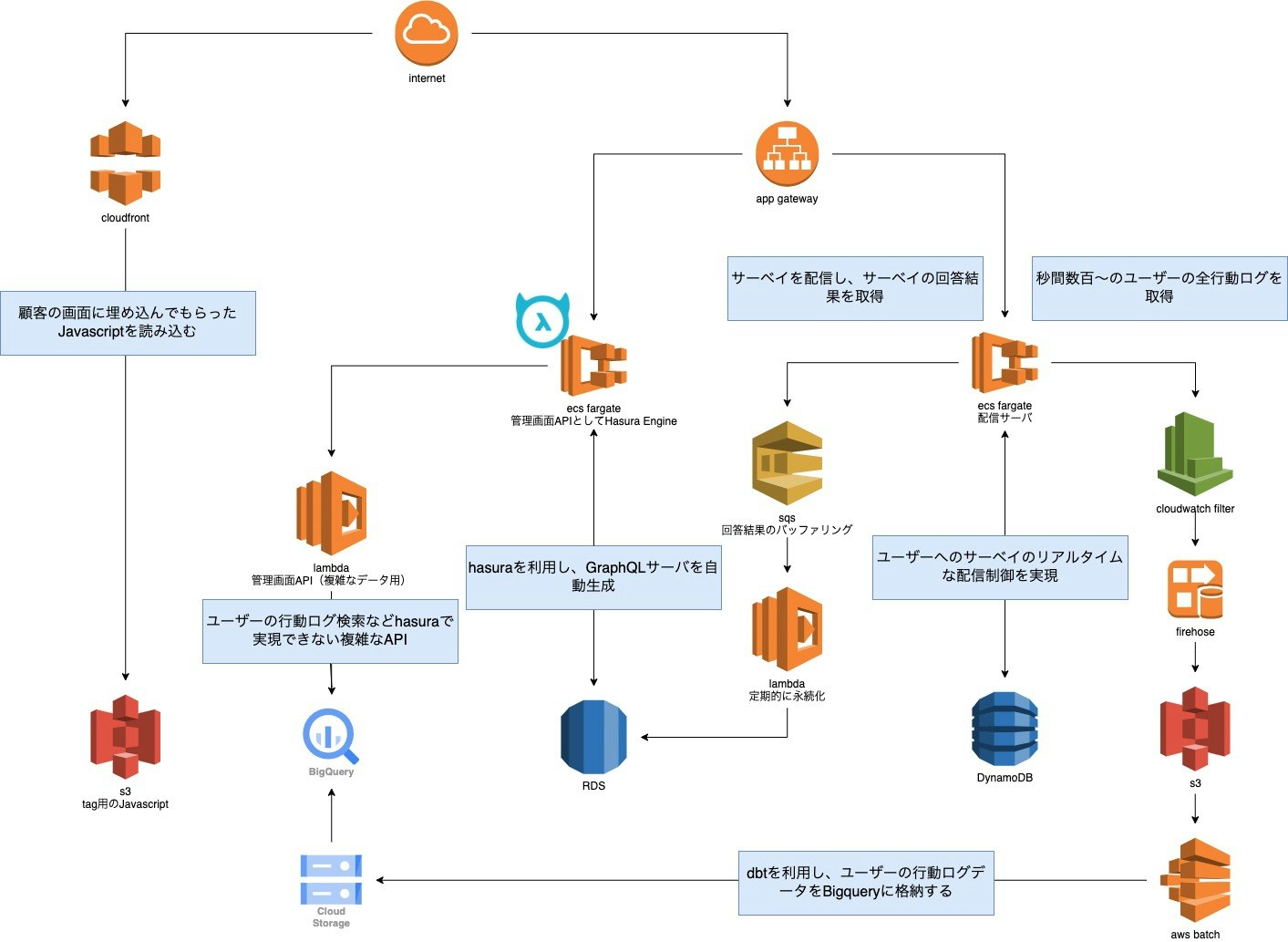
何を考えどう実現したか?
ここからが、本題になるかと思います。
実際にインフラを構成していく中で、扱うデータの性質によって構成がすごく左右された ように感じています。
事業上、絶対に欠損してはいけないデータや、実際妥協できるデータなどデータの扱い方次第で構成や、コストが大きく変わりました。
データについて
今回扱ったデータは以下の4つでした。
| リアルタイム性 | 量が多い | データの重要性 | |
|---|---|---|---|
| 1.サーベイの回答結果データ | ◯ | × | ◎ |
| 2.ユーザーの行動ログデータ | × | ◎ | × |
| 3.配信制御のためのデータ | ◎ | ◎ | × |
| 4.サーベイ情報のデータ | ◯ | × | ◯ |
1. サーベイの回答結果データ
ユーザーからのサーベイ回答結果は突発的に大量にくるし、絶対に欠損してはならない大切なデータでした。
1回答でも多く集まることで回答結果からインサイトに繋がる事業上、非常に重要度が高いものだからです。
なので、まずRDSがダウンしたとしても欠損せず、突発的に大量なサーベイ回答があっても影響なく捌けるような構成ということで、SQSでバッファリングさせることにしました。
こうすることで、RDSに何らかの問題があって書き込みが失敗してもDLQにデータは入りますし、リトライ処理もインフラレベルで行えるのでコードでの実装ミスなどもなくなります。また、突発的に大量に来たとしてもlambdaの同時実行数を1つにして直列にすることで、書き込み負荷は一定のものを担保することが出来ました。
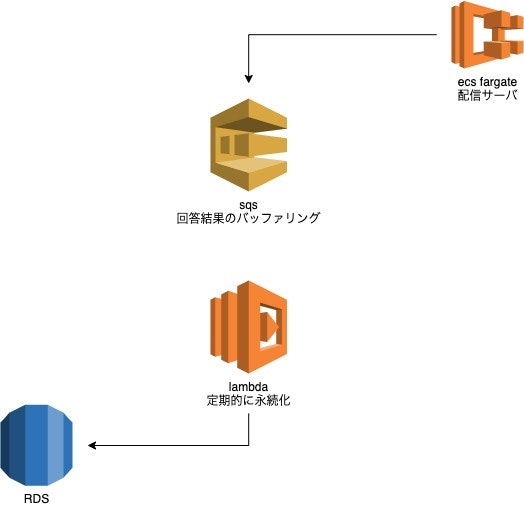
2. ユーザーの行動ログデータ
多少の欠損は許されるが、データ量が導入社数にもよりますが、秒間数百から数万と関数的に増えていくような性質のデータでした。
DBに都度書き込むのは、書き込みコストや負荷がエグいので、一番負荷の少ない方法でBigqueryにまで持っていくようにしました。
fluentdなども検討にあがりましたが、立ち上がりのスピードを重視し、awsでフィルタリングから全てを行うような構成にしました。
広告配信システムでのインプレッションなどを捌くやり方もこういった構成がよく取られているのではないかと思います。

3. 配信制御のためのデータ
ユーザーの回答結果や、サーベイをキャンセルしたときに発生するような、ユーザー体験に大きく影響するリアルタイム性の高いデータでした。
何度もサーベイが出てしまうとユーザーの体験を毀損するので、一度サーベイをキャンセルしたユーザーや、回答したユーザーには一定の期間再度サーベイを出すことを避けたいです。
高速(かつリアルタイム)にデータを取り出す順序としては
アプリケーション内キャッシュ > kvs > NoSQL > RDB
の順に良さそうだと思い、キャッシュだとサーバがスケーリングした際に同期できないので、二番手のKVSとしてDyanmoDBを利用しました。
プロダクトの初期フェーズで負荷の予測ができなかったため、オンデマンドモードで利用しています。
今回はインフラ構成がメインのトピックなので割愛しますが、DynamoDBのデータ構成やコストにはかなりテコづりました。
一番インフラコストにヒットする箇所で、わかりずらい箇所だったかと思います。これはまた別の記事で

コストと立ち上がりスピード
初期フェーズでお金をかけすぎることはできないと思いつつも、
立ち上がりスピードを基本的に優先するために、以下のことは常に意識していました。
- バグを減らすためにコード量を減らす
- 外部サービスで代替できるものは利用する
1. バグを減らすためにコード量を減らす
単純な話ですが、人間が書いたコードが増えれば増えるほど、
バグも増えると思いますし、テストの考慮や、コードを書くための時間も消費すると思います。
なので、出来るだけコードは書かないために、インフラ側でできることは寄せるようにしていました。
今回で言うと、SQSを多く利用することで、リトライ処理などを任せたり、Cloudwatch filterやkinesisを使いログの集計集計をインフラに寄せました。
2. 外部サービスで代替できるものは利用する
今回初めてでしたが、採用して良かったなと思うのは、管理画面のAPIサーバとして利用したhasuraです。
https://hasura.io/
こちらにHasuraを実際に使ってみてどうだったかはまとめています。
これは、RDSと繋ぐことで、GrapQL用のAPIサーバを自動生成してくれるサービスです。
これによって、管理画面用のAPIサーバの構築はゼロコードで実現できました。hasuraについてはまた別の記事で
運用方法や実際に良かった困ったことなどまとめられたらと思います。
最後に
2ヶ月程度でインフラからバックエンドや、全体のマネジメントをしながら
プロダクトをベータ版まで持っていけたことは、非常に疲れましたがすごく学びも多く楽しい開発でした。
興味のある方は、コメントやメールを頂けると幸いです。