背景とモチベーション
もともとこれを作ろうと思ったきっかけ。
- 方々からダウンロードしてきた論文のPDFがドライブにたまってしまった
- 一つ一つPDFの中身を開いて中身を確認するのが面倒
- 英語だと斜め読みに時間がかかる
- ChatPDFを使っても良いが、一つ一つ放り込むのが面倒
一方で、LangChainを使ってPDFを読み込ませてインタラクティブにQAできるコードと解説がYoutubeで公開されているのを見つけたので、それを参考に作ってみようと思った。
必要なもの
- Googleアカウント(Google Colab上で動かすことを想定)
- OpenAI APIキー(有償です)
- Googleドライブ上に保存されたPDFファイル
準備
Googleドライブのマイドライブの直下に「pdf」というフォルダを作り、そこにサマリーを作りたいPDFファイルを置く。
下のスクショはサンプルとして4つのPDFファイルを置いた様子。
コード
Google Colab上で、以下のコードを順番に実行していく。
パッケージのインストールには数分かかる。
# 必要なパッケージのインストール
!pip install langchain openai pypdf chromadb tiktoken gspread
次に、必要なライブラリのインポートを行う。
# ライブラリのインポート
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
import os
"**********"のところに取得したOpenAI APIキーを入れる。
# OPENAI_API_KEYを設定
os.environ["OPENAI_API_KEY"] = "**********"
GPTに文章を作成したもらうためのプロンプトの部分。
# クエリーの設定
query = """与えられた文章を以下のフォーマットで日本語で出力してください。```
・概要
・技術的なハイライト
・ハイライト1
・ハイライト2
・ハイライト3
・分類キーワード
・キーワード1
・キーワード2
・キーワード3
```"""
PDFファイルを置いている場所をpathに指定。
MyDrive/pdf/配下のサブフォルダにあるPDFも対象となるようにしてある。
「このノートブックに Google ドライブのファイルへのアクセスを許可しますか?」という確認のダイアログが出るので「Googleドライブに接続」を押し、次にアカウントを選択したうえで、許可する。
ドライブのマウントに数十秒かかることがある。
# PDFファイルの読み込み
from google.colab import drive
drive.mount('/content/gdrive/')
path = '/content/gdrive/MyDrive/pdf/'
import glob
files = glob.glob(path + '**/*.pdf', recursive=True)
ここが肝心なところ。
PDFファイルを順番に読み込んで、適当な長さに分割したうえでGPTに与えて、クエリーに対する回答を得る。現状、GPTのモデルはgpt-3.5-turboを指定。
PDFひとつあたり、数十秒程度の時間がかかるので、しばらく待つ。
途中「WARNING:chromadb:Using embedded DuckDB without persistence」というメッセージがでるが、実害は無いようなので気にしないでおく。
# GPTによる文章の作成
data_table = []
for file in files:
data_record = []
print(file.split("/")[-1].strip(".pdf"))
data_record.append(file.split("/")[-1])
loader = PyPDFLoader(file)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(texts, embeddings)
qa = RetrievalQA.from_chain_type(llm=ChatOpenAI(model_name="gpt-3.5-turbo"), chain_type="stuff", retriever=vectordb.as_retriever())
answer = qa.run(query)
data_record.append(answer)
data_table.append(data_record)
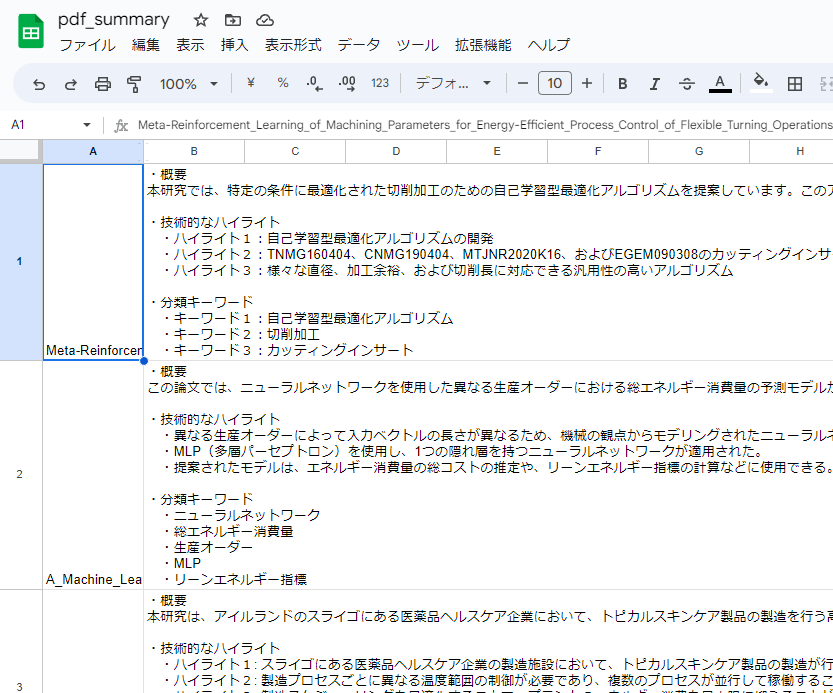
保持した回答の内容をGoogleスプレッドシートに書き出す。
「Google 認証情報へのアクセスをこのノートブックに許可しますか?」と確認のダイアログがでるので許可する。
Googleドライブのマイドライブ直下にpdf_summaryという名前のファイルができる。
# 認証のためのコード
from google.colab import auth
auth.authenticate_user()
import gspread
from google.auth import default
creds, _ = default()
gc = gspread.authorize(creds)
# スプレッドシートへの書き出し
filename = "pdf_summary"
ss = gc.create(filename)
ss.values_append("シート1", {"valueInputOption": "USER_ENTERED"}, {"values": data_table})
以下が出力されたスプレッドシートの様子。
注意
OpenAI APIを叩くのでお金がかかる。
試しに50本の論文で試したところ、缶コーヒー一本分程度の費用。
参考にしたサイト
非常にわかりやすくまとまっている動画です。肝心なところはほぼ丸々使わせてもらいました。
https://www.youtube.com/watch?v=eCtHVmXcXMs
今後に向けて
今回はとりあえずやりたいことに対して最低限動くものを作ったレベル。こんなことができるとより便利になりそうという案を以下にまとめた。
- PDF以外のオフィス系の文章、画像、動画ファイルへの対応
- ドライブにファイルが保存されたら、それを検知して自動で走る
- 関連する論文をクロールする