TL;DR
株式会社Scalarが開発している分散トランザクションマネージャScalar DBを使ってトランザクション処理を行うAPIを作りました。
その中で学んだScalar DBの特徴やScalar DBを使ったAPIの開発手法について説明していこうと思います。
長くなりますので3回に分けて投稿します。
- Spring BootとScalar DBを用いたAPIの作り方①(本記事)
- Spring BootとScalar DBを用いたAPIの作り方②
- Spring BootとScalar DBを用いたAPIの作り方③
完成したプロジェクトはGitHubに公開してあります。
目次
- Spring Boot で Scalar DB を使う理由
- Spring BootにおけるAPIアーキテクチャと各レイヤーの役割
- サンプルアプリケーションの概要
- データモデルの設計
- エンドポイントの設計
- Spring BootでのScalar DBの導入方法
Spring Boot で Scalar DB を使う理由
Scalar DB の概要
Scalar DBは、ACID準拠でないデータベースに対して、ACID準拠のトランザクションを可能にするトランザクションマネージャです。
Scalar DBは下の図のように、Storage Abstraction LayerとStorage AdaptersによってStorageとして利用するデータベースへのアクセスを抽象化しているため、Scalar DB を利用するアプリケーションはストレージとして利用するデータベースの違いを意識せず、同じプログラムで様々なデータベースが利用できます。
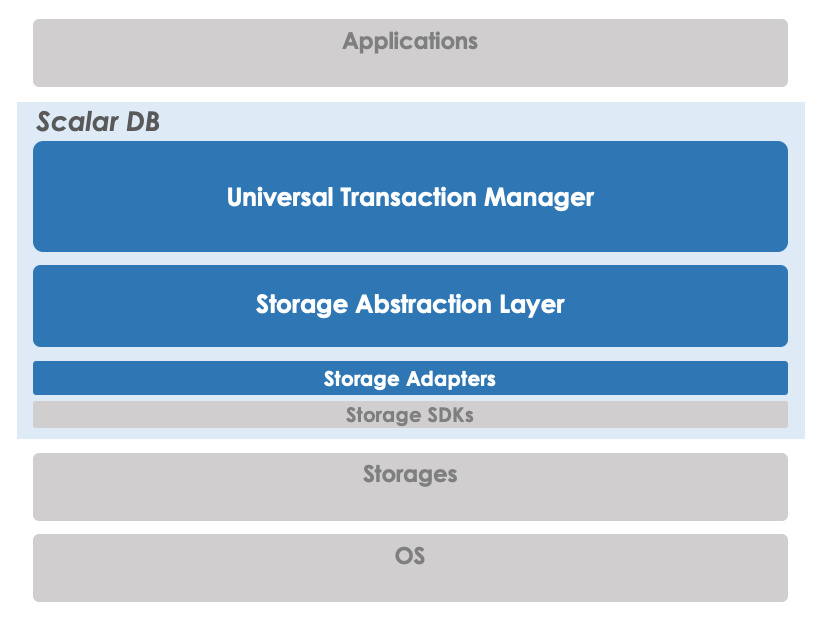
Scalar DB では、複数の異なるデータベースでも、1つのデータベースとして扱うことができます。このため、同じプログラムで、複数の異なるデータベースに対するACIDトランザクション処理が行えます。
現在対応しているデータベースはCassandra、Cosmos DB、DynamoDB、MySQL、PostgreSQLになります。
詳しい説明は公式ドキュメントをどうぞ
Scalar DBを使うメリット
Spring Bootでは@Transactionアノテーションを付与してトランザクション処理を実装することが多いと思います。
Scalar DB を使ったトランザクションの実装を行うと次のような利点があります。
- データベースの種類にかかわらず、トランザクション分離レベルを Strict Serializable にできる
- 異なるデータベース/ストレージでも同じコードで実装できる
- 別々の、あるいは異なるデータベース間でも、同じインターフェイスで、同じ分離レベルで実装することができる。
データベースの種類にかかわらず、トランザクション分離レベルを Strict Serializable にできる
@Transactionアノテーションによってトランザクションを実装する場合、トランザクション分離レベルは利用するデータベース/ストレージに依存します。
一方、Scalar DBはトランザクション分離レベルがRead Committed Snapshot Isolationに設定されており、最大でStrict Serializableの分離レベルまで設定可能です。
そのため、Serializable サポートが限定的なデータベースでも対応することができます。
異なるデータベース/ストレージでも同じコードで実装できる
上述したように、Scalar DBはデータベース/ストレージへのアクセスを抽象化しているため、アプリケーション側でデータベース/ストレージの種類を気にする必要はありません。そのため、Scalar DBがサポートしているデータベース/ストレージであれば同じプログラムで実装できます。
また、後述する設定ファイルを書き換えるだけでコードを一切変更することなく、データベース/ストレージを変更できます。
別々の、あるいは異なるデータベース間でも、同じインターフェイスで、同じ分離レベルで実装することができる。
@Transactionアノテーションでは、異なるデータベース/ストレージ間でACIDトランザクションを実行することはできません。
一方、Scalar DBはマルチストレージ対応が行われており、異機種間データベース間、パーティション間、テーブル間といったトランザクションの制約を受ける環境でも、同じインターフェイスで、最大 でStrict Serializable の分離レベルで実装することができます。
※ 参考:
String Serializable
Spring BootにおけるAPIアーキテクチャと各レイヤーの役割
各レイヤーの役割
Spring Bootは、以下の4つレイヤーが存在し、各レイヤーがその真下または真上のレイヤーと通信するレイヤードアーキテクチャに従います。
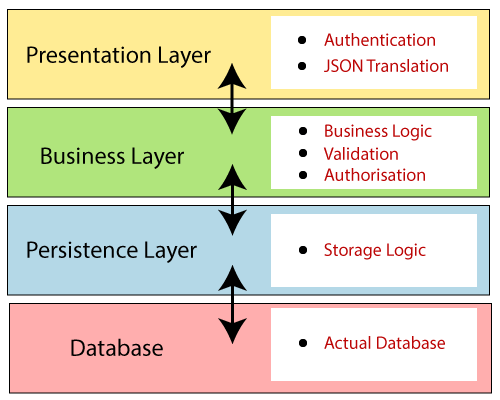
Presentation Layer
Presentation LayerはControllerクラスで構成され、HTTPリクエストを処理し、JSONパラメーターをオブジェクトに変換し、リクエストを認可してBusiness Layerに転送します。
Business Layer
Business Layerはビジネスロジックを処理します。Serviceクラスで構成され、Presentation Layerからのデータを処理し、Persistence Layerに転送し、その結果をPresentation Layerに返します。また、認証やValidationの処理も行います。
Persistence Layer
Persistence Layerは、Repositoryクラスで構成され、データベースとの接続を行い、Business Layerから転送されたデータのCRUD処理を依頼し、その結果をBusiness Layerに返します。
Database Layer
Database LayerはPersistence Layerから転送されるデータと依頼に対して、CRUD処理を実行します。
Scalar DBの各レイヤーでの実装
Scalar DB は、Persistence Layerで記述した処理を、Business Layerで一連の処理として実行したい処理をトランザクションとしてまとめて実行します。
- Persistence Layerでは、Scalar DBのメソッドを使いデータベースのテーブルに対するCRUD処理を記述します。
- Business Layerでは、Scalar DBのメソッドを使いトランザクションの処理を記述します。
APIアーキテクチャ
以上を踏まえて、Spring BootにおけるAPIアーキテクチャは以下のようになります。

DTOはHTTPリクエストから転送、または返却するためのデータを保持します。Modelはデータベースに永続化するためのデータを保持し、MapperでDTOとModelのデータをマッピングしながら、Controllerクラス、Serviceクラス、Repositoryクラスにデータを渡していきます。
サンプルアプリケーションの概要
ユーザーは、どのグループに所属するのかという情報を保持し、グループにはどのユーザーが所属しているのかというメンバー情報を保持しています。
このため、ユーザーの所属グループを変更する場合、ユーザーとグループの両方を同時に更新する必要があります。
※ 一般的に、NoSQLデータベースを用いた実装では、第三正規化が行われないため、ユーザーとグループの双方で情報を持ち、どちらの参照要求にも対応できるように実装します。
ユーザーは、管理者権限と一般権限があり、所属しているグループによって、権限を割り当てアクセス制御を行います。
要件
- 全ユーザーは自身の情報を登録できる
- 一般ユーザーは自分自身の情報の取得、更新、削除ができる
- 管理者は全てのユーザー情報の取得、更新、削除ができる
- 管理者および一般ユーザーはグループを作成できる。作成したユーザーは自動的にそのグループに所属する
- 一般ユーザーは所属するグループに対して、メンバーの追加・脱退、メンバー一覧の取得、グループの削除ができる
- 管理者は全てのグループに対してメンバーの追加・脱退、メンバー一覧の取得、グループの削除ができる
- 一般ユーザーおよび管理者は全てのグループを一覧取得できる
環境構築
- Spring Boot 2.5.6
- Scalar DB 3.3.0
- Java 8
- Cassandra 3.11
ディレクトリ構成
.
├── api
| ├── build.gradle
│ ├── src
│ │ ├── main
│ │ │ ├── java
│ │ │ │ └── com
│ │ │ │ └── example
│ │ │ │ └── api
│ │ │ │ ├── Application.java
│ │ │ │ ├── config
│ │ │ │ ├── controller
│ │ │ │ ├── dto
│ │ │ │ ├── exception
│ │ │ │ ├── model
│ │ │ │ ├── repository
│ │ │ │ ├── service
│ │ │ │ └── util
│ │ │ └── resources
│ │ │ └── database.properties
│ │ └── test
│ │ ├── java
│ │ │ └── com
│ │ │ └── example
│ │ │ └── api
│ │ │ ├── controller
│ │ │ ├── cucumber
│ │ │ ├── repository
│ │ │ ├── security
│ │ │ ├── service
│ │ └── resources
└── tools
│ ├── scalardb-schema-loader-3.3.0.jar
│ └── schema
│ └── schema.json
└── docker-compose.yml
データモデルの設計
今回作成したAPIのデータモデルは以下のようになります。

- ユーザーとグループ管理を NoSQLであるCassandra を用いて行うケースを想定しています。
- Userテーブルには、どのグループに所属しているかという情報を保持し、Groupテーブルにはどのようなユーザーが所属しているのかという情報を保持しています。
- このため、どちらかのテーブルを更新する際には、双方に存在するレコードを同時に更新する必要があります。
エンドポイントの設計
エンドポイントは以下のように設計しました。
| URI | HTTPメソッド | Description |
|---|---|---|
| /users | POST | ユーザーを登録する |
| /users | GET | ユーザーを一覧取得する |
| /users/{user_id} | GET | ユーザー情報を取得する |
| /users/{user_id} | PUT | ユーザー情報を更新する |
| /users/{user_id} | DELETE | ユーザーを削除する |
| /groups | POST | グループを登録する |
| /groups | GET | グループ一覧を取得する |
| /groups/{group_id}/group-users | PUT | グループにユーザーを追加する |
| /groups/{group_id}/group-users | GET | グループに所属するユーザーを一覧取得する |
| /groups/{group_id}/group-users/{user_id} | PUT | グループからユーザーを脱退させる |
| /groups/{group_id} | DELETE | グループを削除する |
Spring BootでのScalar DBの導入方法
Scalar DBは、ライブラリをインストールし、プロパティファイルとスキーマファイルを作成し、スキーマローダーを使ってプロパティファイルとスキーマファイルを読み込ませることによってデータベースに名前空間とテーブルを作成することができます。
ライブラリのインストール
Scalar DBのライブラリはMaven Centralから利用可能です。GradleやMavenなどのビルドツールを使ってインストールを行ってください。
dependencies {
implementation group: 'com.scalar-labs', name: 'scalardb', version: '3.3.0'
}
<dependency>
<groupId>com.scalar-labs</groupId>
<artifactId>scalardb</artifactId>
<version>3.3.0</version>
</dependency>
プロパティファイルの作成
Scalar DBがデータベース/ストレージと接続を行うためのプロパティファイルを作成します。
今回はローカル環境でCassandraを使用します。ファイル名はdatabase.propertiesとします。
各データベースでのプロパティファイルの設定方法を参照してください。
# Comma separated contact points
scalar.db.contact_points=localhost
# Port number for all the contact points. Default port number for each database is used if empty.
scalar.db.contact_port=9042
# Credential information to access the database
scalar.db.username=cassandra
scalar.db.password=cassandra
# Cassandra storage implementation
scalar.db.storage=cassandra
スキーマファイルの作成
スキーマファイルはJSONファイルで作成します。今回はschema.jsonとしておきます。
{
"demo.groups": {
"transaction": true,
"partition-key": [
"group_id"
],
"clustering-key": [],
"columns": {
"group_id": "TEXT",
"group_name": "TEXT",
"group_users": "TEXT",
"common_key": "TEXT"
},
"secondary-index": [
"common_key"]
},
"demo.users": {
"transaction": true,
"partition-key": [
"user_id"
],
"clustering-key": [],
"columns": {
"user_id": "TEXT",
"email": "TEXT",
"family_name": "TEXT",
"given_name": "TEXT",
"user_detail": "TEXT",
"user_groups": "TEXT",
"common_key": "TEXT"
},
"secondary-index": [
"common_key"
]
}
}
demoの部分がCassandraのキースペースになります。
demoの後のピリオドに続く、groupsやusersがテーブル名になります。
トランザクションを行いたい場合はtransactionをtrueにします。
その後、設計したデータモデルに合わせて、partition-key, clustering-keyを指定し、columnsにキーとデータタイプを記述します。Scalar DBでサポートしているデータタイプはDatabase schema in Scalar DBを参照してください。
また、今回はテーブルデータを全件取得するためにsecondary-indexを作成しました。
本来、Cassandraにおいてセカンダリ・インデックスの使用は推奨されませんが、今回作成するAPIはデータ件数が多くないこと、更新頻度が高くないカラムであることから使用することにしました。
データスキーマのセットアップ
作成したプロパティファイルと、スキーマファイルからデータベースにデータスキーマのセットアップを行います。
まずはCassandraが起動していることを確認してください。
今回は、dockerで起動させました。
version: '3.8'
services:
cassandra:
image: arm64v8/cassandra:3.11
container_name: "cassandra-1"
volumes:
- ./docker/cassandra-data:/var/lib/cassandra
ports:
- "9042:9042"
$ docker-compose up -d
Scalar DBのGitHubからインストールしたScalarDBと同じバージョンのスキーマローダーをダウンロードします。
各ファイルの配置場所はディレクトリ構成を参照してください。
$ java -jar tools/scalardb-schema-loader-3.3.0.jar --config api/src/main/resources/database.properties --coordinator -f tools/schema/schema.json
以下が実行結果です。
********************************
********************************
[main] INFO com.scalar.db.schemaloader.core.SchemaOperator - Creating the table groups in the namespace demo succeeded.
[main] INFO com.scalar.db.schemaloader.core.SchemaOperator - Creating the table users in the namespace demo succeeded.
テーブルが作成できました。念の為、cqlで確認してみましょう。
$ docker exec -it cassandra-1 cqlsh
cqlsh> DESC demo.users
CREATE TABLE demo.users (
user_id text PRIMARY KEY,
before_common_key text,
before_email text,
before_family_name text,
before_given_name text,
before_tx_committed_at bigint,
before_tx_id text,
before_tx_prepared_at bigint,
before_tx_state int,
before_tx_version int,
before_user_detail text,
before_user_groups text,
common_key text,
email text,
family_name text,
given_name text,
tx_committed_at bigint,
tx_id text,
tx_prepared_at bigint,
tx_state int,
tx_version int,
user_detail text,
user_groups text
)
cqlsh> DESC demo.users
CREATE TABLE demo.groups (
group_id text PRIMARY KEY,
before_common_key text,
before_group_name text,
before_group_users text,
before_tx_committed_at bigint,
before_tx_id text,
before_tx_prepared_at bigint,
before_tx_state int,
before_tx_version int,
common_key text,
group_name text,
group_users text,
tx_committed_at bigint,
tx_id text,
tx_prepared_at bigint,
tx_state int,
tx_version int
)
無事、データスキーマのセットアップが完了しました。
次回は、具体的なAPIの実装方法について説明していきます。