[2023/2/3 追記]
2023/2/9よりツイートの無料取得ができなくなる関係で、当記事での無料の方法は使えなくなりそうです... ![]()
![]()
やりたいこと
-
概要
- tweepyなどの3rdパーティライブラリではなく、TwitterのAPI Referenceに沿ってツイートを取得する
- そのため、[API key][API key secret]ではなく[Bearer token]でクエリをたたく
-
大まかな流れ
- TwitterAPIのアカウント申請
- botツイートを除外するためのノイズを確認(目視で特定)
- ツイートデータの取得・後工程の分析のためのクエリ生成の工夫
- 分析時の比較対象ツイートの取得
- e.g. メインの取得対象がトヨタなら日産や三菱自動車、パナソニックならソニーのツイートを取得
- 前処理
- ツイート日時の変換(UTCから日本時間へ)
- ツイート文中の絵文字、URLやReply先アカウント名の削除
-
Twitter側制約事項に対する対処
- 1リクエストの取得上限である100件を超える分は、ネクストトークンで取得
- 15分間で180リクエストを超える場合、スリープをはさむ
環境
- コンピュータ
-
Twitter API
- StandardプランとAcademicResearchプランのうち、使うのはStarndardプラン
(自分は研究機関ではなかったので) - Twitterの仕様により、ツイート取得期間は最大7日前まで
- StandardプランとAcademicResearchプランのうち、使うのはStarndardプラン
TwitterAPIのアカウント申請
こちら様のサイトを見てTwitter Developerアカウントを作成しました。
アカウント承認後、Developerポータル画面からプロジェクトを作成し、[Bearer token]の内容をメモっておきます。
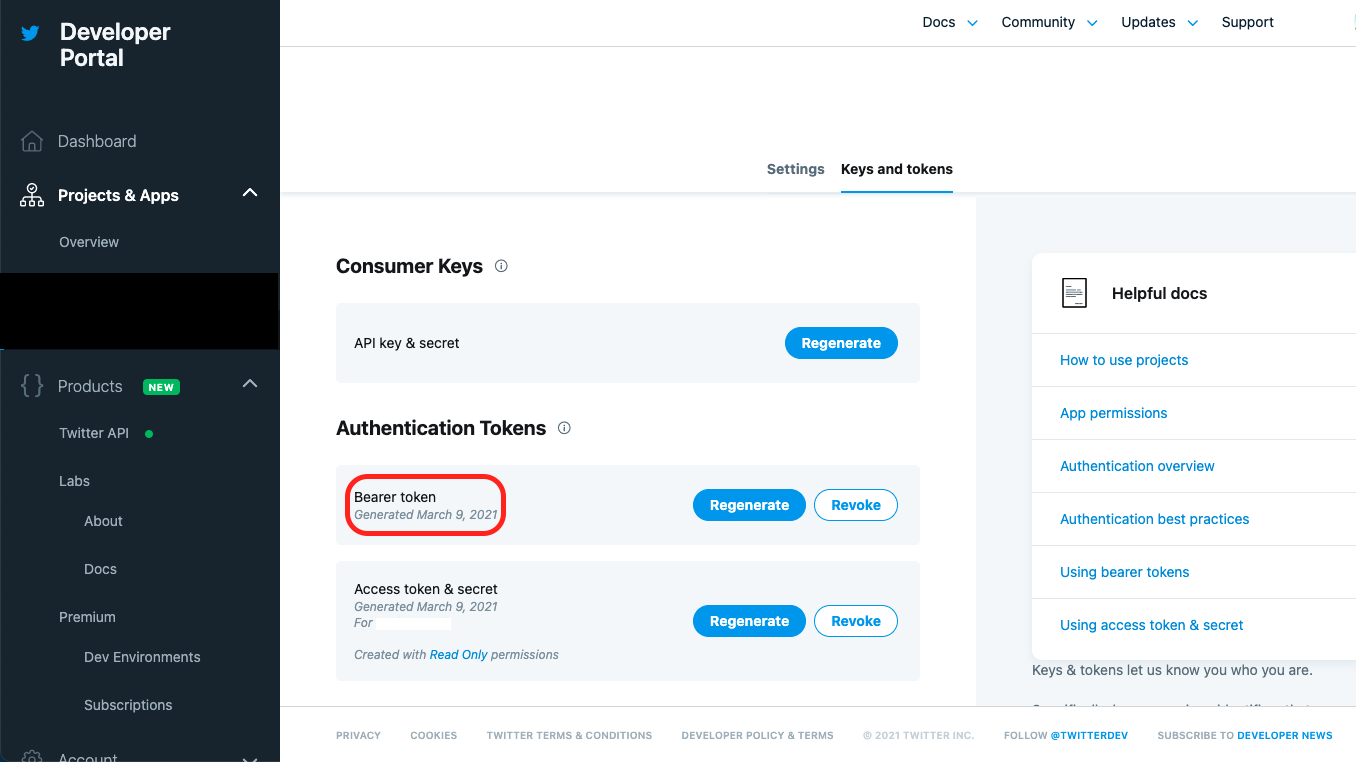
※ Bearer token生成後の画面(生成時の画面ショットを撮り漏れました)
botツイートを除外するためのノイズを確認(目視で特定)
例えば、「トヨタ」を含むツイートを取得したい場合、bot(っぽいアカウント)がたくさんツイートしています。
これらをそのまま取得してしまうとクエリ取得数を圧迫してしまうので、botアカウントのツイートは取得対象から除外するとします。
自分のツイッター画面か、Yahooリアルタイム検索のお好きなやり方で。
下記はツイッターの画面ですが、botと思しきユーザー名を確認します。(黒く塗りつぶした箇所)
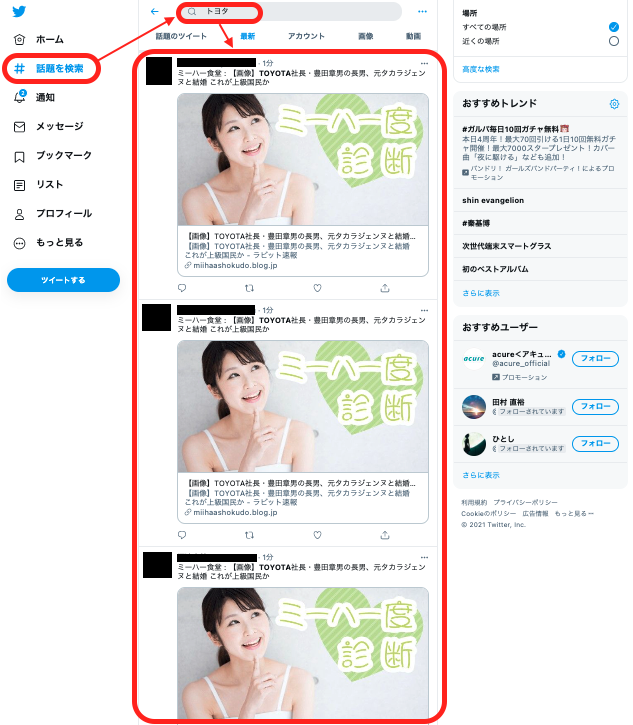
ツイートデータの取得・後工程の分析のためのクエリ生成の工夫
APIに投げるクエリパラメータ
クエリパラメータの仕様を確認します。
Example requestsによると、クエリの基本構造はこのような形を取れば良さそうです。
"https://api.twitter.com/2/tweets/search/recent?query=[検索ワードなど最低1つ(必須)][除外対象やツイート日時など、オプションのパラメータがある場合は'&'でつなぎます(任意)]" -H "Authorization: Bearer [Bearer token]"
- クエリ引数の1つ目には、最低一つ値を与えます
- 自分は検索したいワード(「トヨタ」)としました
- 自分は検索したいワード(「トヨタ」)としました
query=トヨタ
* トヨタ以外にもあとで「日産」ツイートも取得したいので、引数に変数を差し込む形でコーディングします
- クエリ引数の2つ目以降は、「&」でつないで値を与えます
- 1つ目の引数と同様、コーディング時は変数として扱います
- 「リツイートは除く」且つ「複数のbotアカウントも除く」など複数の指定条件を与える場合、Building a queryによるとこのように表現すればOKです(ユーザー名は'@'を含めない)
-is:retweet -(from:[TWITTER USER NAME A] OR from:[TWITTER USER NAME B] OR from:...)
* ツイートのユニークidやツイート文、ツイート日時などは、辞書型の[tweet.fields]オブジェクトで取得できるため、<a href="https://developer.twitter.com/en/docs/twitter-api/data-dictionary/object-model/tweet" target="_blank">こちら</a>を参照して取得パラメータを記載します(複数の値を取得したい場合はカンマ区切り)<br>
tweet.fields=author_id,id,text,created_at
* 1リクエスト時の最大取得数は、このように記載します(最低10〜最大100)<br>
max_results=100
* 最大取得数を超えてまだツイート情報がある場合は、レスポンス時の辞書型データに[next_token]が返ってくるので、次のクエリにパラメータとして与えます<br>
next_token=[NEXT TOKEN]
- [Bearer token]には、事前にメモったトークンを記載します
クエリパラメータイメージ
"https://api.twitter.com/2/tweets/search/recent?query=トヨタ& -is:retweet -(from:HOGE OR from:FUGA&tweet.fields=author_id,id,text,created_at&max_results=100&next_token=[NEXT TOKEN]" -H "Authorization: Bearer [Bearer token]"
コード①
主要な部分はTwitter社のRepositoryを参考にしました。
get_tweet.py
def create_url(QUERY, MAX_RESULTS):
# クエリ条件:指定のワードを含む、リツイートを除く、botと思われるユーザーのツイートを除く
query = QUERY
tweet_fields = "tweet.fields=author_id,id,text,created_at"
max_results = MAX_RESULTS
url = "https://api.twitter.com/2/tweets/search/recent?query={}&{}&{}".format(
query, tweet_fields, max_results
)
return url
def create_headers(bearer_token):
headers = {"Authorization": "Bearer {}".format(bearer_token)}
return headers
def connect_to_endpoint(url, headers):
response = requests.request("GET", url, headers=headers)
# print('status code:', str(response.status_code))
if response.status_code != 200:
raise Exception(response.status_code, response.text)
return response.json()
def get_tweet(BEARER_TOKEN, MAX_RESULTS, QUERY):
bearer_token = BEARER_TOKEN
url = create_url(QUERY, MAX_RESULTS)
headers = create_headers(bearer_token)
json_response = connect_to_endpoint(url, headers)
json_dumps = json.dumps(json_response, indent=4, sort_keys=True)
return ast.literal_eval(re.sub('\\n\s+', '', json_dumps))
# 〜〜〜〜〜〜データを整形する関数 中略〜〜〜〜〜〜
BEARER_TOKEN = "[BEARER_TOKEN]"
MAX_RESULTS = "max_results=100" # A number between 10 and 100.
TARGET_WORDS = [
"トヨタ",
"日産"
]
QUERY_CONDITIONS = [
" -is:retweet -(from:HOGE OR from:FUGA)",
" -is:retweet -(from:FOO OR from:BAR)"
]
df = pd.DataFrame()
iterator, request_iterator = 0, 0
# クエリのlistが終わるまでAPIを叩く
for target_word, query_ in zip(TARGET_WORDS, QUERY_CONDITIONS):
next_token = ''
break_flag = False
# 次ページがなくなるまで次ページのクエリを取得
while True:
try:
data['meta']['next_token']
except KeyError: # 次ページがない(next_tokenがない)場合はループを抜ける
del data
break_flag = True
except NameError: # TARGET_WORDS内の各要素で初めてAPIを取得するとき
query = query_
else: # 2ページめ以降の処理
next_token = data['meta']['next_token']
query = query_ + '&next_token=' + next_token
finally:
if break_flag == True: break
QUERY = '{}{}'.format(target_word, query)
data = get_tweet(BEARER_TOKEN, MAX_RESULTS, QUERY)
temp_df = pd.DataFrame(shape_data(data['data']))
temp_df[target_word] = True
df = pd.concat([df, temp_df])
iterator += data['meta']['result_count']
request_iterator += 1
if request_iterator >= 180: # 180requestを超えたら止める
print('180リクエストを超えるため、15分間停止します...')
time.sleep(15.01*60) # 15分間(余裕をみてプラス1秒弱)中断
request_iterator = 0
print(str(iterator) + '件取得しました。')
取得したresponseデータの整形
分析の目的に応じて、後工程で利用しやすいようにデータを加工します。
- ツイート日時[created_at]はUTC表示のため、日本時間(JST)へ変更する
- ツイート文[text]に含まれる、不要なデータを削除する
- URL
- Reply先のユーザー名
- 顔文字
- 全角スペースや改行
コード②
shape_data.py
def utc_to_jst(timestamp_utc):
datetime_utc = datetime.datetime.strptime(timestamp_utc + "+0000", "%Y-%m-%d %H:%M:%S.%f%z")
datetime_jst = datetime_utc.astimezone(datetime.timezone(datetime.timedelta(hours=+9)))
timestamp_jst = datetime.datetime.strftime(datetime_jst, '%Y-%m-%d %H:%M:%S')
return timestamp_jst
def shape_data(data):
for i, d in enumerate(data):
# URLの削除
data[i]['text'] = re.sub('[ ]https://t\.co/[a-zA-Z0-9]+', '', d['text'])
# ユーザー名の削除
data[i]['text'] = re.sub('[ ]?@[a-zA-Z0-9_]+[ ]', '', d['text'])
# 絵文字の除去
data[i]['text'] = d['text'].encode('cp932',errors='ignore').decode('cp932')
# # ハッシュタグの削除
# data[i]['text'] = re.sub('#.+ ', '', d['text'])
# 全角スペース、タブ、改行を削除
data[i]['text'] = re.sub(r"[\u3000\t\n]", "", d['text'])
# 日付時刻の変換(UTCからJST)
data[i]['created_at'] = utc_to_jst(d['created_at'].replace('T', ' ')[:-1])
return data
コード全文
tweetlog.py
import pandas as pd
import requests
import json
import re
import ast
import datetime
import time
def create_url(QUERY, MAX_RESULTS):
# クエリ条件:指定のワードを含む、リツイートを除く、botと思われるユーザーのツイートを除く
query = QUERY
tweet_fields = "tweet.fields=author_id,id,text,created_at"
max_results = MAX_RESULTS
url = "https://api.twitter.com/2/tweets/search/recent?query={}&{}&{}".format(
query, tweet_fields, max_results
)
return url
def create_headers(bearer_token):
headers = {"Authorization": "Bearer {}".format(bearer_token)}
return headers
def connect_to_endpoint(url, headers):
response = requests.request("GET", url, headers=headers)
# print('status code:', str(response.status_code))
if response.status_code != 200:
raise Exception(response.status_code, response.text)
return response.json()
def get_tweet(BEARER_TOKEN, MAX_RESULTS, QUERY):
bearer_token = BEARER_TOKEN
url = create_url(QUERY, MAX_RESULTS)
headers = create_headers(bearer_token)
json_response = connect_to_endpoint(url, headers)
json_dumps = json.dumps(json_response, indent=4, sort_keys=True)
return ast.literal_eval(re.sub('\\n\s+', '', json_dumps))
def utc_to_jst(timestamp_utc):
datetime_utc = datetime.datetime.strptime(timestamp_utc + "+0000", "%Y-%m-%d %H:%M:%S.%f%z")
datetime_jst = datetime_utc.astimezone(datetime.timezone(datetime.timedelta(hours=+9)))
timestamp_jst = datetime.datetime.strftime(datetime_jst, '%Y-%m-%d %H:%M:%S')
return timestamp_jst
def shape_data(data):
for i, d in enumerate(data):
# URLの削除
data[i]['text'] = re.sub('[ ]https://t\.co/[a-zA-Z0-9]+', '', d['text'])
# ユーザー名の削除
data[i]['text'] = re.sub('[ ]?@[a-zA-Z0-9_]+[ ]', '', d['text'])
# 絵文字の除去
data[i]['text'] = d['text'].encode('cp932',errors='ignore').decode('cp932')
# # ハッシュタグの削除
# data[i]['text'] = re.sub('#.+ ', '', d['text'])
# 全角スペース、タブ、改行を削除
data[i]['text'] = re.sub(r"[\u3000\t\n]", "", d['text'])
# 日付時刻の変換(UTCからJST)
data[i]['created_at'] = utc_to_jst(d['created_at'].replace('T', ' ')[:-1])
return data
BEARER_TOKEN = "[BEARER_TOKEN]"
MAX_RESULTS = "max_results=100" # A number between 10 and 100.
TARGET_WORDS = [
"トヨタ",
"日産"
]
QUERY_CONDITIONS = [
" -is:retweet -(from:HOGE OR from:FUGA)",
" -is:retweet -(from:FOO OR from:BAR)"
]
df = pd.DataFrame()
iterator, request_iterator = 0, 0
# クエリのlistが終わるまでAPIを叩く
for target_word, query_ in zip(TARGET_WORDS, QUERY_CONDITIONS):
next_token = ''
break_flag = False
# 次ページがなくなるまで次ページのクエリを取得
while True:
try:
data['meta']['next_token']
except KeyError: # 次ページがない(next_tokenがない)場合はループを抜ける
del data
break_flag = True
except NameError: # TARGET_WORDS内の各要素で初めてAPIを取得するとき
query = query_
else: # 2ページめ以降の処理
next_token = data['meta']['next_token']
query = query_ + '&next_token=' + next_token
finally:
if break_flag == True: break
QUERY = '{}{}'.format(target_word, query)
data = get_tweet(BEARER_TOKEN, MAX_RESULTS, QUERY)
temp_df = pd.DataFrame(shape_data(data['data']))
temp_df[target_word] = True
df = pd.concat([df, temp_df])
iterator += data['meta']['result_count']
request_iterator += 1
if request_iterator >= 180: # 180requestを超えたら止める
print('180リクエストを超えるため、15分間停止します...')
time.sleep(15.01*60) # 15分間(余裕をみてプラス1秒弱)中断
request_iterator = 0
print(str(iterator) + '件取得しました。')
df.reset_index(drop=True, inplace=True)
df.to_pickle('./raw_tweetlog.pkl')
コメント
- UTCから日本時間への変更や絵文字の文字コード処理は、もっといい方法がある気がする
- データ整形の部分は、URLから画像データを取得・画像解析したりハッシュタグごとの頻度を取ったり、リプライ先を抽出してノード・ネットワーク図を描いても面白いかも
- データの取得期間が最大7日間って短すぎるよ…

- (3月29日)続きを書きました -> ツイートデータのテキストマイニング