本記事の概要
- 背景
- 「検索機能を自分でつくることができるElasticsearchというものがある」と聞いて「そんなものが…!?」と衝撃を受けました
- 「Elasticsearchを環境用意せずに使えるElastic Cloudというものがある」と聞いて「それは使いたい…!」と思いました
- 内容
- Elastic Cloudでごく簡単な検索処理を試作します
- アカウント登録から検索結果の確認まで
- Elasticsearch自体の仕組み(検索データの作成方法やAPIの解説など)は触れていません
- 備考
- 「検索機能を自分でつくることができるらしい」と聞いて「そんなものが…!?」と衝撃を受けた方向けの記事です
目次
1. 製品/サービスの用語確認
記事執筆時(2021年10月)の情報のため、現在のサービス仕様と異なる可能性があります。
Elasticsearch ... オープンソースの検索エンジン
検索機能を一から自前で実装するとなると膨大な年月と頭脳が必要になりそうです。しかし、検索機能に必要な共通機能が上手くまとめられたモノがこの世に存在します。それがElasticsearchです。
Elasticsearchはオープンソース提供されており、自前でセットアップすれば誰でも利用可能です。大まかには開発者側で稼働環境と検索データを用意すれば動作します。
同じ文脈でKibanaやLogstashといったキーワードがしばし登場しますが、提供元のElastic社が併用を推している関連製品(通称 Elastick Stack)になります。サーバの死活監視やログの管理がしやすくなるようです。そのほかにも日本語対応用プラグインのKuromojiなども頻出です。
公式説明は以下です。
無料かつオープン、Elastic Stackのハート
Elasticsearchは、様々なユースケースを解決する分散型RESTful検索/分析エンジンです。 データを一元的に格納することで、超高速検索や、関連性の細かな調整、パワフルな分析が大規模に、手軽に実行可能になります。Elastic Stackの心臓部となるプロダクトです。
(出典: https://www.elastic.co/jp/elasticsearch/ )
力強い文章ですね…![]()
![]()
![]()
Elastic Cloud ... 稼働環境ごとElastic製品を提供するサービス
本記事ではElastic Cloud上で提供されているElasticsearchを試用します。Elastic Cloudとは何かという疑問が出てきますが…
Answer.
クラウドのためのエンタープライズサーチ、オブザーバビリティ、セキュリティ
(出典: https://www.elastic.co/jp/cloud/ )
… ![]() ?
?
どうやら、Elastic製品をクラウド上の稼働環境にセットアップした状態で提供するサービスのようです。
従来は利用までに初期導入作業(環境構築やソフトのインストール)が必要でした。しかし、Elastic Cloudであればこの工程をスキップしてすぐに利用を始められます。さらに、OSやソフトのアップデートなどメンテナンス作業もポータル上で完結します。とはいえ、破壊的なバージョン更新などもあるらしく、保守運用ふくめると深遠なテーマになりそうなため本記事では流します…。
2. 使ってみる
Elastic CloudはAWS・Azure・GCPと連携可能ですが、AWSとGCPについては実際に試していないため、本記事内ではAzureに関してのみ言及しています。
また、検索データの準備に関しては本記事では割愛しています。
筆者の実行環境は以下です。
- OS: Windows10
- ブラウザ: Chrome(ver.94.0.4606.81, 64bit)
アカウント登録
Elastic Cloud 公式HPから、新規登録(無料トライアル)を行います。今回はメールアドレスによる登録を行います。
AzureまたはGCPアカウントでの連携(ソーシャルログイン)も対応しています。
Azure連携する場合、課金請求をAzureのサブスクリプションにまとめることが可能です。
Azure連携する場合、Elastic Cloud上ではなくAzure Marketplace上で登録を行ってください。
Azure連携する場合、トライアルの利用が不可です!デプロイ次第コストが発生します!
Azure Marketplaceからの登録方法は公式リファレンスにまとめられています。

デプロイ
デプロイ環境はパブリッククラウドのベンダとリージョンを選択可能です。今回はAzureの東日本リージョンを選択します。
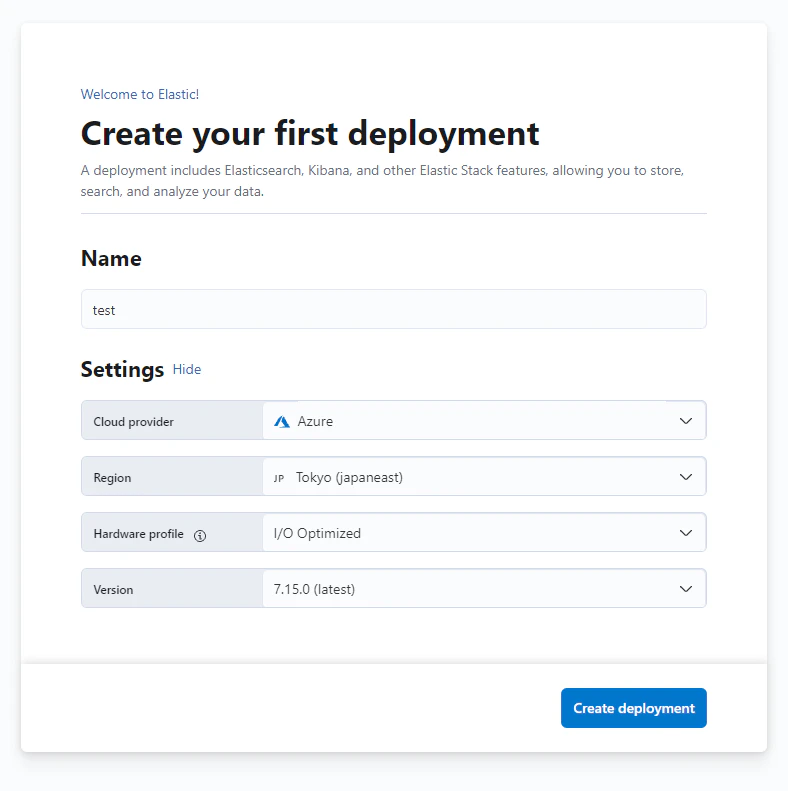
デプロイ後、認証情報が表示されますのでお手元に控えてください。検索実行時のBasic認証にて使用します。筆者は控え忘れました。
パスワードはセキュリティ設定からリセット可能です。

※ サンプルイメージはUsernameを隠し忘れているわけではなのでご安心ください。共通設定です。
アクセス設定を変更
デプロイ後、アクセス設定を行います。今回はトラフィックフィルターでアクセス可能なIPを限定します。
デプロイ直後は検索APIのエンドポイントが全公開されています。

まずはトラフィックルールを作成。

セキュリティ設定からフィルターを適用。

ほかにも様々あるようなので、必要に応じてご検討ください。
日本語検索対応プラグインを追加
日本語を含むドキュメントを扱う場合はJapanese (kuromoji) Analysis Pluginプラグインを導入する必要があります。


追加した後にSaveを忘れないようご注意ください。筆者はSaveボタンではなくBackボタンを押して満足していました。成功した場合はActivityからログを確認可能です。
禊
心の準備を行います。動作成功イメージをつける場合以外は本ステップを飛ばして問題ありません。
ポータル上にはAPIコンソールが備えられています。ここでAPIの実行と結果確認が可能です。試しに検索APIを実行すると…

達成感を得られました。
検索データを準備する
Elasticsearchの仕組みに触れると長くなるため割愛します。
少しだけ触りますと…以下のデータを準備します。
- ドキュメント: 検索結果となるデータ
- インデックス: ドキュメントを保存する領域(≒ DB)
- マッピング: インデックス内にドキュメントの型定義や検索方法のオプションを定義したもの
それぞれ以下のようなファイルです。
{
"settings": {
"analysis": {
"analyzer": {
"kuromoji_analyzer": {
"type": "custom",
"tokenizer": "kuromoji_tokenizer"
}
}
}
}
}
{
"properties": {
"id": {
"type": "keyword"
},
"見出し": {
"type": "text",
"analyzer": "kuromoji_analyzer"
},
"本文": {
"type": "text",
"analyzer": "kuromoji_analyzer"
}
}
}
※bulkファイルは末尾が改行である必要があります。
{ "index" : {"_id" : "1" } }
{ "見出し": "今日の夕飯", "本文": "めざしらしい" }
{ "index" : {"_id" : "2" } }
{ "見出し": "明日の天気", "本文": "快晴だとおもう" }
※ 別記事にて詳細を後日掲載予定です。
※ 公式サンプルデータ
API利用編:疎通確認
ElasticsearchはREST APIで操作可能です。
ユーザーの端末とElasticsearchサーバで疎通確認します。まずはエンドポイントのURLを取得します。

ブラウザでアクセスする方法がもっともお手軽です。アクセス時に認証情報の入力が求められるので、デプロイ時に控えたものを入力します。
cmdで確認する場合の雛形はこちらです。
全大文字の箇所を実行環境にあわせて変更してください
uオプションは認証、xオプションはプロキシ設定です
プロキシ無
curl https://ENDPOINT -u ID:PASS
プロキシ有
curl https://ENDPOINT -u ID:PASS -x http://PROXY
疎通できている場合はビルド日時等と併せて"You Know, for Search"というテキストが含まれたJSONレスポンスが返ってきます。
API利用編:検索データを投入
検索データをPUT/POSTしていきます。
全大文字の箇所を実行環境にあわせて変更してください
インデックス
curl -X PUT "ENDPOINT/TEST_INDEX" -u ID:PASS -x http://PROXY -H "Content-type:application/json" -d kuromoji.setting
マッピング
curl -X PUT "ENDPOINT/TEST_INDEX/_mapping" -u ID:PASS -x http://PROXY -H "Content-type:application/json" -d TEST_MAPPING.mapping
ドキュメント
curl -X POST "ENDPOINT/_bulk?pretty" -u ID:PASS -x http://PROXY -H "Content-type:application/json" --data-binary @data/TEST_BULK.bulk
それぞれ実行結果は以下のようになります。インデックスとマッピングの登録に関してはAPIコンソールで実行しました。
インデックス
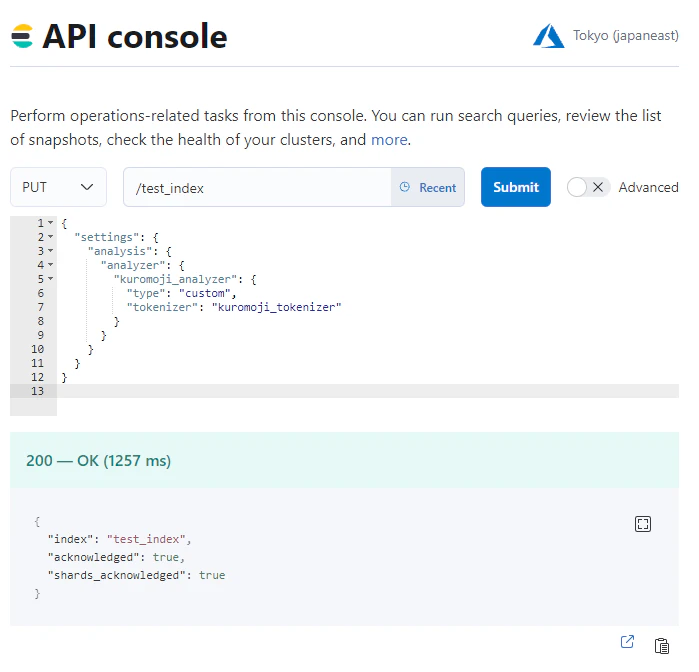
マッピング

ドキュメント
{
"took" : 33,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "test_index",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "test_index",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
}
]
}
今回はインデックスとマッピングの定義を事前に作成しましたが、ドキュメント登録APIを利用するとよしなに同時作成できるようです。
API利用編:検索を実行
まずは全件検索を行い、ドキュメントが登録されていることを確認します。
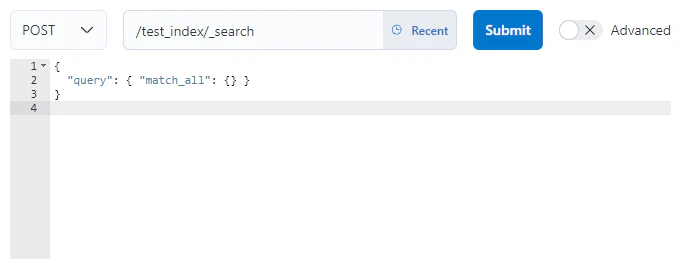
結果
{
"hits": {
"hits": [
{
"_score": 1,
"_type": "_doc",
"_id": "1",
"_source": {
"本文": "めざしらしい",
"見出し": "今日の夕飯"
},
"_index": "test_index"
},
{
"_score": 1,
"_type": "_doc",
"_id": "2",
"_source": {
"本文": "快晴だとおもう",
"見出し": "明日の天気"
},
"_index": "test_index"
}
],
"total": {
"relation": "eq",
"value": 2
},
"max_score": 1
},
"_shards": {
"successful": 1,
"failed": 0,
"skipped": 0,
"total": 1
},
"took": 0,
"timed_out": false
}
![]()
検索条件を変更するためにリクエストボディを差し替えます。
{
"query": {
"term": {
"本文": "めざし"
}
}
}
結果
{
"hits": {
"hits": [
{
"_score": 0.8025915,
"_type": "_doc",
"_id": "1",
"_source": {
"本文": "めざしらしい",
"見出し": "今日の夕飯"
},
"_index": "test_index"
}
],
"total": {
"relation": "eq",
"value": 1
},
"max_score": 0.8025915
},
"_shards": {
"successful": 1,
"failed": 0,
"skipped": 0,
"total": 1
},
"took": 1,
"timed_out": false
}
![]()
![]()
キーワード「めざし」に関連するドキュメントのみを拾うことが出来ました。
3. さいごに
Elastic Cloudで文書検索処理を味見しました。しかし本来のElasticsearchの実力の1%も引き出せていません…。長文検索・複数のデータソースをまたがる検索・分散処理 ・etc... 膨大にあるようです。
本記事を通して「お手軽に試せそう!」とElasticの輪が広がれば幸いです。
4. 参考
リファレンス
商標
- Elasticsearch、Elastic Cloud、Japanese (kuromoji) Analysis PluginおよびElastic社の各種サービスは、 Elasticsearch BVまたはその関連会社の商標です。
- Microsoft AzureおよびMicrosoft社の各種サービスは、Microsoft Corporationまたはその関連会社の商標です。
- 記載の会社名、製品名、サービス名等はそれぞれの会社の商標または登録商標です。