はじめに
Google Cloud Data CatalogからPythonを使ってデータを抽出する機会があり、詰まったところ、TIPSなどをまとめてみました。
Data Catalogを使って何をするか
今回使用した Data Catalogの機能面をGoogleのサイトから拾ってみました。
フルマネージドでスケーラビリティの高いデータ検出およびメタデータ管理サービス。
Data Catalog は、さまざまな Google Cloud システムからアセット メタデータをカタログ化できます。
Data Catalog API を使用して、カスタム データソースと統合することもできます。
データをカタログ化したら、タグを使用してこれらのアセットに独自のメタデータを追加できます。
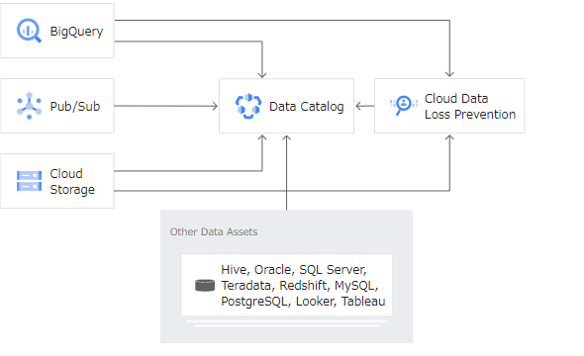
組織が大きく、データが増えるほどに以下のような課題が生じてくる為、それらをメタデータとしてData Catalogで一元的に管理し、探索できるようになることで解決していくことに役立つものとなります。
- データがどこにあるのか、どんな名前なのか、どんな項目を持っているのか、最後に更新されたのはいつか、といったテクニカルメタデータ
- だれが管理しているのか、どこから取得しているのか、更新頻度はどれくらいか、データ値の業務的な意味はなにか、といったビジネスメタデータ
APIを使用してBigQueryテーブルのメタデータを取得する
今回はBiqQueryのテーブルメタデータをPythonのAPIを使って取得してみます。
BigQueryのテーブルメタデータはリアルタイムでData Catalogに自動取込されているので、すぐに使うことができます。
前提条件
以下2つを行っておきます。
- Pythonを動かすプロジェクトでData Catalog APIを有効にする
- 使用するアカウント(今回はサービスアカウント)にData Catalogの権限(今回は取得だけなので閲覧者権限)を設定する
get_entryメソッドを使ってみる
Data Catalogのオブジェクトはエントリと呼ばれるらしいです。
GoogleのAPIリファレンスからget_entryがダイレクトに取得できそうなので上記リンクにある以下サンプルをベースに試してみます。
def sample_get_entry():
# Create a client
client = datacatalog_v1.DataCatalogClient()
# Initialize request argument(s)
request = datacatalog_v1.GetEntryRequest(
name="name_value",
)
# Make the request
response = client.get_entry(request=request)
# Handle the response
print(response)
nameだけ指定すれば良さそうですが、何を指定するのでしょうか。。リファレンスを見ると、
Parameters:Name
Required. The name of the entry to get. This corresponds to the name field on the request instance; if request is provided, this should not be set.
...具体例が欲しいところです。リファレンスをさまよっているとdatacatalog_v1beta1のget_entryに書式例がありました。
Parameters:Name
Required. The name of the entry. Example: - projects/{project_id}/locations/{location}/entryGroups/{entry_group_id}/entries/{entry_id}
This corresponds to the name field on the request instance; if request is provided, this should not be set.
{entry_group_id}と{entry_id}がよく分かりませんが、とりあえずデータセット名とテーブル名を設定して実行してみます。
name="projects/"+project_id
+"/locations/"+location_name
+"/entryGroups/"+dataset_name
+"/entries/"+table_name,
エラーです。
'google.api_core.exceptions.PermissionDenied: 403 No permission
to get Entry "projects/XXXXXXXX/locations/YYYYYYYY/entryGroups/ZZZZZZZZ/entries/AAAAAAAA" or it does not exist.'
テーブルが存在しないはずはないので、権限の問題なのかな?いやそんなはずない。![]() などと色々試行錯誤しました。
などと色々試行錯誤しました。
search_catalogメソッドを使うと指定したデータセットのテーブルリストが取得できたので、リストから目的のテーブルを探すことで対象のエントリ情報を取得できました。
その際のプロパティから以下が判明。テーブルIDってなんだ?そもそもテーブル名を指定して取得したいので、このやり方では無駄があります。
- entry_group_id・・・@bigquery固定値
- entry_id・・・・・・各テーブルが持つ内部的なID(80桁ほどの英数字)
lookup_entryメソッドを使ってみる
困ったのでGoogleに問い合わせた結果、lookup_entryメソッドを使えばよいと教えていただきます。
もう少しちゃんとリファレンス見とけば。。と反省です。![]()
以下サンプルを使ってみます。
def sample_lookup_entry():
# Create a client
client = datacatalog_v1.DataCatalogClient()
# Initialize request argument(s)
request = datacatalog_v1.LookupEntryRequest(
linked_resource="linked_resource_value",
)
# Make the request
response = client.lookup_entry(request=request)
# Handle the response
print(response)
linked_resourceはどう指定するのか、リファレンスを読むと書式があります。
datasetIDとtableIdとあり、ここをデータセット名とテーブル名にしてみます。
Attributes:linked_resource
The full name of the Google Cloud Platform resource the Data Catalog entry represents.
See: https://cloud.google.com/apis/design/resource_names#full_resource_name. Full names are case-sensitive.
Examples: - //bigquery.googleapis.com/projects/projectId/datasets/datasetId/tables/tableId
無事にデータセット名とテーブル名を指定してData Catalogのエントリ情報を取得できました!![]()
linked_resource="//bigquery.googleapis.com/projects/"+project_id
+"/datasets/"+dataset_name
+"/tables/"+table_name,
ちょっと豆知識1
lookup_entryメソッドで、データセット名とテーブル名を指定してData Catalogのエントリ情報を検索した際に、対象のテーブルがなかった場合、get_entryメソッドでテーブルIDではなくテーブル名を指定して発生していたエラーと同じ、
'google.api_core.exceptions.PermissionDenied: 403 No permission' となります。
権限はあるけれどPermissionDeniedとなる為、ハンドリングする場合はExceptionでこのエラーをキャッチする必要があります。
ちょっと豆知識2
lookup_entryメソッドのresponseは見た目はJSON形式ですが、PythonでresponseをJSON辞書型に変換できません。
いったんString型に変換した上で、自分で分解するように実装するしかありませんでした。。別の方法があるのでしょうか。。?![]()
Data CatalogからBiqQueryのどんな情報が取得できるのか
さてようやくData Catalogのエントリ情報が取得できたので、中身を確認してみました。
以下リファレンスです。
BiqQueryのテーブルの場合、Data Catalogのエントリ情報の内容は以下の2つに大きく分けられます。
- スキーマ情報(schema)としてテーブルカラム(columns)の名前(column)、型(type)、説明(description)
- 源泉システム上のタイムスタンプ(source_system_timestamps)として作成タイムスタンプ(create_time)、更新タイムスタンプ(update_time)
スキーマ情報はBiqQueryのテーブルをコンソールで見たスキーマ情報と同等です。
source_system_timestampsはコンソールで確認できるテーブル情報の作成日時や最終更新日時とは異なるようです。これは一体何か?
動作確認したところ、テーブルのデータ操作(INSERT/UPDATE/DELETE)しても更新されず、カラムの説明(description)を変更したり、カラムを追加すると更新タイムスタンプ(update_time)が更新されました。
ということは、これを使えばメタデータの更新有無をチェックして、更新がある場合のみ処理を行うといった制御ができそうです。
と思ったのですが、、
ちょっとアテンション
メタデータの更新有無をチェックした制御を実装したところ、実際にはメタデータを変更していないのに、更新タイムスタンプ(update_time)が更新されているといった事態が発生しました。
原因は分からずじまいで、結局、スキーマ情報の全項目の名前(column)、型(type)、説明(description)をBiqQueryのテーブル上で管理しておき、差異がないかをチェックすることで対処できますが、口惜しいところです。。
ちょっと豆知識3
lookup_entryメソッドで取得したエントリ情報の説明(description)に日本語が含まれている場合に8進数形式(”名”の場合"/343/203/227")となってしまい、実に困ってしまいました。
こちらの原因はPythonで使用するBigQueryパッケージのバージョンが古いと生じるようで、BigQueryのバージョンを最新化するか、8進数⇒10進数⇒16進数と変換することで回避できます。
次回はタグテンプレートを使ってみます
ここまでData Catalogのエントリ情報の取得方法と内容を確認しましたが、データセット毎に持つINFORMATION_SCHEMA.COLUMN_FIELD_PATHSテーブルから取得できる内容と差異がなく、BigQueryのテーブルのテクニカルメタデータを取得するだけであれば、Data Catalogを使う効果はないといえます。
ですが、タグテンプレートを作成してビジネスメタデータを付加することで、Data Catalogの神髄が発揮できるはずです。
次回はタグテンプレートについて調べて行く予定です。![]()