Colaboratoryで競馬データのスクレイピング
競馬データのスクレイピングをしたい、かつ機械学習となったら、Colaboratory便利なので、
Colaboratoryで競馬のスクレイピングをしたコードをメモします。
(htmlの変更でスクレイピングできなくなるかもしれませんので注意してください。2020.8/30動作確認済み)
以下コード
sample.ipynb
# Chromiumとseleniumをインストール
# 「!」印ごとColaboratoryのコードセルに貼り付けます。
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
!pip install selenium
# BeautifulSoupのライブラリをインポート
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
race_date ="2020"
race_course_num="06"
race_info ="03"
race_count ="05"
race_no="01"
url = "https://race.netkeiba.com/race/result.html?race_id="+race_date+race_course_num+race_info+race_count+race_no+"&rf=race_list"
# 該当URLのデータをHTML形式で取得
race_html=requests.get(url)
race_html.encoding = race_html.apparent_encoding
race_soup=BeautifulSoup(race_html.text,'html.parser')
# 無駄な文字列を取り除いてリストへ格納
def make_data(data):
data = re.sub(r"\n","",str(data))
data = re.sub(r" ","",str(data))
data = re.sub(r"</td>","'",str(data))
data = re.sub(r"<[^>]*?>","",str(data))
data = re.sub(r"\[","",str(data))
return data
# レース表だけを取得して保存
HorseList = race_soup.find_all("tr",class_="HorseList")
# レース表の整形
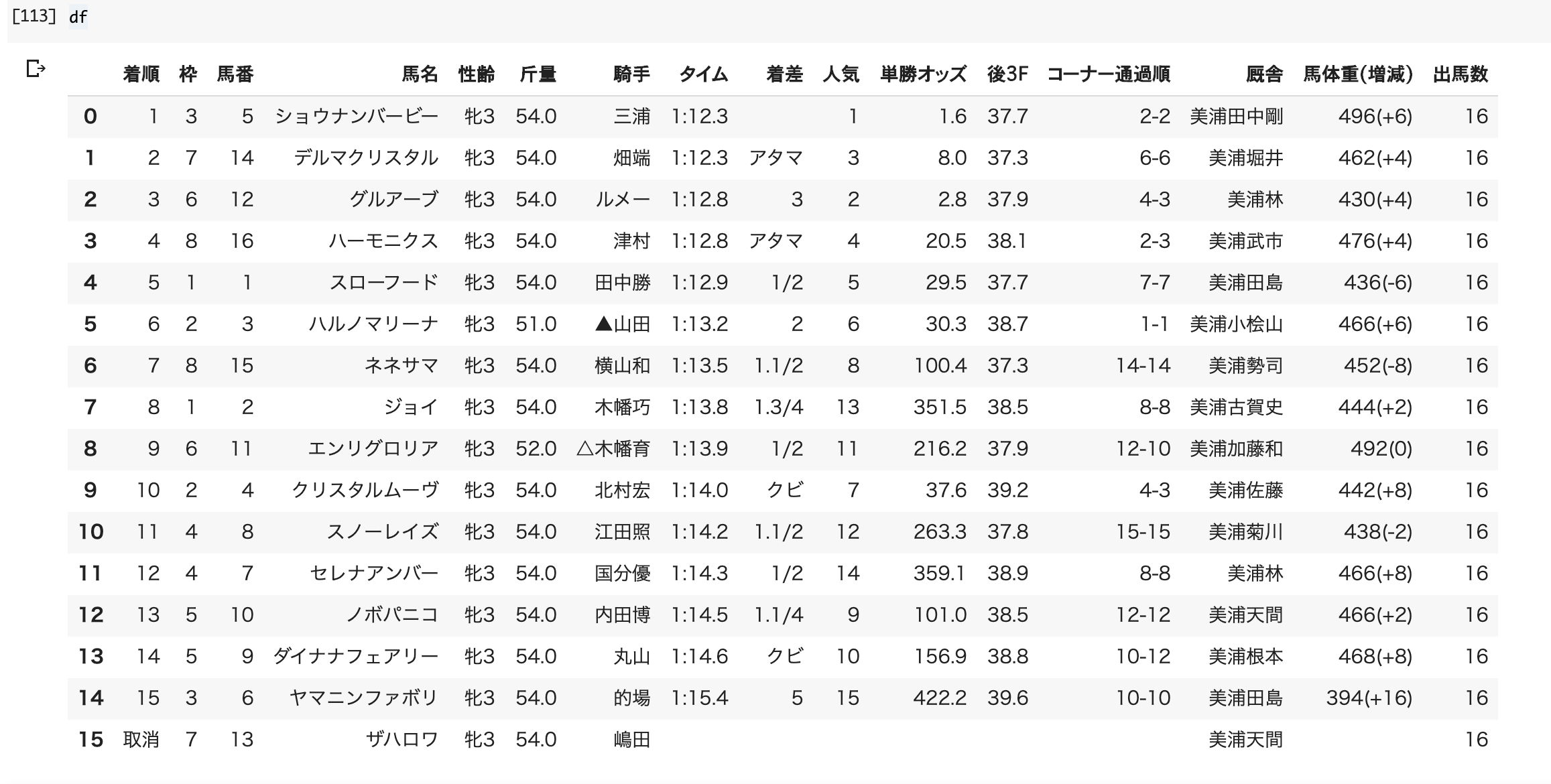
# 表の横列の数=15("着順,枠,馬番,馬名,性齢,斤量,騎手,タイム,着差,人気,単勝オッズ,後3F,コーナー通過順,厩舎,馬体重(増減))
col = ["着順","枠","馬番","馬名","性齢","斤量","騎手","タイム","着差","人気","単勝オッズ","後3F","コーナー通過順","厩舎","馬体重(増減)","出馬数"]
# 出馬数をカウント
uma_num = len(HorseList)
df_temp = pd.DataFrame(map(make_data,HorseList),columns=["temp"])
df = df_temp["temp"].str.split("'", expand=True)
df.columns= col
df["出馬数"] = uma_num
df
最後に
あとは日付などを変えていけばたくさんスクレイピングできます。
環境構築もいらないColaboratoryはやっぱり便利ですね。
参考
https://qiita.com/Mokutan/items/89c871eac16b8142b5b2
https://qiita.com/ftoyoda/items/fe3e2fe9e962e01ac421