はじめに
Azure Synapse Analytics の serverless SQL pool で CSV ファイルを OPENROWSET 関数を使い参照する際、これまでは WITH 句で列名とデータ型を明示的に指定する必要がありました。
例えば、以下の CSV ファイルがあったとして、
ID,Name,Grade,Birthday
1,鈴木,2,2003年2月24日
2,田中,1,2004年5月16日
3,佐藤,2,2003年4月15日
4,山田,3,2002年6月20日
5,加藤,3,2002年10月1日
6,中村,2,2003年8月28日
7,三浦,1,2004年12月3日
OPENROWSET 関数を使った SQL 文は次のようになります。
SELECT TOP (100) *
FROM OPENROWSET
(
BULK 'https://xxx.blob.core.windows.net/xxx.csv'
, FORMAT = 'CSV'
, FIRSTROW = 2
)
WITH
(
[ID] SMALLINT,
[Name] varchar(10),
[Grade] SMALLINT,
[Birthday] varchar(20)
) AS DATA_RESULT;
GO
スキーマの自動検出
これまでは上記の書き方しかできなかったのですが、直近のアップデートでスキーマの自動検出機能が追加され、WITH 句を省略した場合に列名とデータ型を自動で推論してくれるようになりました。構文は以下のとおりです。
SELECT TOP (100) *
FROM OPENROWSET
(
BULK 'https://xxx.blob.core.windows.net/xxx.csv'
, FORMAT = 'CSV'
, PARSER_VERSION = '2.0'
, HEADER_ROW = TRUE
)
AS DATA_RESULT;
GO
PARSER_VERSIONに 2.0 を指定した上で、CSV ファイルにヘッダ行がある場合はHEADER_ROWに TRUE、無い場合は FALSE を指定します。クエリの実行結果は以下のようになり、WITH 句を指定した場合と同様の結果が取得できていることが確認できます。
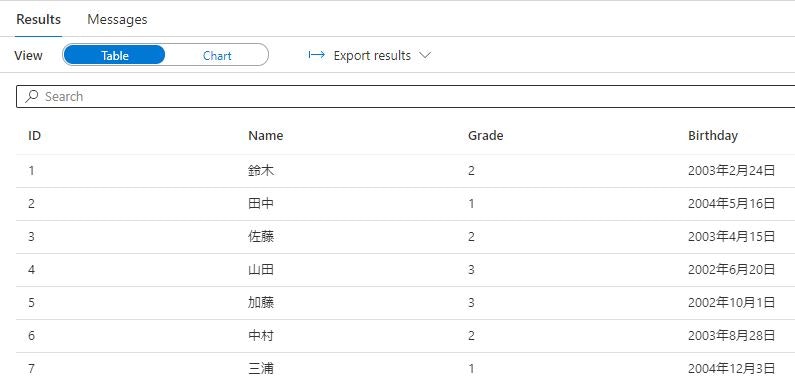
推論されたデータ型の確認
スキーマの自動検出機能で推論されたデータ型が何であるかを確認したい場合はsp_describe_first_result_setシステムストアドプロシージャを使用します。SQL 文としては以下のようになります。
EXEC sp_describe_first_result_set N'
SELECT TOP (100) *
FROM OPENROWSET
(
BULK ''https://xxx.blob.core.windows.net/xxx.csv''
, FORMAT = ''CSV''
, PARSER_VERSION = ''2.0''
, HEADER_ROW = TRUE
)
AS DATA_RESULT';
GO
実行結果のSystem_type_name列から推論されたデータ型が確認できます。
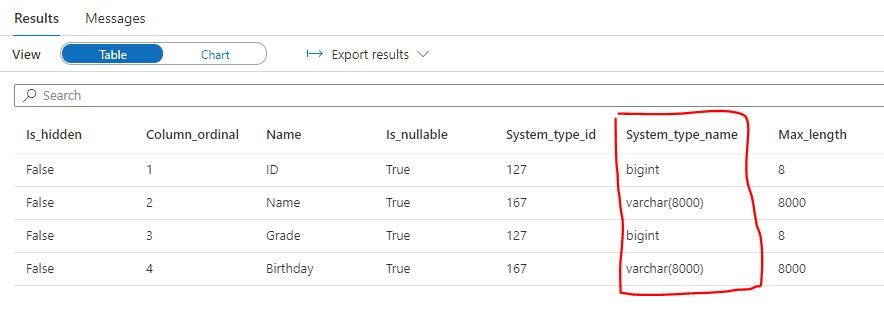
今回試した結果では数値データで bigint が、文字データで varchar(8000)がそれぞれ使用されており、比較的大きなデータ型が使用されている印象を受けます。これについては Microsoft Docs に以下のような記載があります。
情報不足のために適切なデータ型を推論できず、代わりにより大きいデータ型が使用される場合もあります。 この場合、パフォーマンスのオーバーヘッドが発生します。特に、varchar (8000) として推論される文字型の列で大きな影響があります。 最適なパフォーマンスを得るには、推論されたデータ型を確認し、適切なデータ型を使用してください。
引用元:Azure Synapse Analytics でサーバーレス SQL プール (プレビュー) を使う際の OPENROWSET の使用方法-スキーマの自動検出
使用した CSV ファイルのデータ件数が少なかったため、推論が上手くいっていなかった可能性があるようにと思われます。
所感
業務上、列数の多い CSV ファイルを取り扱うことも多いため、今回実装されたスキーマの自動検出機能で WITH 句の記述が省略できるのは、 serverless SQL pool を使っていく上で非常に有用に感じられます。
一方で、データによっては推論された型の妥当性を自分で判断したり、自動検出されたものを使わず WITH 句で明示的に型指定しなければならないケースもあり得ますので、この辺りはデータの特性に応じて適宜使い分けていけると良いのかなと思います。