はじめに
Azure Data Factory の GUI ベースのデータフローには「マッピングデータフロー」と「ラングリングデータフロー」という大きく 2 つの機能があります。両者の詳細な違いは割愛しますが、ラングリングデータフローは Power Query Online をベースとしており直感的にデータ操作が定義できるという特徴を持っています。
Azure Synapse Analytics においてはこれまでマッピングデータフローのみが提供されており、Microsoft Docs の記載もそのようになっているのですが、2020 年 10 月時点で Synapse Studio からラングリングデータフローが定義・実行できるようになっていたため、一通り試してみた結果をご紹介します。
データ紹介、事前準備
機能を試すにあたり、2 つの CSV ファイルを用意しました。一つは生徒情報を記したもの(student.csv)、もう一つが生徒の試験結果(score.csv)を記したものです。両データをラングリングデータフローで加工することで、生徒ごとの成績や順位付けを行ってみます。
ID,Name,Grade,Birthday
1,Suzuki,2,2003/2/24
2,Tanaka,1,2004/5/16
3,Sato,2,2003/4/15
4,Yamada,3,2002/6/20
5,Kato,3,2002/10/1
6,Nakamura,2,2003/8/28
7,Miura,1,2004/12/3
Subject,ID,Score
English,1,42
English,2,22
English,3,73
English,4,52
English,5,54
English,6,57
English,7,13
Chemistry,1,48
Chemistry,2,60
Chemistry,3,21
Chemistry,4,64
Chemistry,5,26
Chemistry,6,58
Chemistry,7,56
Mathematics,1,75
Mathematics,2,40
Mathematics,3,74
Mathematics,4,57
Mathematics,5,98
Mathematics,6,84
Mathematics,7,25
2 つの CSV ファイルは ADLS Gen2 に格納しておき、後続の手順で Synapse Studio からデータソースとして定義できるようにしておきます。
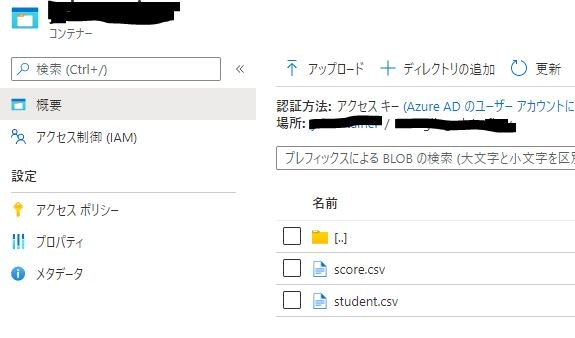
データフローの作成
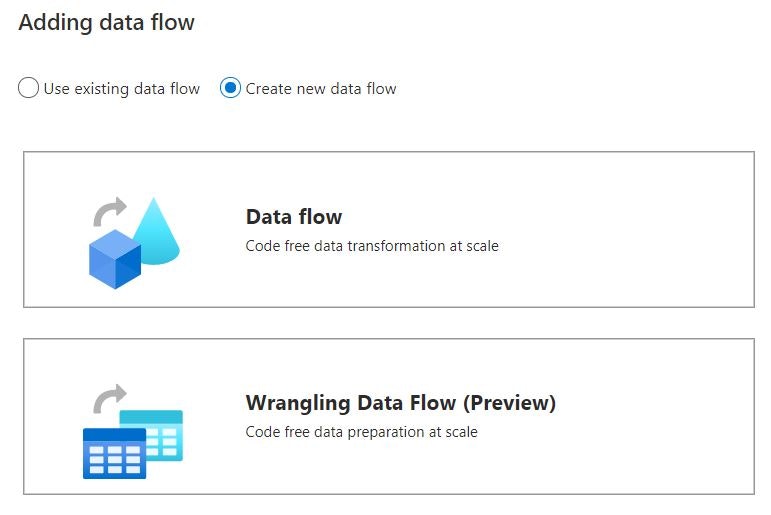
Synapse Studio の Integrate タブ(旧 Orchestrate タブ)から新しいパイプラインを作成し、Activities で Data flow をドラッグすると 2 種類の選択肢が表示されますので、下部の「Wrngling Data Flow (Preview)」を選択します。
Source と Sink のデータセットをそれぞれ定義します。必須なのは Source 側のみですが、Sink が無いと Publish する際にエラーになるので同時に定義しておいたほうが効率的かと思います。
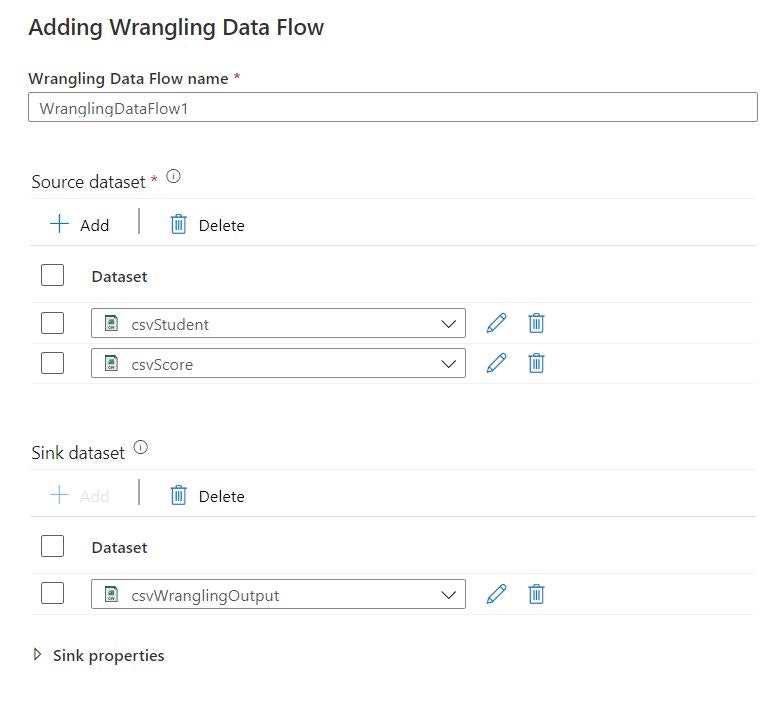
データセットは新規に作ることも既存のものを使うこともできます。今回は、あらかじめ作成したおいたものを作っていますが、作成・定義に当たりいくつか制約がありエラーも出たため、気が付いたことを記します。
- Sink のデータセットとして定義できるのは ADLS Gen2 上の CSV ファイルのみ
- ADLS Gen2 への認証方式は「Account Key」か「Serivce Principal」のいずれかのみが対応
データセットの定義後、画面上にマッシュアップ エディターが表示されていれば OK です。
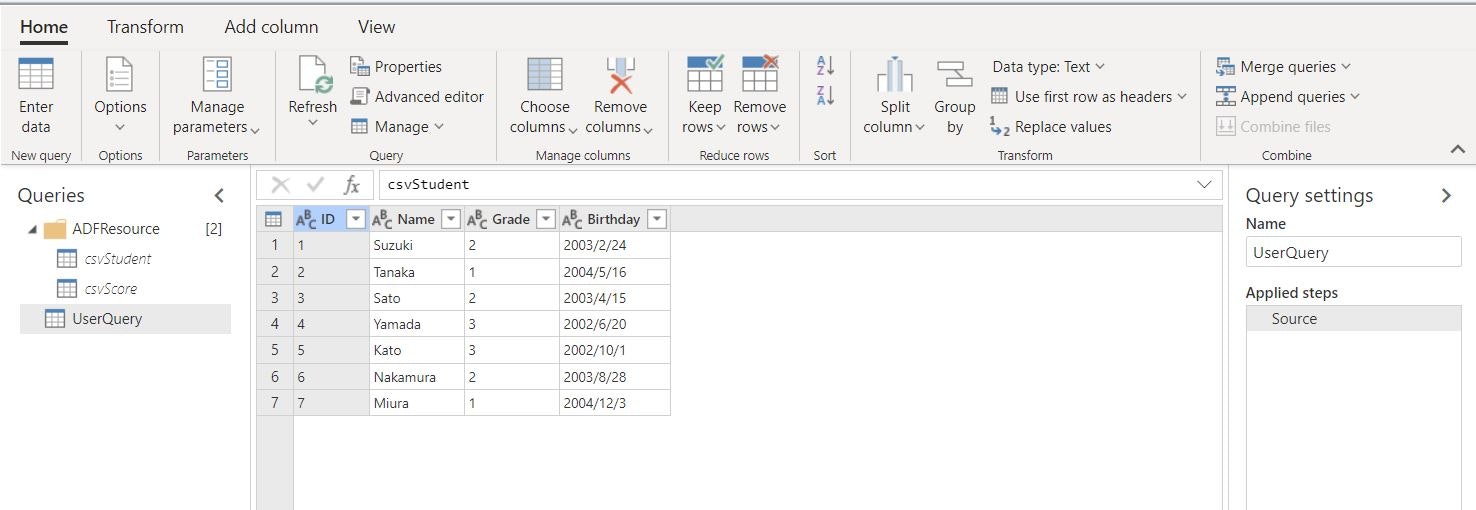
使ってみる
必要な準備が整いましたので、ラングリングデータフローによるデータ変換を実施してみます。本稿執筆時点ではデータ変換で使用できるのは、Power Query M 関数の中の一部関数のみとなります。
上記に記載されている関数を、マッシュアップエディターを使って画面上で試してみます。
列の管理
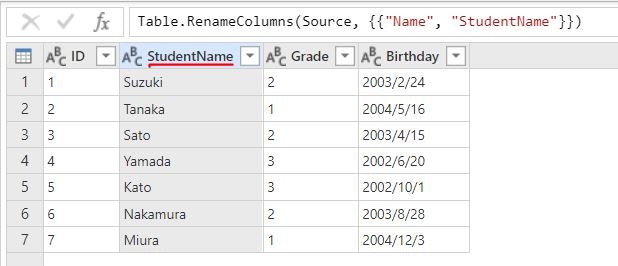
ヘッダーをダブルクリックすることで、列名を変更できます。Name 列を StudentName 列に変更しました。
行のフィルタリング
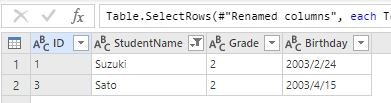
ヘッダーの「▼」から「Text filters」-「Begins with」と辿り、戦闘が S で始まる生徒名のみを抽出しました。

列の追加と変換
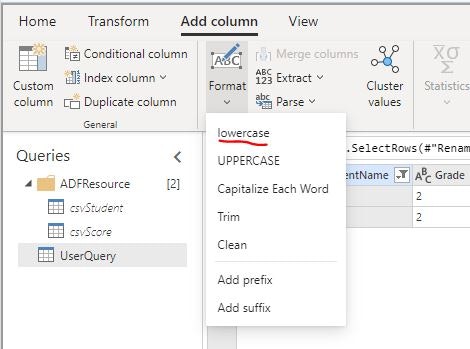
StudentName 列を選択した状態で Transform タブの「Add column」-「losercase」をクリックし生徒名が小文字に変換された列を追加しました。

テーブルのマージ/結合
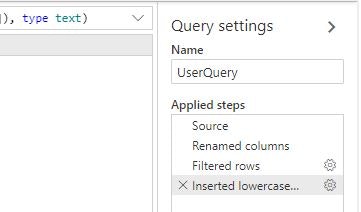
本作業の前に、ここまでの変換処理を一度リセットします。エディター右の「Applied steps」で「×」を押すことで各処理をリセットできますので、初期状態まで戻します。
初期状態まで戻った後に「Merge queries」をクリックします。結合するテーブルとして「csvScore」を選択し、結合用のキーとして ID 列を選択しておきます。Join は何でも良いですが、今回は「Inner」を選択しておきます。
csvScore 列が Table 形式で追加されていれば Join 成功です。ドキュメントには書かれていますが、結合直後はテーブルが入れ子の状態となっているため、ここから手動で列を展開します。
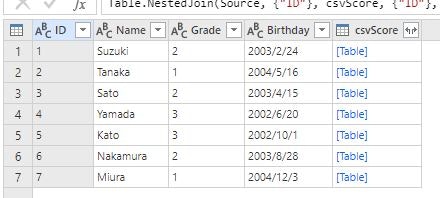
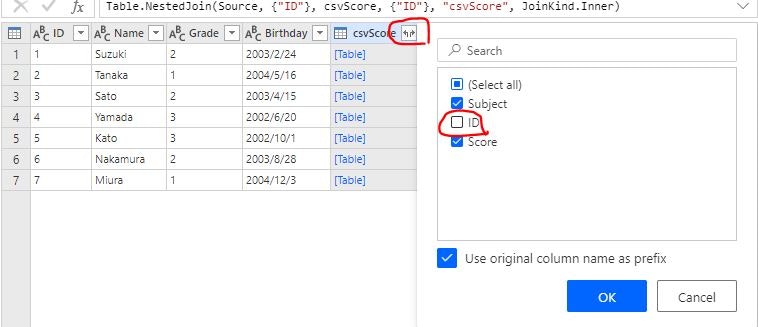
列ヘッダーのボタンをクリックし、結合キーである ID 列のチェックを外すと、その他の列が展開されます。
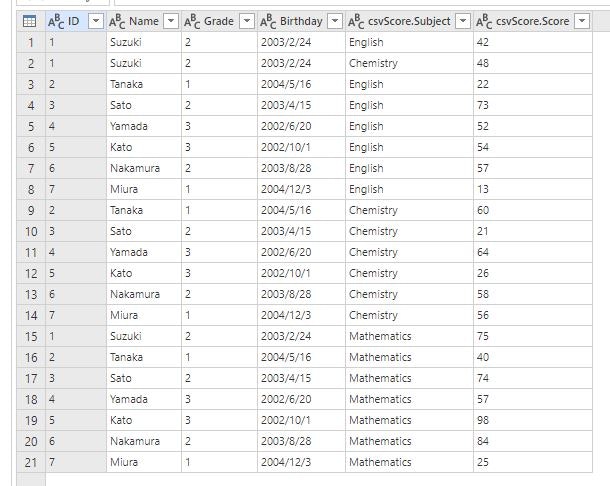
結合結果として、生徒 7 名の試験 3 科目のスコア合計 21 件のデータが取得できていることが確認できました。
グループ化
結合結果から、各生徒の 3 科目平均点を算出してみます。前準備として計算する列を数値データに変換するため、csvScore.Score 列を右クリックし「Change type」-「Whole number」をクリックして変換処理を行っておきます。

エディターで「Group by」をクリックし、ID 列で集計し csvScore.Score 列の Average を算出します。
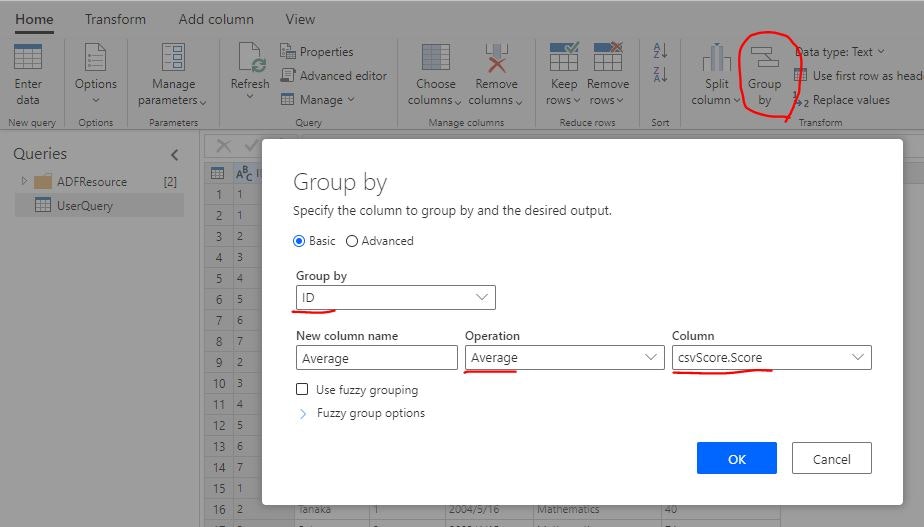
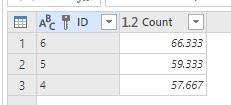
各生徒の 3 科目平均点を算出されたことが確認できました。
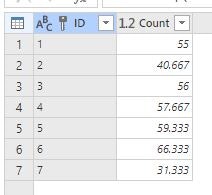
並べ替え
集計列を選択した状態でタブの「Sort」をクリックすることで、平均点の高い生徒の降順に並べ替えました。
行の削減
タブの「Keep rows」-「Keep top rows」をクリックし 3 を入力することで、上位 3 行を除く下位の行を削除しました。
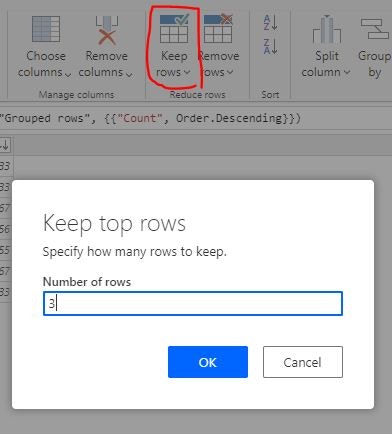
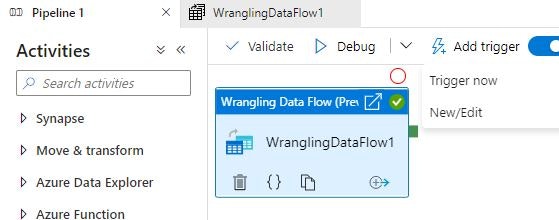
ジョブの実行
ここまででドキュメントに記載されている変換関数を一通り試しました。変換結果についてはマッピングデータフローと同様に Pipeline 画面で実行し、Monitor ハブで結果を確認することができます。
なお、前述の通り現在ラングリングデータフローで利用できる Power Query M 関数は一部のみです。マッシュアップエディター上で変換ができているように見えていても、Pipeline 実行時にエラーとなるケースなどもあるため、利用時にはやりたい変換処理が対応しているかドキュメントをよく読み、こまめにデバッグされることをオススメします。
まとめと所感
Azure Synapse Analytics の ラングリングデータフローを使ったデータ変換をご紹介しました。機能面でマッピングデータフローと類似する点も多くどちらを選択するか悩むケースもあるかもしれませんが、ラングリングデータフローの強みはやはりPower Query Online と統合されたマッシュアップエディターを有しているという点にあるかと思います。これはつまり、
- 変換処理の大半をノンコーディングで直感的に行える
- Power Platform 経験者は Power Query Online の知識を再利用できる
という恩恵を受けられることを意味し、非常に強力な機能であるといえます。 Power Query M 関数の対応はまだこれからですが、現状でも十分な使い勝手を有していますので、ご興味ある方はぜひお試しいただければと思います。