はじめに
@arai-jin さんの以下の記事で、PySpark を使ったスライディングウィンドウによる特徴量計算の方法が紹介されています。
Azure Synapse Analytics には データフローという GUI ベースの ETL 機能が備わっており、これも内部的には Spark の実行環境が動いています。ウィンドウ変換機能なども有しているため、今回は データフローを使いノンコーディングで処理が定義・実行できるかを試してみたいと思います。
なお、以降の記述において元記事と比較した内容・表現も出てくるため、元記事をまだご覧になっていない方はぜひ事前にご一読ください。それぞれの理解がより深まるかと思われます。
事前準備
以下を事前に済ませておきます。後半の 2 つについては、少し補足させていただきます。
- Synapse Workspase の作成
- 作成した Synapse Workspase へ Synapse Studio でログイン
- テスト用CSV ファイルの作成
- 作成した CSV ファイルを ADLS Gen2 にアップロード
CSV ファイルの作成
元記事と同じデータの CSV ファイルを、今回も作成・使用します。
time,data1,data2,data3,data4
1,2.65,2.42,6.9,4.93
2,2.57,8.5,2.4,5.37
3,2.13,3.76,7.52,7.67
4,3.09,7.28,3.59,6.34
5,5.75,4.69,5.26,3.11
6,6.91,4.04,2.03,6.28
7,5.44,3.22,2.87,7.14
8,4.86,7.47,3.68,0.32
9,9.7,7.43,4.43,7.74
10,6.3,7.72,7.78,7.91
作成した CSV ファイルを ADLS Gen2 にアップロード
正確には、データフロー上で Datasets として認識できれば何でも良いのですが、今回は作成した Synapse Workspase で Primary アカウントとして設定している ADLS Gen2 上に CSV ファイルをアップロードしておきます。
データフローの作成
ここから、本筋の設定に入っていきます。まずは、Synapse Studio の Develop Hub でData flowをクリックします。

Add Sourceをクリックすると、以下の画面になります。今回は Datasets を新規作成するためNewをクリックします。

Azure Data Lake Storage Gen 2を選択してContinueをクリック。

Delimited Textを選択してContinueをクリック。

アップロードした CSV ファイルが読み込めるよう、Linked serviceとFile pathを適切に設定。また、今回はヘッダー付きの CSV ファイルであるため、First row as headerにチェックを入れておきます。

CSV ファイルが読み込めると、Projection タブでスキーマが確認できます。デフォルトでは全ての列が string ですが、後続の処理のため time 列をinteger、data1 列をfloatにそれぞれ変換しておきます。今回はテストデータの都合で time 列を integer としていますが、実データでは timestamp 型とした方がよろしいかと思います。

設定が正常に完了すれば、Data preview タブで CSV ファイルのデータが確認できます。

ウィンドウ変換
ここまでの作業が完了したら、画面の+アイコンからWindowをクリックしウィンドウ変換用の処理を追加します。

Window settings タブにおける1. Overを除く 2.から 4.を順に設定していきます。

2. Sort
ソートキーを指定するもので、PySpark におけるorderBy("カラム名")の記述に相当します。そのため、ここでは time 列を指定します。

3. Range by
ウィンドウ幅を指定するもので、PySpark におけるrowsBetweenの記述に相当します。幅の指定をスライダーと数値入力で行うのが特徴で、まずスライサーの左端をCurrent rowにすることで Start offset が 0、つまり現在行を基準にします。次に右端をIn frontとし End offset に 4 を入力することで現在行を含めて 5 行を 1 つのウィンドウとして定義することになります。

4. Window columns
特徴量抽出の結果を新しい列として定義します。PySpark におけるwithColumn('feat_max_data1', F.max('data1').over(sliding_window))といった記述に相当します。PySpark 同様、こちらでも計算の種類の数だけ列を定義する必要があります。

なお、本記事では深くは触れませんが、特徴量抽出で使う関数の記述においては式ビルダーを使うことで入力補助を受けながら記述することが可能となっています。
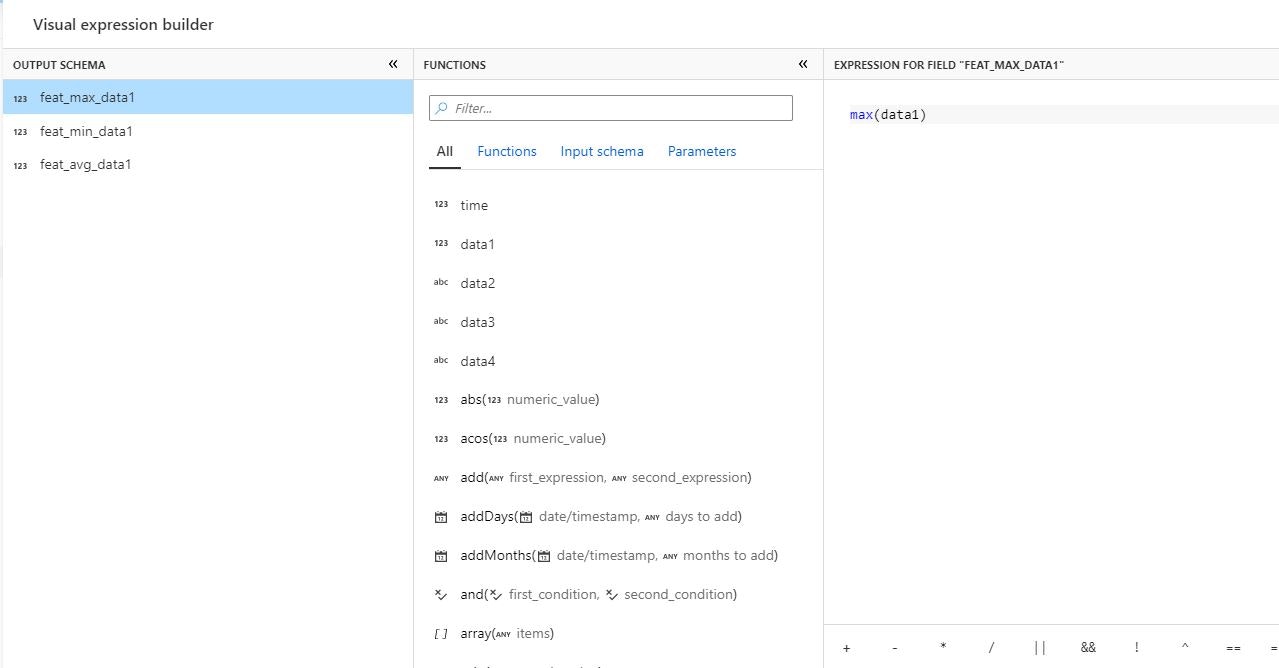
結果確認
ウィンドウ変換の処理後、Data preview タブで特徴量抽出の結果を確認することができます。画面では見やすくするため後続に Select 処理を加えて data2 ~ 4 を省いていますが、変換処理の結果自体は Window 処理の時点で確認可能です。

まとめ
Azure Synapse Analytics のデータフローを使うことで、スライディングウィンドウによる特徴量計算がノンコーディングでできることを確認しました。
データサイエンティストの方であれば慣れ親しんだPythonでコーディングするだけかもしれませんが、今回のような特徴量抽出は案件の体制によってはデータエンジニアやクラウドアーキテクトが担当することも考えられ、そういった人々にとってはPySpark相当の処理をGUIを使ってノンコーディングで定義・実行できるというのは魅力的ではないかと思います。