センサなどから得られる時系列データから、
tslearnを使ってパターンマッチングをやってみたいと思います。
事前準備
- anaconda3環境
conda install -c conda-forge tslearn- Jupyter Notebook
https://github.com/rtavenar/tslearn
https://tslearn.readthedocs.io/en/latest/index.html
DTW
DTWを使って時系列データ同士の類似度を算出します。
まず、波形データとして、下記のような2種類のデータを用意します。
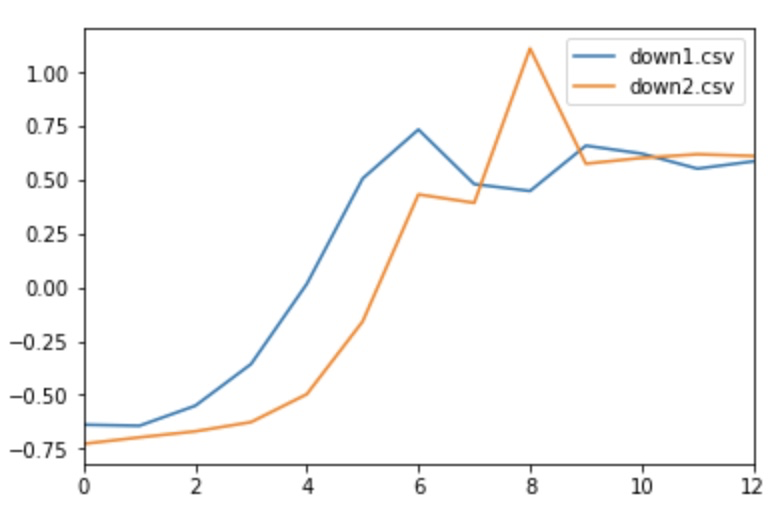
これらの波形の類似度を計算してみます。
import numpy as np
import pandas as pd
from tslearn.preprocessing import TimeSeriesScalerMeanVariance
from tslearn import metrics
from tslearn.utils import to_time_series_dataset
from pandas import DataFrame, Series
csv_file_names = ['down1.csv', 'up1.csv']
def generate_df(csv_file_names):
df = pd.DataFrame()
for i, file_name in enumerate(csv_file_names):
csv = pd.read_csv(file_name, header=None)
df[file_name] = csv[1]
return df
df = generate_df(csv_file_names)
scaler = TimeSeriesScalerMeanVariance(mu=0., std=1.)
t = scaler.fit_transform(np.nan_to_num(to_time_series_dataset(df.values.T)))
path, sim = metrics.dtw_path(t[0], t[1])
### DTW 距離
sim
出力が下記となり、0に近ければ近いほど類似度が高くなります。
0.9090998233320118
では、少し異なる波形を比べてみます。
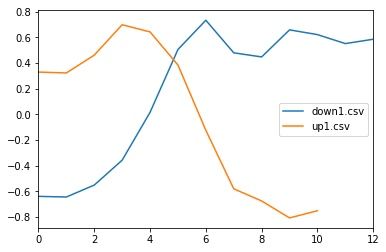
この場合、距離は下記になります。
5.773573185101321
以前は、ライブラリではなく、いちからDTWの実装していましたが、手軽になりましたね。
参考:
https://tslearn.readthedocs.io/en/latest/gen_modules/metrics/tslearn.metrics.dtw.html
あとがき
時系列データのクラスタリングについて書こうと思いましたが、
また別の機会にしようと思います。
時系列データのクラスタリングに関する参考記事