はじめに
こんにちは。仕事で昨年末から機械学習が必要になり勉強しているのでQiitaにアウトプットしてみます。どうせなら人の役に立つことを、と思い色覚異常を持つ方のサポートになるかもしれないことにトライしてみました。
背景
焼肉で肉が焼けてるかどうか区別がつかない?
みなさん、色覚異常という言葉を聞いたことがありますか?Wikipediaで調べてみると、次のような説明がされています。
色覚異常(しきかくいじょう)とは、ヒトの色覚が正常色覚ではない事を示す診断名である。「色盲」などとも呼ばれ、2017年9月頃からは、「色覚多様性」とも呼ばれるようになった。正常色覚とされる範囲は、眼科学によって定義される。要因が先天性である場合を先天性色覚異常、後天性である場合を後天性色覚異常と分類する。先天性色覚異常を持つ人は、日本においては男性で約5%、女性で約0.2%の割合であるが、フランスや北欧では男性で約10%、女性で約0.5%であり、アフリカ系の人では2~4%程度である。
端的にいうと、色覚異常を持つ人はそうでない人と比べて色の区別がしづらい。先天性色覚異常を持つ人の割合は日本の男性で約5%、フランスや北欧では男性は約10% 思っていたより多い割合、意外と身近なのかもしれませんね。
色の区別がしづらいために、生活していて困ることがそれなりにあるらしいです。たとえば私の知り合いの知り合いで色覚異常を持つ人は、焼肉で肉が焼けたかどうか区別がつかないことが一番困るとのことです。調べてみると下記のような比較画像を発見しました。色覚異常を持つ人は右のように見えるらしいです。確かにこれだと肉が焼けてるのかどうか区別がつかないですね。

(滋賀医科大学 眼科学講座から引用)
機械学習を使って肉が焼けたかどうか判定できたらOK?
肉が焼けたかどうかわからないと、次のような負があることが想像できます。
- 焼けた肉を自分が食べる前に他の人に食べられてしまう
- 肉が焼けてない状態で食べてしまい、食中毒になる恐れがある
- 「この肉焼けた?」といちいち人に聞くのが面倒
もし肉が焼けたかどうか判定してくれるアプリがあったらこの負を解消できますね。今回はそのファーストステップとして、機械学習を使って肉が焼けたかどうかを判定できるのか?にトライしてみました。
目次
- はじめに
- 背景
- まずは機械学習とお友達に
- 機械学習?なにそれおいしいの?
- ディープラーニング?なにそれおいしいの?
- Qiitaにアウトプットだ
- 実際にやってみた
- 何はともあれデータ収集
- シンプルなCNNを用いて分類してみる
- データ拡張とドロップアウトを使ってみる
- 転移学習してみる
- さぁどうしよう?
- 再度チャレンジしてみた
- シンプルなCNNを用いて分類してみる
- いや待てよ、、、
- 学習用データとテスト用データの質を揃える
- おわりに
まずは機械学習とお友達に
機械学習?なにそれおいしいの?
私が開発にかかわっているSmoozというスマホブラウザでは、ユーザーが今読んでいるウェブページの内容を解析し記事をおすすめする機能を今年の4月にリリースしました。昨年末にその機能を開発しはじめましたが、私はそのころ機械学習とは疎遠だったので開発初期の打ち合わせにいた機械学習エンジニア達が何を会話しているのか全くわからない。ランダムフォレストという言葉を初めて聞いたのもその打ち合わせでした。これではまずい、とネットで調べて色々写経してみますがどれも断片的な情報ばかり。Courseraの機械学習のコースがいいらしいと聞いたので受講し始めてみるも時間が取れず挫折。ふぁーーーーとなっていたところにAidemyというサービスがリリースされました。以前にProgateを使ってHTMLとCSSを学習し、実際に仕事で使えるレベルまで引き上げた経験があったので、オンラインでの学習にスムーズに入ることができました。実際に「Python入門」「Pandasを用いたデータ処理」「Matplotlibによるデータの可視化」などを始めとして、「機械学習概論」「教師あり学習(分類)」「自然言語処理」などのコースを怒涛の勢いで受講していきました。
ディープラーニング?なにそれおいしいの?
3年くらい前からディープラーニングを使った画像認識試してみた系の記事が私の目にも入ってき始めて、ずっと気になってはいましたが、仕事で使っていた単純なアルゴリズムの優先度が高くディープラーニングは勉強する時間がとれずでした。ですが今月からようやく時間が取れるようになったので、またもやAidemyのお世話になることに。「ディープラーニング基礎」と「CNNを用いた画像認識」のコースを受講して今に至ります。
Qiitaにアウトプットだ
せっかくなので勉強していることをQiitaに投稿してみよう。#Aidemynote という解析ブログコンテストが開催されているのでどうせならエントリーしてみよう。さぁ何をテーマにするか?
よく見かける○○してみた系の記事は「それ何の役に立つの?」ってことが多いなと思ってます。それは、ディープラーニングという技術が魅力的すぎるゆえの代償として、そういう記事が出てきしまうのかなと。「何かの問題を解決するために技術を使う」が本来あるべき姿だと思っていまして、今回のテーマにトライしてみました。
実際にやってみた
焼き肉の画像を与えると、「焼けた」か「焼けてない」か精度高く二値分類してくれるようなモデルを作ります。本当は「焦げてる」「焼けた」「片面焼けてる」「生」の四段階くらいやりたいのですが、まず今回はシンプルに、焼けたかどうかを二値分類してみます。
何はともあれデータ収集
「焼肉」とGoogle画像検索して焼けてる肉と焼けてない肉の画像をそれぞれ50枚ずつ合計100枚集めます。
焼けた肉
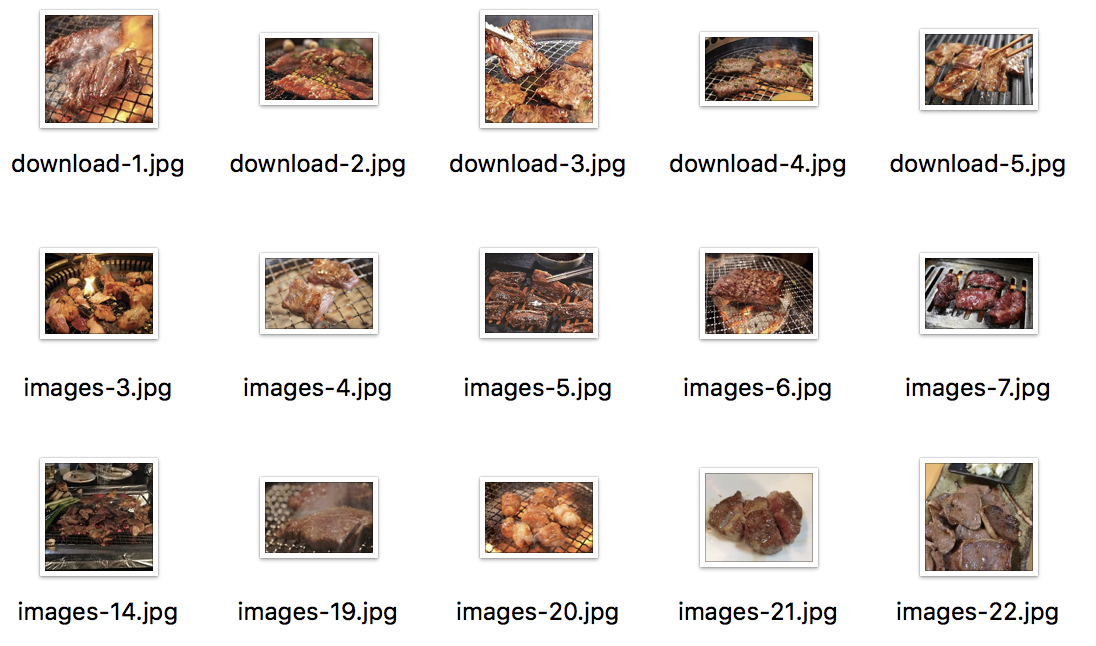
焼けてない肉
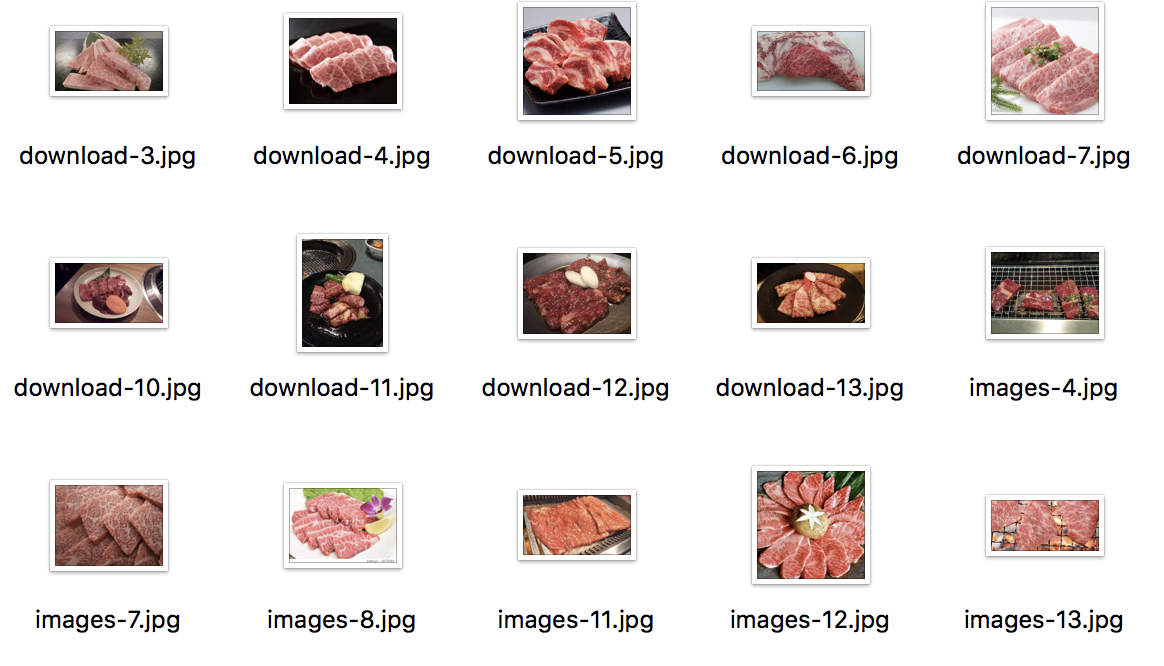
集めたデータは、下記表のようにそれぞれ学習用に35枚、テスト用に15枚に分けます。
| 状態 | 学習用 | テスト用 |
|---|---|---|
| 焼けた肉 | 35 | 15 |
| 焼けてない肉 | 35 | 15 |
シンプルなCNNを用いて分類してみる
次のようなシンプルな構造のCNNを作成し、学習させてみます。ちなみにMacでJupyter Notebookだと遅すぎてストレスフルなので、Google ColaboratoryでGPU使ってます。まだ使ったことない人は一度使ってみてください。爆速です。
model = Sequential()
model.add(Conv2D(32, (3,3), activation='relu', input_shape=(150,150,3)))
model.add(MaxPooling2D((2,2)))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(MaxPooling2D(2,2))
model.add(Conv2D(128, (3,3), activation='relu'))
model.add(MaxPooling2D(2,2))
model.add(Conv2D(128, (3,3), activation='relu'))
model.add(MaxPooling2D(2,2))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(
loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc']
)
history = model.fit_generator(
train_generator,
steps_per_epoch=20,
epochs=30,
validation_data=validation_generator,
validation_steps=10
)
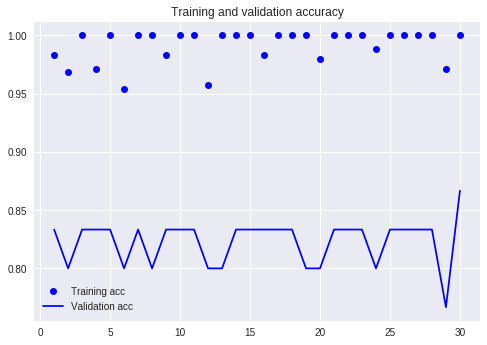
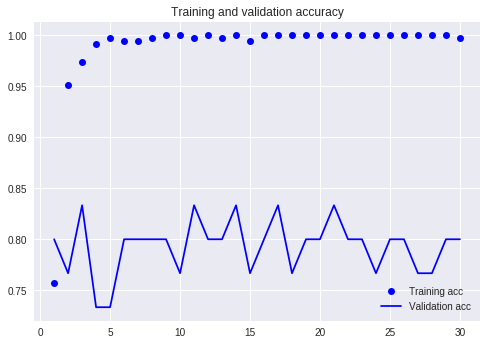
学習の結果を図示してみましましょう。ドットは学習用データでの精度を、折れ線はテスト用データでの精度を表しています。学習用データでの精度が4エポックで100%になってますね。一方でテスト用データでの精度は83%程度で頭打ち。学習用データにばかりに特化した学習がなされて過学習になっています。精度が80%というのはもしSVMとかならまぁそんなもんでしょ、って感覚なのですがディープラーニングなら最低でも95%くらいを期待してしまう。
データ拡張とドロップアウトを使ってみる
過学習を防ぎ精度をあげるために、ドロップアウトとデータ拡張を使ってみます。Aidemyでは「CNNを用いた画像認識」で学ぶことができます。
# データ拡張
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
)
# ドロップアウト層を追加
model.add(Dropout(0.5))
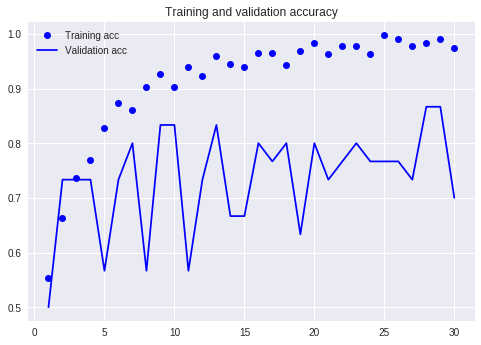
さて結果はよくなったのでしょうか?最後の方のエポックで、テスト用データでの精度が87%と、先程より3%あがりましたね。でも過学習は全然ふせげていないです。この後に、学習済みのCNNとしてVGG16を使うつもりだったのですが、この時点でこんな感じだと望み薄な気配。
転移学習してみる
望み薄ですが、一応やってみます。VGG16による特徴抽出部分の重みは更新しないようにします。転移学習もAidemyの「CNNを用いた画像認識」で学べます。
model = Sequential()
conv = VGG16(weights='imagenet', include_top=False, input_shape=(150,150,3))
conv.trainable = False
model.add(conv)
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(256, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
結果はと言うと、、、ダメですね笑
さぁどうしよう?
うわー、精度全然あがらないなー困ったなー。まずは学習用データを良く見て、データの質がどうなのか評価してみます。



- 肉の部位、厚み、形、枚数が多様
- トングが入ってたり、背景がお皿だったりアミだったり
- 焼けてる肉の中で、レアなものもあれば、焦げてる肉もある
気が付きました。学習用データの質が悪いということですね。
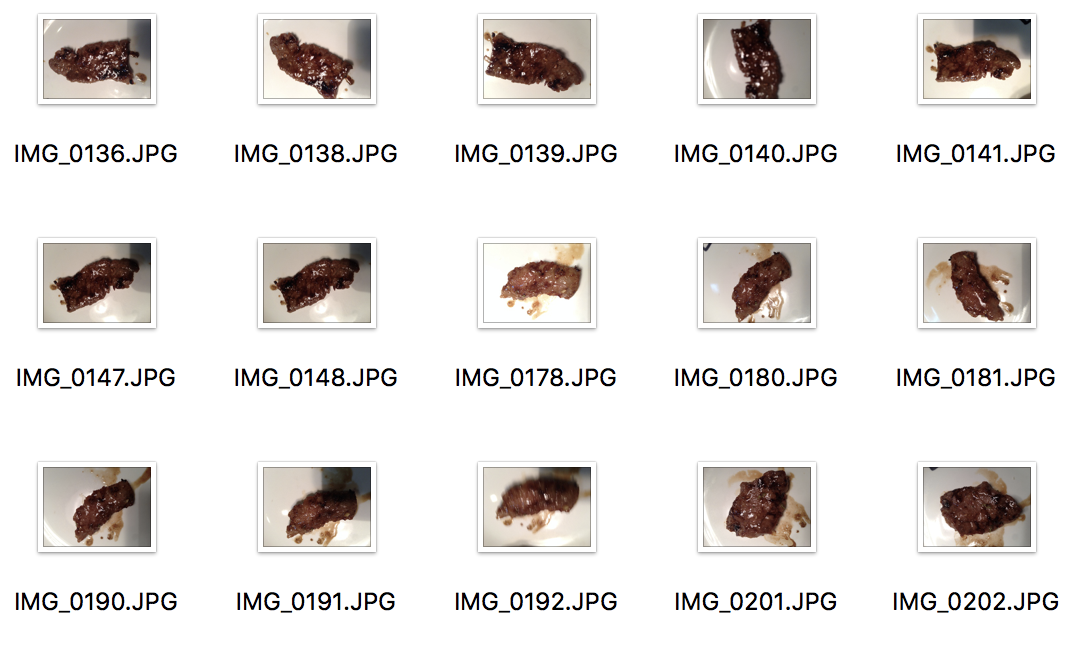
それならばということで、昨日6月29日の肉の日に牛角に行って肉を注文し、200枚ほど写真を撮影してきました!焼き肉を一枚ずつ写真を撮りまくる私の姿は素直に肉の日を楽しんでいる他のお客さん、忙しい店員さんの目に異常に映ったことでしょう。苦労の甲斐があってこんな写真がとれました。
焼けた肉
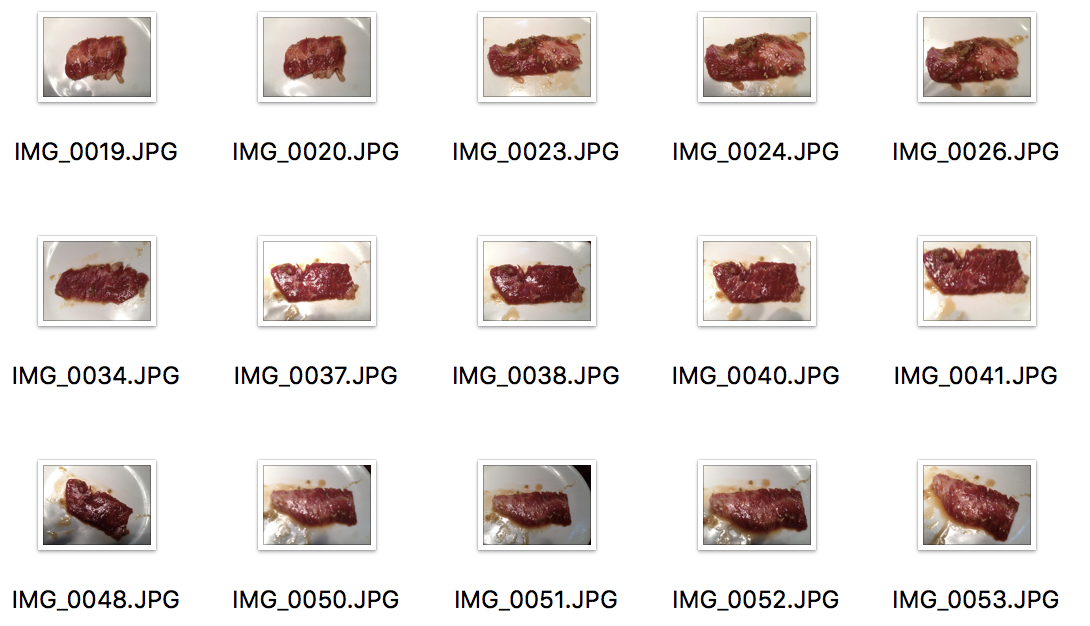
焼けてない肉
撮影は次にようにして行いました。
- 肉の種類を牛角の「プレミアム・カルビプレート 590円」に限定
- 焼けた肉、焼けてない肉それぞれ100枚ずつ撮影
- ノイズが少なくなるように背景をお皿に統一
- 一枚ずつお皿に移動させ様々な光の当たり方、アングルで撮影
- 焦がしすぎた肉は食べてほしくないので、あまり焦がさないように注意した
ちなみにこれが今回使ったお肉です。もちろん撮影の後に美味しくいただきました。

再度チャレンジしてみた
シンプルなCNNを用いて分類してみる
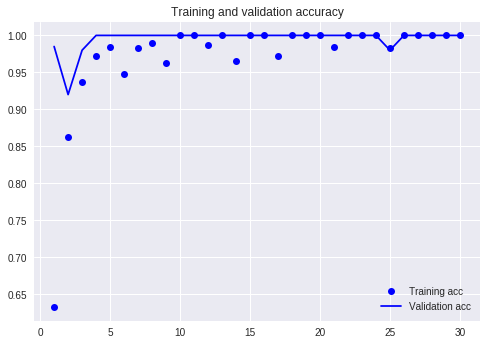
最初にやったシンプルなCNNでまずは試してみました。テスト用データの精度が100%行きましたね。あっさり結果が出てきて何も喜べない。
いや待てよ、、、
でもこれって、網の上にある肉が焼けてるかどうか判定できないといけないよな。実は網の上にある肉も少しだけ撮影してきています。ということで、下記表のように白い皿の上のお肉それぞれ70枚で学習させて、網の上のお肉それぞれ15枚でテストしてみます。
学習用データ
| 状態 | お皿の上 | 網の上 |
|---|---|---|
| 焼けた肉 | 70 | 0 |
| 焼けてない肉 | 70 | 0 |
テスト用データ
| 状態 | お皿の上 | 網の上 |
|---|---|---|
| 焼けた肉 | 0 | 15 |
| 焼けてない肉 | 0 | 15 |
全然ダメだ!過学習してるし、テスト用データでの精度は76%くらい。
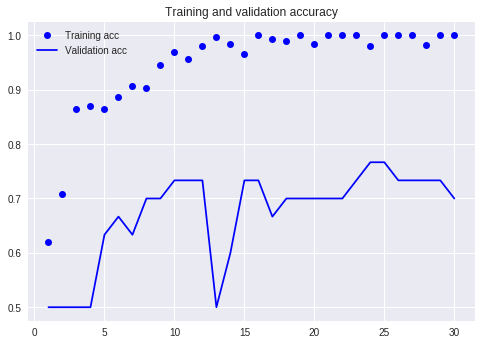
学習用データとテスト用データの質を揃える
学習用データにない画像だけが、テスト用データにでてきたのが原因ですね。質が異なるからそりゃだめになるわ。それならばと、網の上のお肉の写真それぞれ15枚のうち10枚ずつを学習用にまわします。表に整理するとこんな感じ。
学習用データ
| 状態 | お皿の上 | 網の上 |
|---|---|---|
| 焼けた肉 | 60 | 10 |
| 焼けてない肉 | 60 | 10 |
テスト用データ
| 状態 | お皿の上 | 網の上 |
|---|---|---|
| 焼けた肉 | 25 | 5 |
| 焼けてない肉 | 25 | 5 |
このデータを使い、さらにデータ拡張や転移学習を行った結果がこれ。
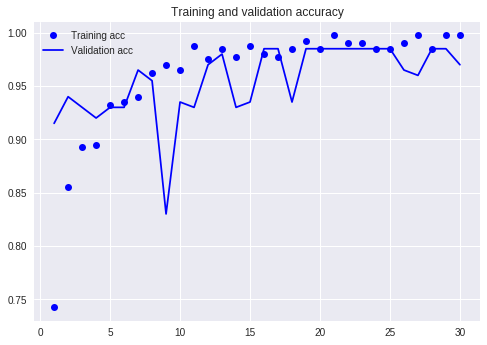
98.5%まで行くことができました。まぁよいのではないでしょうか。今回はここらで引き上げたいと思います。
おわりに
今回は機械学習を使って焼肉で肉が焼けたかどうかの二値分類にトライしてみました。この結果をうけて今後は下記のようなことを検討しています。
- 学習用データとテスト用データの質をなるべく揃える
- なるべくノイズがないようにと、お皿の上のお肉だけを学習用データに使うつもりだったのが大間違い
- 「焦げてる」「焼けた」「片面焼けてる」「生」の4状態を判定できるように
- 焼けてる焼けてないだけでなくて、少し焦げてるのが好きな人もいるだろうし
- 片面焼けてるって難易度高そう。。。
- iOSでCore MLを使ってアプリ化
- 一緒にやりたいiOSエンジニアがいたら声かけてくれると嬉しいです
- 牛角の「プレミアム・カルビプレート 590円」以外のメニューもレパートリーに加える
- 牛角にはまだまだ色々なメニューがあります。何回も行って色々なものを頼まないと。。。
- 牛角だけでなくて、叙々苑などの高級焼肉も判定できるようにする
- 叙々苑に行って色々なメニュー頼まないと、、、
- やべっ、お金かかる、、、