この記事は古川研究室 Advent_calendar5日目の記事です。
はじめに
PyTorch、Chainer、Keras、TensorFlowなど色々なフレームワークが登場し、誰でも簡単にDeep Learningが使えるようになったと言われています。
実際Deep Learningを使っている人たちからすると単に動かすだけなら簡単に思えるかもしれません。しかしDeep LearningというよりPythonをあまり使ってない人からするとメチャクチャ難しいです。
私の感覚としてはDeep Learningを動かすのは自転車に乗るのに似ていると思います。
一度、自転車に乗れた人は「自転車に乗ることなんて簡単だよ」とか「他の自転車も同じようすれば乗れるでしょ?」とか好き勝手言いますが、乗ったことない人や乗れない人からは「何言っているんだ」って感じです。
さらにDeep Learningを使う場合、下図のような感じでどこまでしたいかで求められるスキルが違いますのもDeepを使うハードルを上げている一因かと思います。
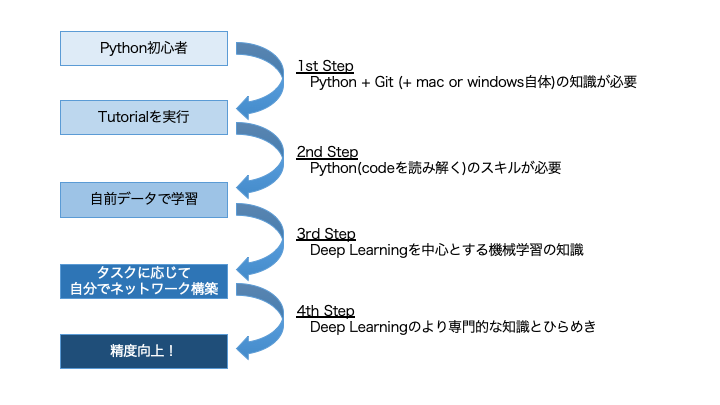
この記事ではDeep Learningと言う名の自転車に乗る手助けとして、私が実際にやった2nd Stepの道のりを解説していきます。
とりあえずDeepで物体認識をやってみる
準備
今回はChainerを使います。
そのためにChainerを入れてあげましょう。
$ pip install chainer
$ pip install chainercv
実行
以下みたいな感じで動かします。
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from chainercv.visualizations import vis_bbox
from chainercv.datasets import voc_bbox_label_names
from chainercv.links import FasterRCNNVGG16
# 使用するラベル(今回はデフォルトのやつ)
label_names = voc_bbox_label_names
# データの読み込み「'./fish/test.jpeg」は好きな画像ファイルにしてね
test_data = Image.open('./fish/test.jpg')
test_data = np.asarray(test_data).transpose(2, 0, 1).astype(np.float32)
# モデルの構築、とりあえずモデルは学習済みvoc07を使用
model_frcnn = FasterRCNNVGG16(n_fg_class=len(voc_bbox_label_names), pretrained_model='voc07')
# 予測
bboxes, labels, scores = model_frcnn.predict([test_data])
predict_result = [test_data, bboxes[0], labels[0], scores[0]]
# 結果の描画
res = predict_result
fig = plt.figure(figsize=(6, 6))
ax = fig.subplots(1, 1)
line = 0.0
vis_bbox(res[0], res[1][res[3]>line], res[2][res[3]>line], res[3][res[3]>line], label_names=label_names, ax=ax)
plt.show()
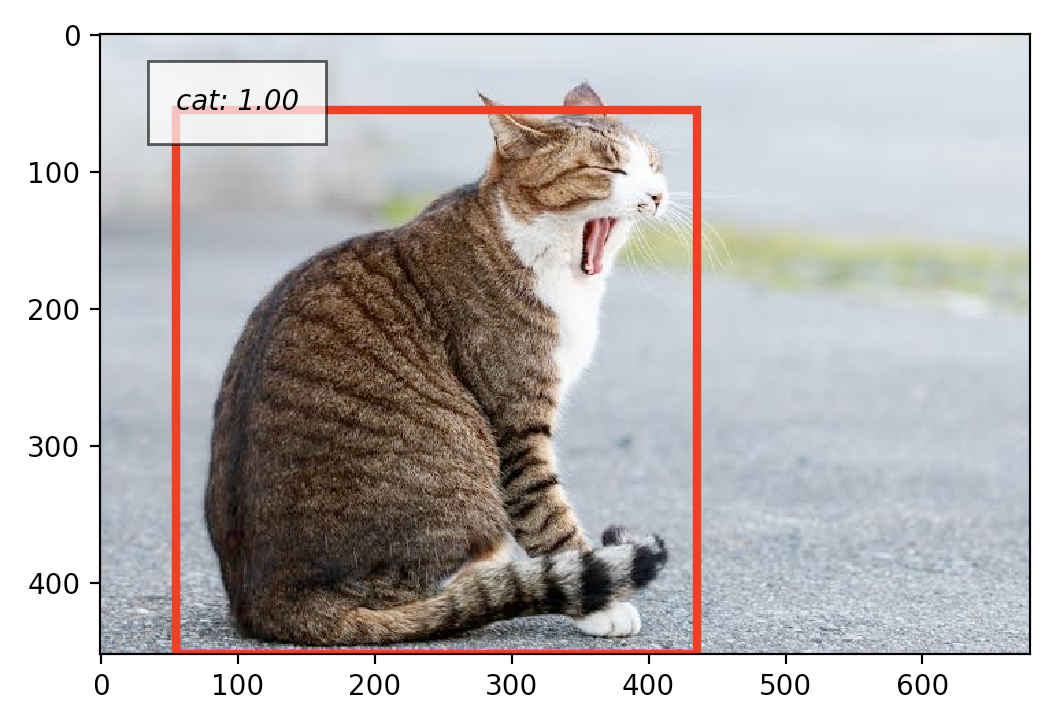
結果
うまく認識できました!
次に、のどぐろ画像を入れてやってみました。
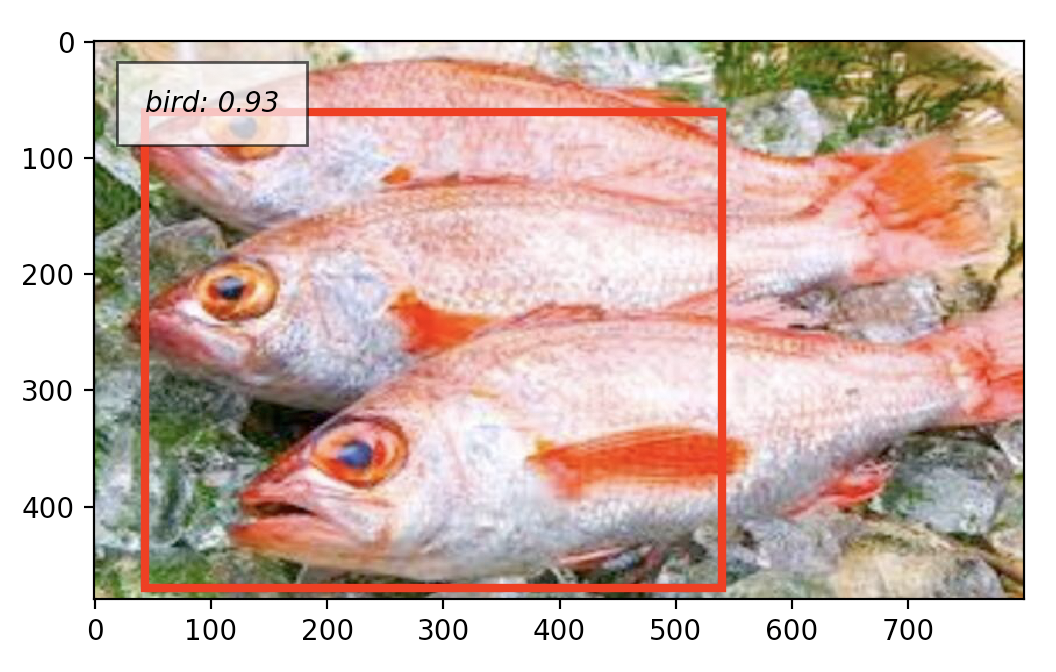
当然だけどデフォルトのままだとノドグロのラベルもないし、上手くいきません。
なのでノドグロ特化識別器のにするためにFine-turningをします。
Fine-turningの詳細な説明は飛ばしますが、要は学習済みのモデルに追加学習させる感じです。
データの準備
追加学習するにもそもそも学習データが必要なので学習データをつくりましょう。
labelImgっていうやつがおすすめです。
入れ方や使い方は↑のgithubサイトのREADMEに書いてあるので、とりあえず簡単な簡単な流れだけ説明します。
まず、labelImgを動かすために必要なやつをいれます。
$ brew install qt # Install qt-5.x.x by Homebrew
$ brew install libxml2
$ pip3 install pyqt5 lxml # Install qt and lxml by pip
$ make qt5py3
実行します。
気をつける点とかはないと思いますが、しいて言えばクローンしたディレクトリ内で操作するところですね。No such file or directoryとか出てエラーになります
$ python3 labelImg.py
labelImg.pyを実行すると以下のような画面がでます。
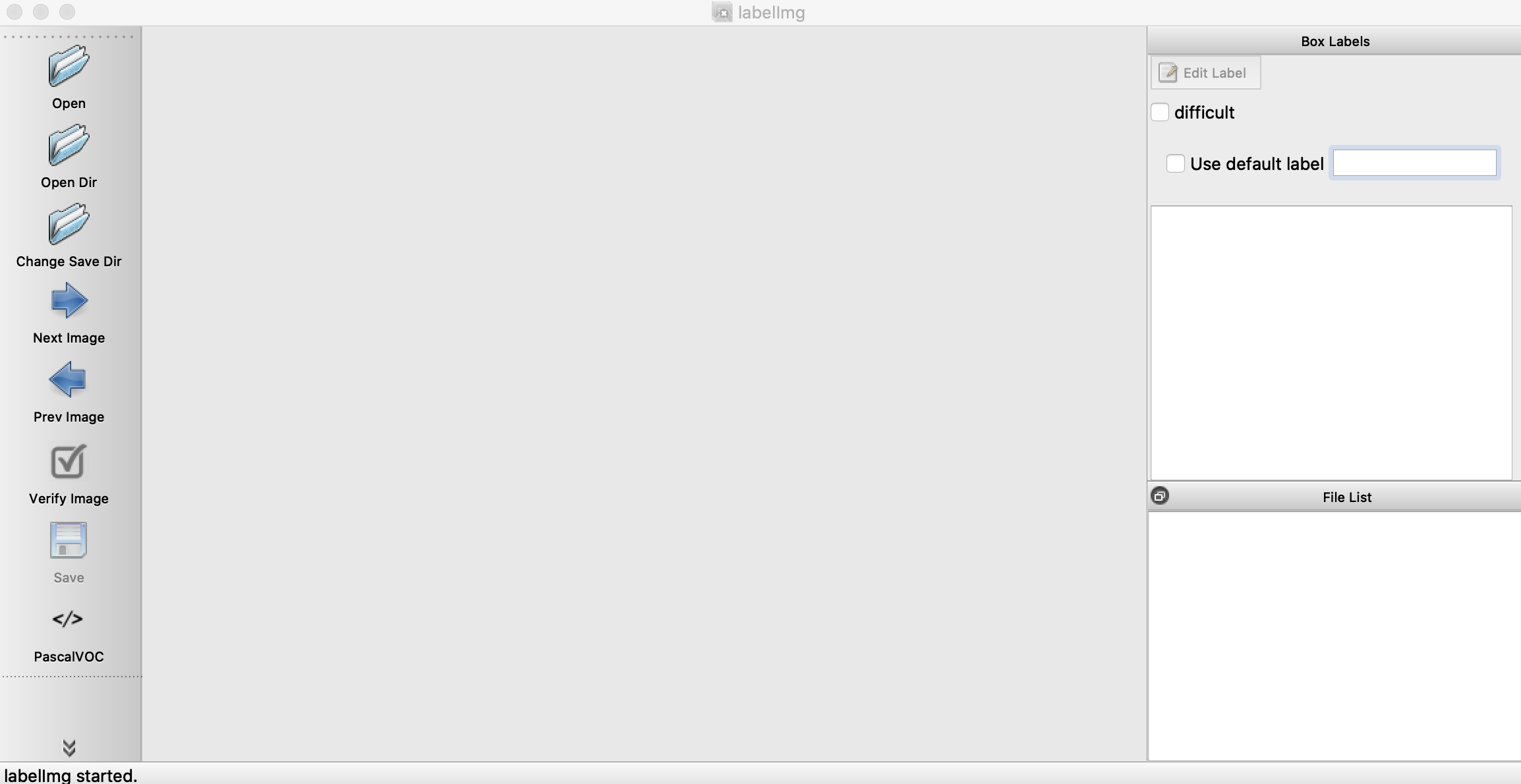
openで画像を開いて、右側のlabelに「nodoguro」って入力します
wキーを押すと範囲を選択できるので、ノドグロを選択します。
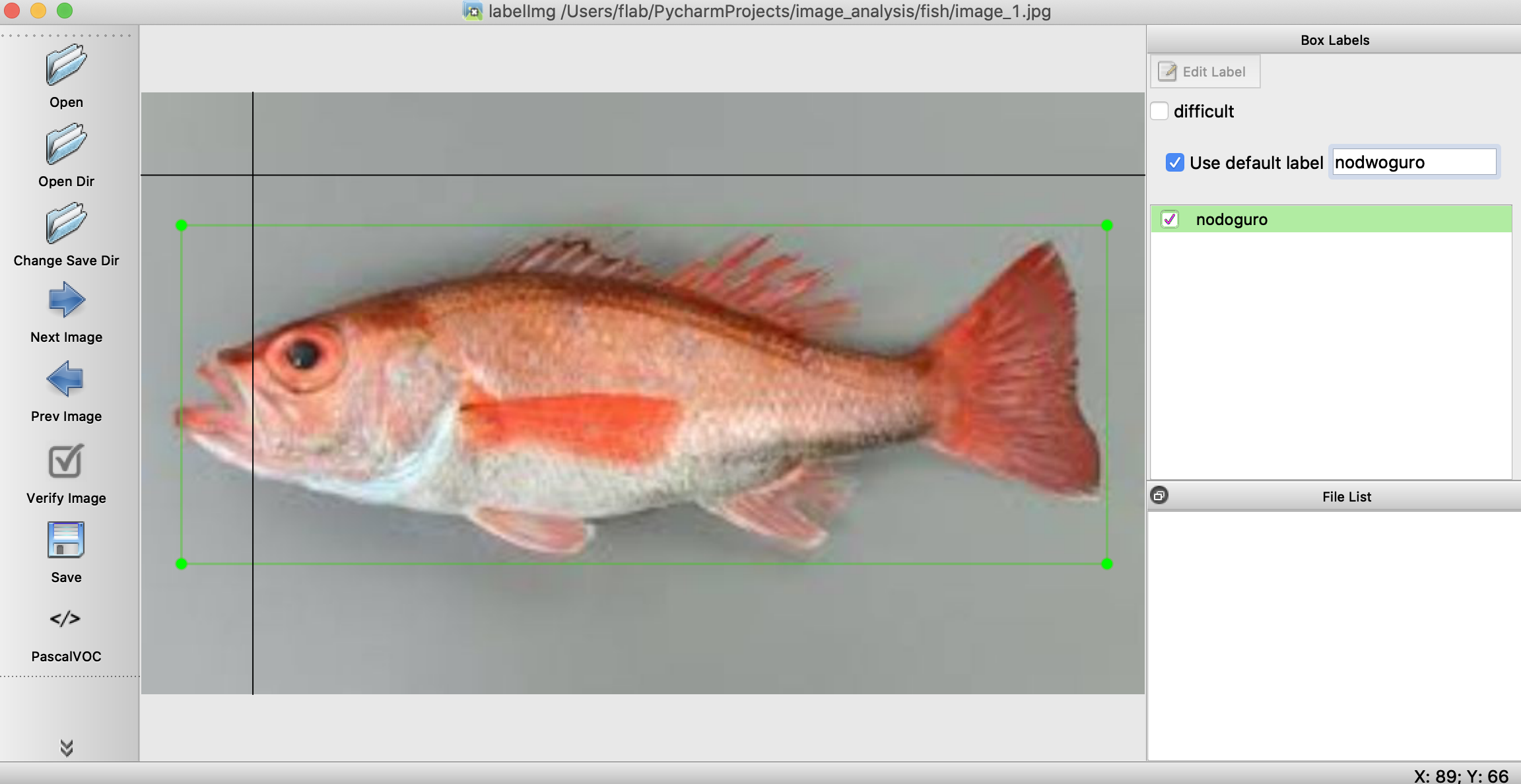
すると、こんな感じでラベルをつけることができます。
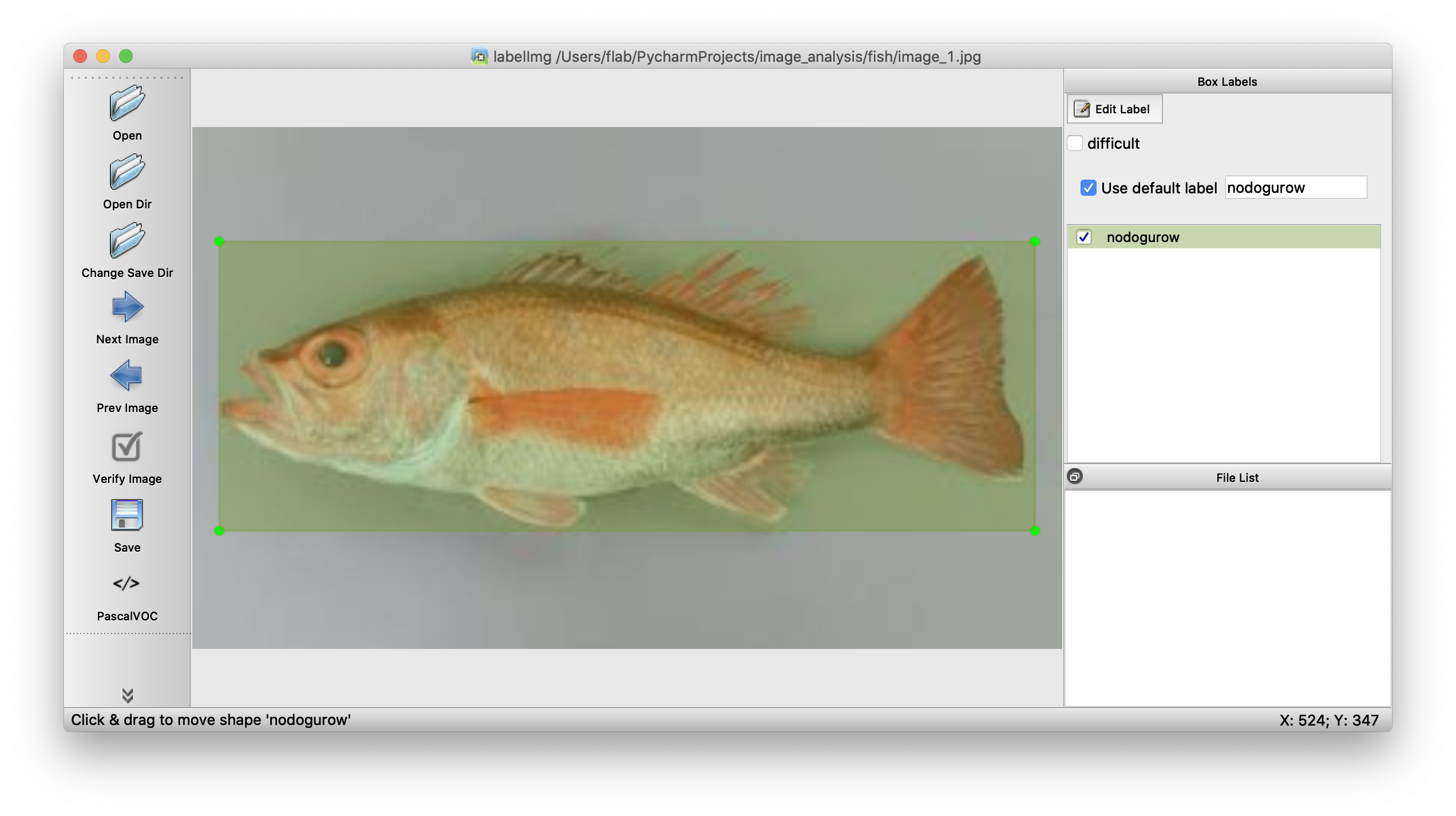
こんな感じで2つ付けることもできます。
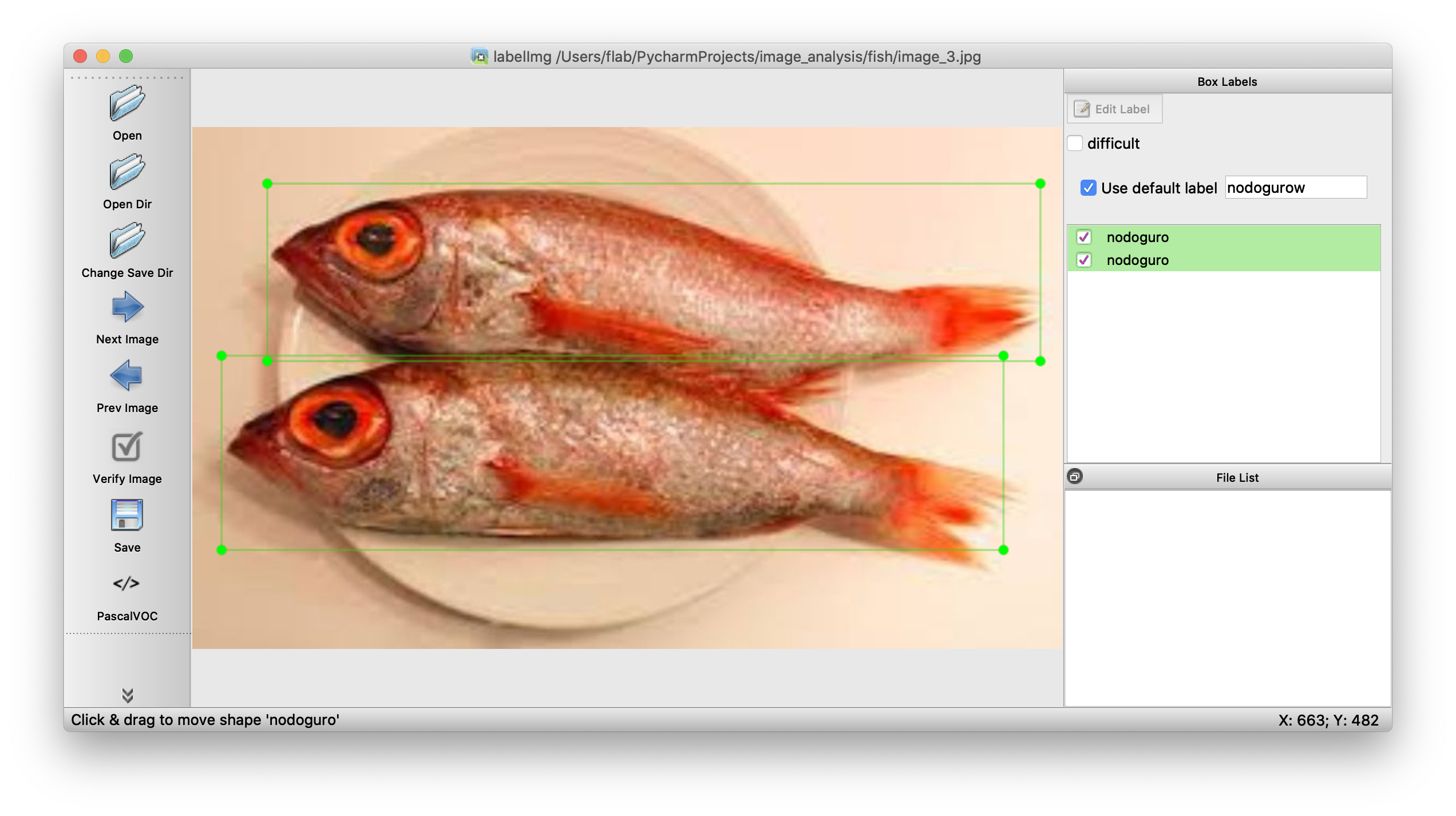
最後にsaveのボタンを押すとxmlファイルができます。このファイルにラベルとか枠線がどの座標にあるかの情報が入ってます。
ファルイ名はimage_1.jpg, image_2.jpgと言った風にナンバリングしておいてください。
あとはclasses.txtって名前のラベル名が箇条書きで書かれたファイルを作ります。
nodoguro
iwashi
cat
学習データ作りはこれで終了です!
気をつける点としては「画像サイズを揃えること」と「ラベルを2種類以上にすること」です。
ラベルの種類が1種類だと学習の際にうまくいきませんでした。
NODOGURO turning
学習データができたので実際に学習させてみましょう。学習済みモデルにはImagenetを使用しました。
今回は7枚の画像を追加学習します。
またディレクトリ構造は以下の感じにしています。
sample/
├ fish/
│ ├ res_images/
│ │ ├ images.npy
│ │ ├ bounding_box_data.npy
│ │ └ object_ids.npy
│ ├ classes.txt
│ ├ image_1.jpg
│ ├ image_1.xml
│ ├ ...
│ ├ image_7.xml
│ └ test.jpg
├ out/
├ learn.py
├ predict.py
└ xml2numpyarray.py
データ整形
今回学習させる前にnumpyarrayの形にしておいた方が都合よかったため、以下のコードを使ってその変換をしました。
import errorが起きる場合はpipで入れてください。
import matplotlib.pyplot as plt
import numpy as np
import glob
import os
import cv2
from PIL import Image
import xmltodict
# Global Variables
classes_file = 'fish/classes.txt'
data_dir = 'fish'
classes = list()
with open(classes_file) as fd:
for one_line in fd.readlines():
cl = one_line.split('\n')[0]
classes.append(cl)
print(classes)
def getBBoxData(anno_file, classes, data_dir):
with open(anno_file) as fd:
pars = xmltodict.parse(fd.read())
ann_data = pars['annotation']
print(ann_data['filename'])
# read image
img = Image.open(os.path.join(data_dir, ann_data['filename']))
img_arr = np.asarray(img).transpose(2, 0, 1).astype(np.float32)
bbox_list = list()
obj_names = list()
for obj in ann_data['object']:
bbox_list.append([obj['bndbox']['ymin'], obj['bndbox']['xmin'], obj['bndbox']['ymax'], obj['bndbox']['xmax']])
obj_names.append(obj['name'])
bboxs = np.array(bbox_list, dtype=np.float32)
obj_names = np.array(obj_names)
obj_ids = np.array(list(map(lambda x:classes.index(x), obj_names)), dtype=np.int32)
return {'img':img, 'img_arr':img_arr, 'bboxs':bboxs, 'obj_names':obj_names, 'obj_ids':obj_ids}
def getBBoxDataSet(data_dir, classes):
anno_files = glob.glob(os.path.join(data_dir, '*.xml'))
img_list = list()
bboxs = list()
obj_ids = list()
# imgs = np.zeros([4, 3, 189, 267])
# num = 0
for ann_file in anno_files:
ret = getBBoxData(anno_file=ann_file, classes=classes, data_dir=data_dir)
print(ret['img_arr'].shape)
img_list.append(ret['img_arr'])
# imgs[num] = ret['img_arr']
bboxs.append(ret['bboxs'])
obj_ids.append(ret['obj_ids'])
imgs = np.array(img_list)
return (imgs, bboxs, obj_ids)
imgs, bboxs, obj_ids = getBBoxDataSet(data_dir=data_dir, classes=classes)
np.save(os.path.join(data_dir, 'images.npy'), imgs)
np.save(os.path.join(data_dir, 'bounding_box_data.npy'), bboxs)
np.save(os.path.join(data_dir, 'object_ids.npy'), obj_ids)
学習
以下のコードで実行
import os
import numpy as np
import chainer
import random
from chainercv.chainer_experimental.datasets.sliceable import TupleDataset
from chainercv.links import FasterRCNNVGG16
from chainercv.links.model.faster_rcnn import FasterRCNNTrainChain
from chainer.datasets import TransformDataset
from chainercv import transforms
from chainer import training
from chainer.training import extensions
HOME = './'
data_dir = os.path.join(HOME, './fish/res_images')
file_img_set = os.path.join(data_dir, 'images.npy')
file_bbox_set = os.path.join(data_dir, 'bounding_box_data.npy')
file_object_ids = os.path.join(data_dir, 'object_ids.npy')
file_classes = os.path.join(data_dir, 'classes.txt')
# データセットの読み込み
imgs = np.load(file_img_set)
bboxs = np.load(file_bbox_set, allow_pickle=True)
objectIDs = np.load(file_object_ids, allow_pickle=True)
# ラベル情報の読み込み
classes = list()
with open(file_classes) as fd:
for one_line in fd.readlines():
cl = one_line.split('\n')[0]
classes.append(cl)
dataset = TupleDataset(('img', imgs), ('bbox', bboxs), ('label', objectIDs))
N = len(dataset)
N_train = (int)(N*0.9)
N_test = N - N_train
print('total:{}, train:{}, test:{}'.format(N, N_train, N_test))
# ネットワーク構築
faster_rcnn = FasterRCNNVGG16(n_fg_class=len(classes), pretrained_model='imagenet')
faster_rcnn.use_preset('evaluate')
model = FasterRCNNTrainChain(faster_rcnn)
# GPUの設定(今回は使用しない)
gpu_id = -1
# chainer.cuda.get_device_from_id(gpu_id).use()
# model.to_gpu()
# 何の手法で最適化するか設定
optimizer = chainer.optimizers.MomentumSGD(lr=0.001, momentum=0.9)
optimizer.setup(model)
optimizer.add_hook(chainer.optimizer_hooks.WeightDecay(rate=0.0005))
# データの用意
class Transform(object):
def __init__(self, faster_rcnn):
self.faster_rcnn = faster_rcnn
def __call__(self, in_data):
img, bbox, label = in_data
_, H, W = img.shape
img = self.faster_rcnn.prepare(img)
_, o_H, o_W = img.shape
scale = o_H / H
bbox = transforms.resize_bbox(bbox, (H, W), (o_H, o_W))
# horizontally flip
img, params = transforms.random_flip(
img, x_random=True, return_param=True)
bbox = transforms.flip_bbox(
bbox, (o_H, o_W), x_flip=params['x_flip'])
return img, bbox, label, scale
idxs = list(np.arange(N))
random.shuffle(idxs)
train_idxs = idxs[:N_train]
test_idxs = idxs[N_train:]
# 学習するためのいろいろな設定
train_data = TransformDataset(dataset[train_idxs], Transform(faster_rcnn))
train_iter = chainer.iterators.SerialIterator(train_data, batch_size=1)
test_iter = chainer.iterators.SerialIterator(dataset[test_idxs], batch_size=1, repeat=False, shuffle=False)
updater = chainer.training.updaters.StandardUpdater(train_iter, optimizer, device=gpu_id)
n_epoch = 20
out_dir = './out'
trainer = training.Trainer(updater, (n_epoch, 'epoch'), out=out_dir)
step_size = 100
trainer.extend(extensions.snapshot_object(model.faster_rcnn, 'snapshot_model.npz'), trigger=(n_epoch, 'epoch'))
trainer.extend(extensions.ExponentialShift('lr', 0.1), trigger=(step_size, 'iteration'))
log_interval = 1, 'epoch'
plot_interval = 1, 'epoch'
print_interval = 1, 'epoch'
trainer.extend(chainer.training.extensions.observe_lr(), trigger=log_interval)
trainer.extend(extensions.LogReport(trigger=log_interval))
trainer.extend(extensions.PrintReport(['iteration', 'epoch', 'elapsed_time', 'lr', 'main/loss', 'main/roi_loc_loss', 'main/roi_cls_loss', 'main/rpn_loc_loss', 'main/rpn_cls_loss', 'validation/main/map', ]), trigger=print_interval)
trainer.extend(extensions.PlotReport(['main/loss'], file_name='loss.png', trigger=plot_interval), trigger=plot_interval)
trainer.extend(extensions.dump_graph('main/loss'))
# 学習
trainer.run()
こちらが設定するパラメータとしては
・gpuのところ(今回はgpuは使用していません)
# chainer.cuda.get_device_from_id(gpu_id).use()
# model.to_gpu()
・最適化(optimizer)のところ
optimizer = chainer.optimizers.MomentumSGD(lr=0.001, momentum=0.9)
optimizer.setup(model)
optimizer.add_hook(chainer.optimizer_hooks.WeightDecay(rate=0.0005))
・学習回数のところ
n_epoch = 20
step_size = 100
になります。
他にもbatch_sizeやテストデータを何個にするか(N_train = (int)(N*0.9) N_test = N - N_train)など他にもいろいろありますが、とりあえずは上の3つぐらいです。
ちなみに学習済みのネットワークはout/snapshot_model.npzってファイルに保存されます。
予測
実際にノドグロを認識してみました。
Scoreが0.9以上のやつだけ認識するようにしました。
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from chainercv.visualizations import vis_bbox
from chainercv.links import FasterRCNNVGG16
# ラベル読み込み
classes = list()
with open('./fish/classes.txt') as fd:
for one_line in fd.readlines():
cl = one_line.split('\n')[0]
classes.append(cl)
# テストデータの読み込み
test_data = Image.open('./fish/test.jpg')
test_data = np.asarray(test_data).transpose(2, 0, 1).astype(np.float32)
# 学習したモデルを読み込み
pretrain_model = 'out/snapshot_model.npz'
# ネットワーク構築
model_frcnn = FasterRCNNVGG16(n_fg_class=len(classes), pretrained_model=pretrain_model)
# 予測
bboxes, labels, scores = model_frcnn.predict([test_data])
predict_result = [test_data, bboxes[0], labels[0], scores[0]]
# スコアが0.9以下のやつを認識しないようにスレッショルド設定
line = 0.9
# 描画
res = predict_result
fig = plt.figure(figsize=(6, 6))
ax = fig.subplots(1, 1)
vis_bbox(res[0], res[1][res[3]>line], res[2][res[3]>line], res[3][res[3]>line], label_names=classes, ax=ax)
plt.show()
結果がこちらになります。
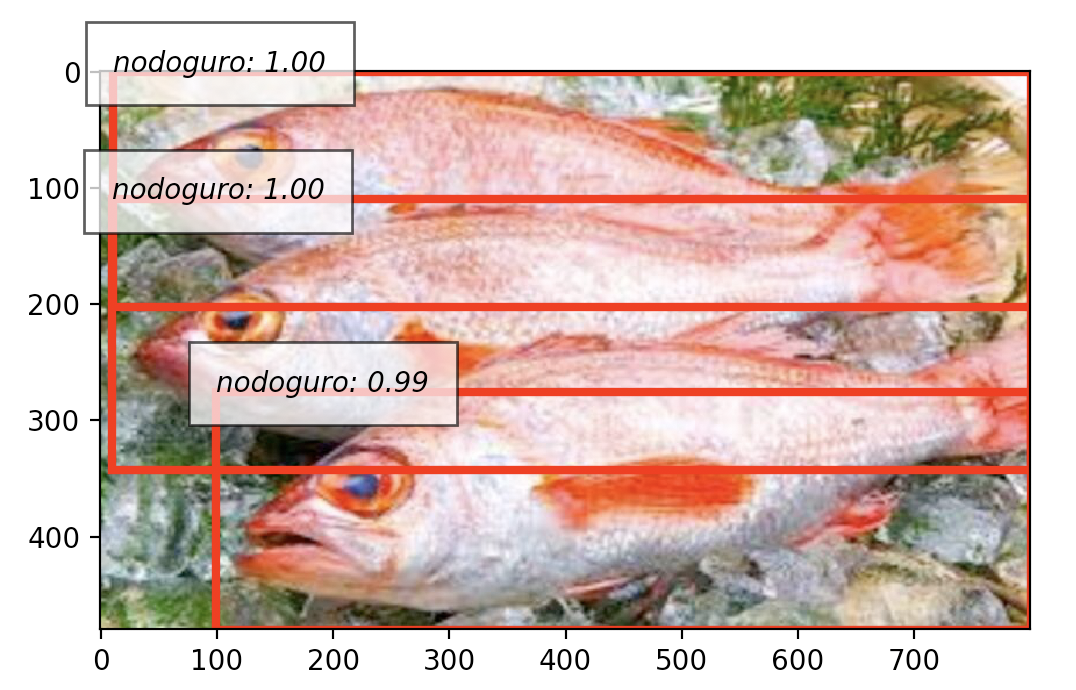
ちゃんと認識できました!
print(np.sum(labels[0] == 0))で認識した数を表示することもできます。
さいごに
今回はエイヤッでfine-turningをしてノドグロ検出をしてみました。
終わってみるとけっこう簡単でしたね。次はノドグロを好きな画像に変えればいいだけなので比較的楽に実装できますね。
ただ実際高精度な検出やカウントを実現する場合は、重なりの部分をどうするかや回転をどうするかなど、そもそものネットワーク構造や問題設定から練り直したりしなくちゃいけないので大変です。
研究レベルや商品レベルにもっていくには難しいですが、今回の実装を通して「とりあえずDeepを使って遊んでみる」ってところまでは比較的簡単にできるってことは分かってもらえたんじゃないかなと思います。
参考サイト
ほとんど、このサイトを参考にしてやりました。
http://chocolate-ball.hatenablog.com/entry/2018/05/23/012449