目次
- はじめに
- 実行環境
- 実施手順一覧
- データについて
- 実施内容
- 考察・まとめ
- 感想
はじめに
ビジネスに関わる人はすべて自分たちのサービスについて顧客がどのように考えているかを知り、ビジネスの改善につなげたいと考えています。自社の強みを理解し、競合と比較してどのようなポジショニングをとっていくかを判断するのはとても重要です。
そのためにはユーザーの声を分析することが重要であり、そのためのデータとしてインターネット上で蓄積されているの口コミデータを利用できないかと考えました。
本記事の目標としては、私自身がホテルで働いていたこともあり、東京都内のとあるホテルの口コミデータをテキストマイニングしてその特徴や他ホテルとの差異を分析し、自社の強みや今後のサービス改善の方向性を考察することにあります。
実行環境
- Python3
- Windows 11
- Chrome
- Google Colaboratory
私のレベル
プログラミング初心者
pythonを触りはじめて約半年
実施手順一覧
- スクレイピングを実施し、元データを作成する
- 各ホテルのレビュー数とレビュー評価の分布の可視化
- データの前処理
- 各ホテルのポジティブな単語群、ネガティブな単語群を作成
- ホテル毎の差異を分析
5. 実施内容
1.スクレイピングを実施し、元データを作成する
1. 利用するデータについて
楽天トラベルの口コミデータのうち、東京都内品川エリアの高級宿に分類される任意の 3 軒のホテルについて、2022年4月~2023年4月までの1年間のの口コミを抽出した(図 1)。このうち、口コミのテキストデータを対象にして、解析を実施。
3軒のホテル
2. スクレイピングの方法
スクレイピングの実施方法についてはBeautiful Soupを用いて実施しようと思いましたが、今回は時間短縮のためやむなくローコードツールを利用しました。
今回使用したスクレイピングツールは下記です。
■Octoparse
無課金でも1回のタスク実行あたり最大1万レコードの抽出が可能です。
今回はこれによって収集した約520件のコメントデータを使ってテキストマイニングを実施していきます。
■スクレイピングの実施結果の一部抜粋

2. 各ホテルのレビュー数とレビュー評価の分布の可視化
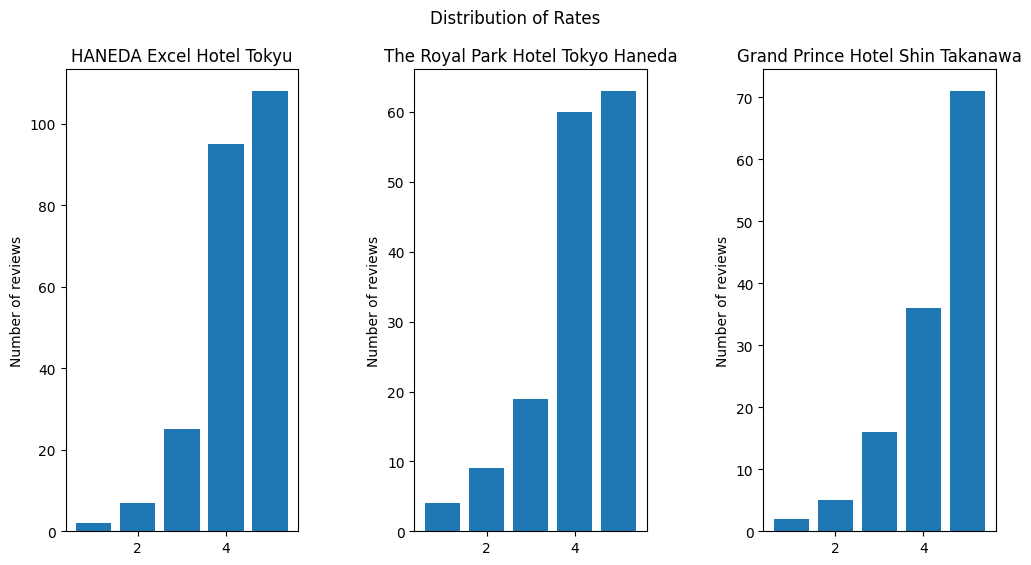
まずは各ホテル毎に抽出したレビュー数とそのレビュー評価(☆1~☆5)の分布をグラフ化しました。
1. 使用ライブラリ一覧
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
2. 各ホテルのレビューデータをデータフレーム型に変換
スクレイピングしたデータはエクセルファイルだったので、データフレーム型に変換しました。
#羽田エクセルホテル東急の口コミデータ
df1 = pd.read_excel("羽田エクセルホテル東急のエクセルファイルのパス")
#ザ・ロイヤルパークホテル東京羽田の口コミデータ
df2 = pd.read_excel("ザ・ロイヤルパークホテル東京羽田のエクセルファイルのパス")
#グランドプリンスホテル新高輪の口コミデータ
df3 = pd.read_excel("グランドプリンスホテル新高輪のエクセルファイルのパス")
df1.head()
df1.head()で先頭から5行抜き出した結果は以下の感じ
3. 各ホテルのレビュー数とレビュー評価の分布のグラフ化
各ホテル毎に取得したレビュー数とレビュー評価の分布を棒グラフで可視化
values_1, counts_1 = np.unique(df1['rate'], return_counts=True)
values_2, counts_2 = np.unique(df2['rate'], return_counts=True)
values_3, counts_3 = np.unique(df3['rate'], return_counts=True)
x1 = np.array(values_1)
x2 = np.array(values_2)
x3 = np.array(values_3)
y1 = np.array(counts_1)
y2 = np.array(counts_2)
y3 = np.array(counts_3)
fig = plt.figure(figsize = (12,6))
ax1 = fig.add_subplot(1, 3, 1)
ax2 = fig.add_subplot(1, 3, 2)
ax3 = fig.add_subplot(1, 3, 3)
plt.subplots_adjust(wspace=0.5, hspace=0.5)
ax1.bar(x1, y1,label=['1','2','3','4','5'])
ax2.bar(x2, y2,label=['1','2','3','4','5'])
ax3.bar(x3, y3,label=['1','2','3','4','5'])
plt.suptitle('Distribution of Rates')
ax1.set_title('HANEDA Excel Hotel Tokyu')
ax2.set_title('The Royal Park Hotel Tokyo Haneda')
ax3.set_title('Grand Prince Hotel Shin Takanawa')
ax1.set_ylabel('Number of reviews')
ax2.set_ylabel('Number of reviews')
ax3.set_ylabel('Number of reviews')
実行結果は以下の通り。
今回はレビュー評価の総合平均☆4以上のホテルを取り上げたので、レビューも☆4☆5に偏っています。
ネガティブな口コミ分析をするにはデータが足りないかもという懸念がありましたがそのまま分析を継続。。
3. データの前処理
1. 使用ライブラリ一覧
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
!pip install mecab-python3
!pip install unidic
!python -m unidic download
import MeCab
import unidic
import re
!pip install japanize-matplotlib
import japanize_matplotlib
2. 元データの加工
レビューの評価を0(評価3以下のネガティブ)と1(評価4以上のポジティブ)の2つのクラスに分類し、さらに処理するために「ターゲット」という新しい列をデータフレームに追加し、必要な列(「コメント」「Target」)のみに整形しました。
# Create new column "Target" that stored 0's or 1's. 0 being Negative, 1 being Positive
df1["Target"] = np.where(df1["rate"] >= 4, 1, 0)
df2["Target"] = np.where(df2["rate"] >= 4, 1, 0)
df3["Target"] = np.where(df3["rate"] >= 4, 1, 0)
# Picking the only text and target column
df1_final = df1[['コメント','Target']]
df2_final = df2[['コメント','Target']]
df3_final = df3[['コメント','Target']]
df1_final.head(5)
df1_final.head()で先頭から5行抜き出した結果は以下の感じ。
先頭5行はすべてTarget=1なのでポジティブに分類された口コミと分かります。
4. 各ホテルのポジティブな単語群、ネガティブな単語群を作成
1. 形態素解析の実施
上記で分類したネガティブ/ポジティブな口コミデータを、それぞれMecabを用いて形態素解析を実施していきました。
また、不要なデータとして数字を削除しました。
#コメントから数字を削除
df1_final['コメント'] =df1_final['コメント'].apply(lambda x: re.sub(r'\d+', '', x))
df2_final['コメント'] =df1_final['コメント'].apply(lambda x: re.sub(r'\d+', '', x))
df3_final['コメント'] =df1_final['コメント'].apply(lambda x: re.sub(r'\d+', '', x))
# 羽田エクセルホテル東急のpositiveな単語群の作成
mecab = MeCab.Tagger('')
HN_pos_diclist = []
for index, HN_data in df1_final.iterrows():
if HN_data['Target'] == 1:
HN_pos_line = mecab.parse(HN_data['コメント'])
HN_pos_l = re.split('\t|,',HN_pos_line)
HN_pos_d = {'BaseForm':HN_pos_l[9]}
# print(HN_pos_d)
HN_pos_diclist.append(HN_pos_d['BaseForm'])
print(HN_pos_diclist)
# 羽田エクセルホテル東急のnegativeな単語群の作成
mecab = MeCab.Tagger('')
HN_neg_diclist = []
for index, HN_data in df1_final.iterrows():
# print(mecab.parse(data['コメント']))
if HN_data['Target'] == 0:
HN_neg_line = mecab.parse(HN_data['コメント'])
HN_neg_l = re.split('\t|,',HN_neg_line)
HN_neg_d = {'BaseForm':HN_neg_l[9]}
# print(HN_neg_d)
HN_neg_diclist.append(HN_neg_d['BaseForm'])
print(HN_neg_diclist)
# ザ・ロイヤルパークホテル東京羽田のpositiveな単語群の作成
mecab = MeCab.Tagger('')
RP_pos_diclist = []
for index, RP_data in df2_final.iterrows():
if RP_data['Target'] == 1:
RP_pos_line = mecab.parse(RP_data['コメント'])
RP_pos_l = re.split('\t|,',RP_pos_line)
RP_pos_d = {'BaseForm':RP_pos_l[9]}
RP_pos_diclist.append(RP_pos_d['BaseForm'])
print(RP_pos_diclist)
# ザ・ロイヤルパークホテル東京羽田のnegativeな単語群の作成
mecab = MeCab.Tagger('')
RP_neg_diclist = []
for index, RP_data in df2_final.iterrows():
if RP_data['Target'] == 0:
RP_neg_line = mecab.parse(RP_data['コメント'])
RP_neg_l = re.split('\t|,',RP_neg_line)
RP_neg_d = {'BaseForm':RP_neg_l[9]}
RP_neg_diclist.append(RP_neg_d['BaseForm'])
print(RP_neg_diclist)
#グランドプリンスホテル新高輪のpositiveな単語群の作成
mecab = MeCab.Tagger('')
GR_pos_diclist = []
for index, GR_data in df3_final.iterrows():
if GR_data['Target'] == 1:
GR_pos_line = mecab.parse(GR_data['コメント'])
GR_pos_l = re.split('\t|,',GR_pos_line)
GR_pos_d = {'BaseForm':GR_pos_l[9]}
GR_pos_diclist.append(GR_pos_d['BaseForm'])
print(GR_pos_diclist)
#グランドプリンスホテル新高輪のnegativeな単語群の作成
mecab = MeCab.Tagger('')
GR_neg_diclist = []
for index, GR_data in df3_final.iterrows():
if GR_data['Target'] == 0:
GR_neg_line = mecab.parse(GR_data['コメント'])
GR_neg_l = re.split('\t|,',GR_neg_line)
GR_neg_d = {'BaseForm':GR_neg_l[9]}
GR_neg_diclist.append(GR_neg_d['BaseForm'])
print(GR_neg_diclist)
2. 差集合をとる
上記でレビュー評価に基づく各ホテルのポジティブな単語群とネガティブな単語群をつくっていますが、ポジティブ/ネガティブどちらにも属する単語が含まれており、まだ純粋なポジティブ単語群/ネガティブ単語群にはなっていません。
今回は評価の高いレビューにはどんな単語が頻出しているか(=ポジティブ単語群)評価の低いレビューにはどんな単語が頻出しているかを分析したいため、純粋な単語群を作るのが望ましいです。
そのため、set関数にて「3. 形態素解析の実施」で作成した各ホテルの単語群の差集合をとり、純粋なポジティブ単語群/ネガティブ単語群の作成に挑戦しました。
例:①差集合をとる前→ポジティブ単語群A=飛行機,おいしい ネガティブ単語群B=飛行機,まずい ②B-Aで差集合をとった後→ポジティブ単語群=おいしいのみ残る
#データの前処理で取り出したlist型の単語群をset型にする
#羽田エクセルホテル東急の差集合をとる
HN_pos_set = set(HN_pos_diclist)
HN_neg_set = set(HN_neg_diclist)
HN_pos_dif = HN_pos_set - HN_neg_set #羽田エクセルホテル東急のpositiveな差集合
HN_neg_dif = HN_neg_set - HN_pos_set #羽田エクセルホテル東急のnegativeな差集合
#ザ・ロイヤルパークホテル東京羽田の差集合をとる
RP_pos_set = set(RP_pos_diclist)
RP_neg_set = set(RP_neg_diclist)
RP_pos_dif = RP_pos_set - RP_neg_set #ザ・ロイヤルパークホテル東京羽田のpositiveな差集合
RP_neg_dif = RP_neg_set - RP_pos_set #ザ・ロイヤルパークホテル東京羽田のnegativeな差集合
#グランドプリンスホテル新高輪の差集合をとる
GR_pos_set = set(GR_pos_diclist)
GR_neg_set = set(GR_neg_diclist)
GR_pos_dif = GR_pos_set - GR_neg_set #グランドプリンスホテル新高輪のpositiveな差集合
GR_neg_dif = GR_neg_set - GR_pos_set #グランドプリンスホテル新高輪のnegativeな差集合
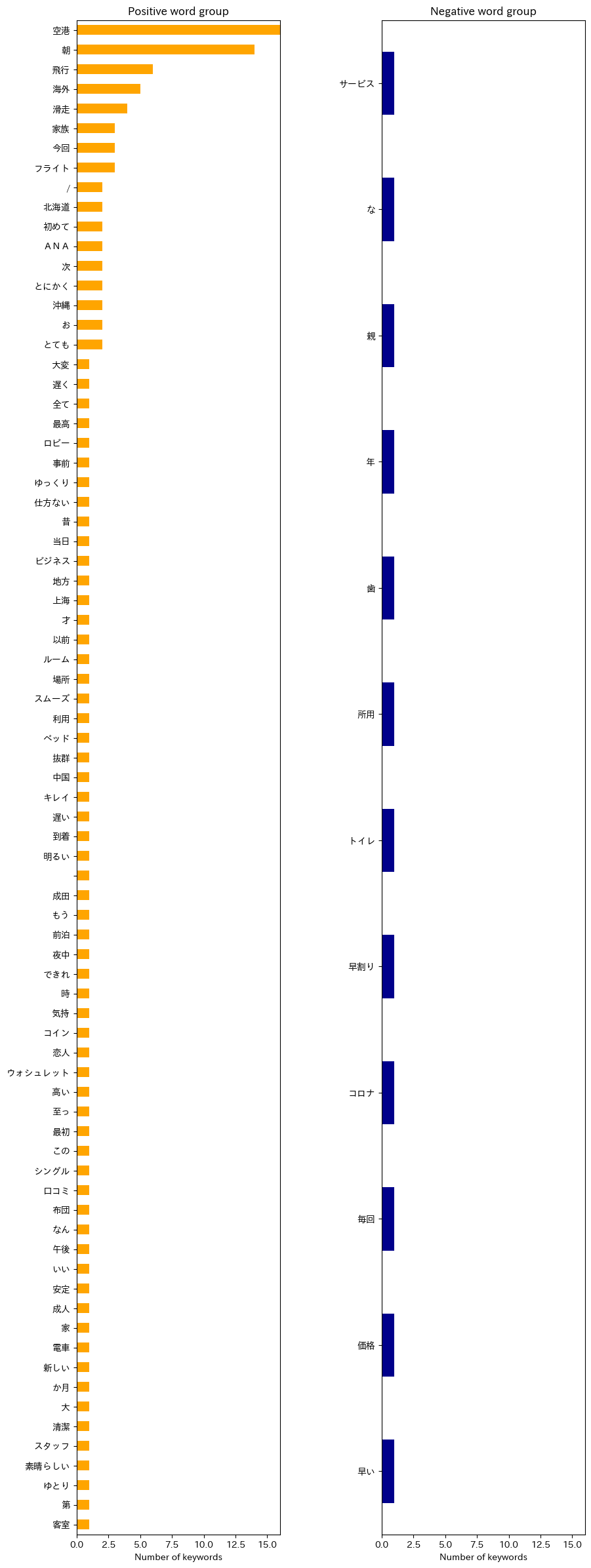
3. 各ホテルのポジティブな単語群、ネガティブな単語群を頻出度順に並べる
羽田エクセルホテル東急について
#羽田エクセルホテル東急のポジティブな単語群、ネガティブな単語群を可視化
fig = plt.figure(figsize=(10,30))
plt.subplots_adjust(wspace=0.5, hspace=0.5)
HN_pos_series = pd.Series(HN_pos_diclist).value_counts()
HN_pos_series = HN_pos_series[HN_pos_dif].sort_values(ascending=False)
ax1 = fig.add_subplot(1, 2, 1)
ax1 = HN_pos_series.plot.barh(color='orange')
ax1.set_xlim(0, 16)
plt.gca().invert_yaxis()
ax2 = fig.add_subplot(1, 2, 2)
HN_neg_series = pd.Series(HN_neg_diclist).value_counts()
HN_neg_series = HN_neg_series[HN_neg_dif].sort_values(ascending=False)
ax2 = HN_neg_series.plot.barh(color='darkblue')
ax2.set_xlim(0, 16)
plt.gca().invert_yaxis()
ax1.set_title('Positive word group')
ax2.set_title('Negative word group')
ax1.set_xlabel('Number of keywords')
ax2.set_xlabel('Number of keywords')
実行結果は以下の通り。
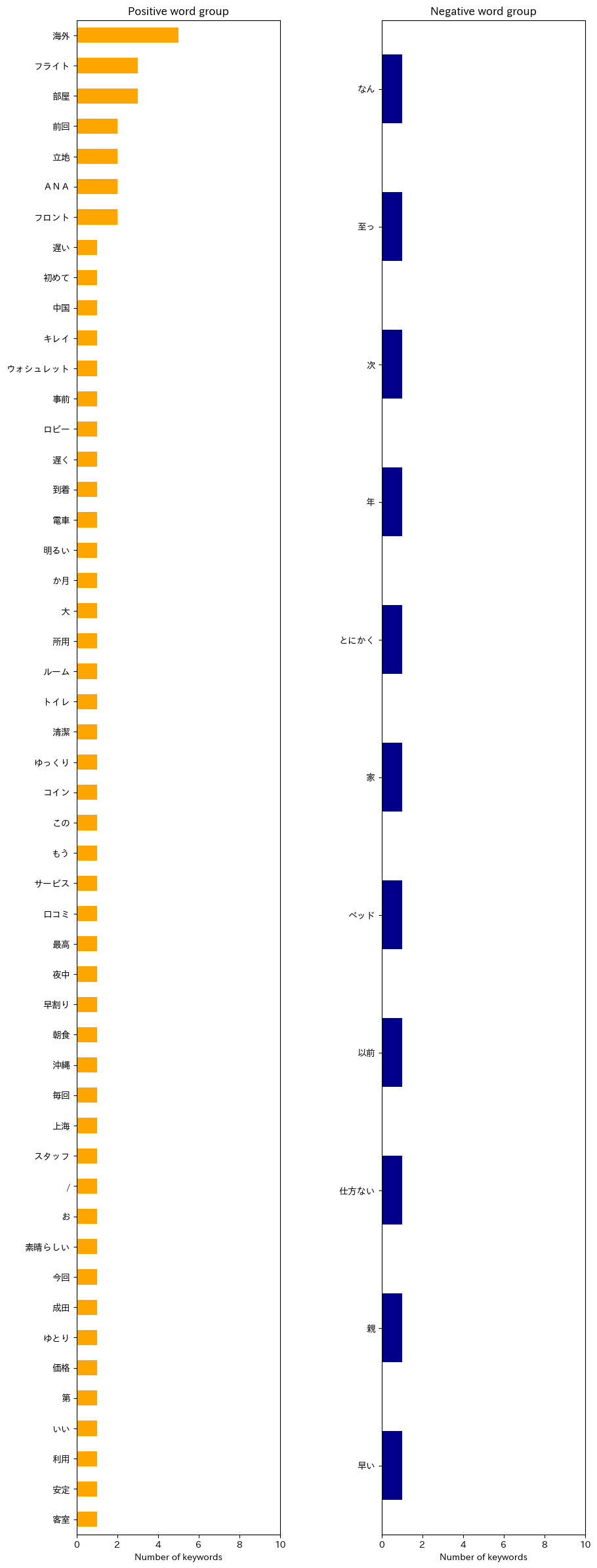
ザ・ロイヤルパークホテル東京羽田に関するコードは折り畳み
#ザ・ロイヤルパークホテル東京羽田のポジティブな単語群、ネガティブな単語群を比較
fig = plt.figure(figsize=(10,30))
plt.subplots_adjust(wspace=0.5, hspace=0.5)
RP_pos_series = pd.Series(RP_pos_diclist).value_counts()
RP_pos_series = RP_pos_series[RP_pos_dif].sort_values(ascending=False)
ax1 = fig.add_subplot(1, 2, 1)
ax1 = RP_pos_series.plot.barh(color='orange')
ax1.set_xlim(0, 10)
plt.gca().invert_yaxis()
ax2 = fig.add_subplot(1, 2, 2)
RP_neg_series = pd.Series(RP_neg_diclist).value_counts()
RP_neg_series = RP_neg_series[RP_neg_dif].sort_values(ascending=False)
ax2 = RP_neg_series.plot.barh(color='darkblue')
ax2.set_xlim(0, 10)
plt.gca().invert_yaxis()
ax1.set_title('Positive word group')
ax2.set_title('Negative word group')
ax1.set_xlabel('Number of keywords')
ax2.set_xlabel('Number of keywords')
実行結果は以下の通り
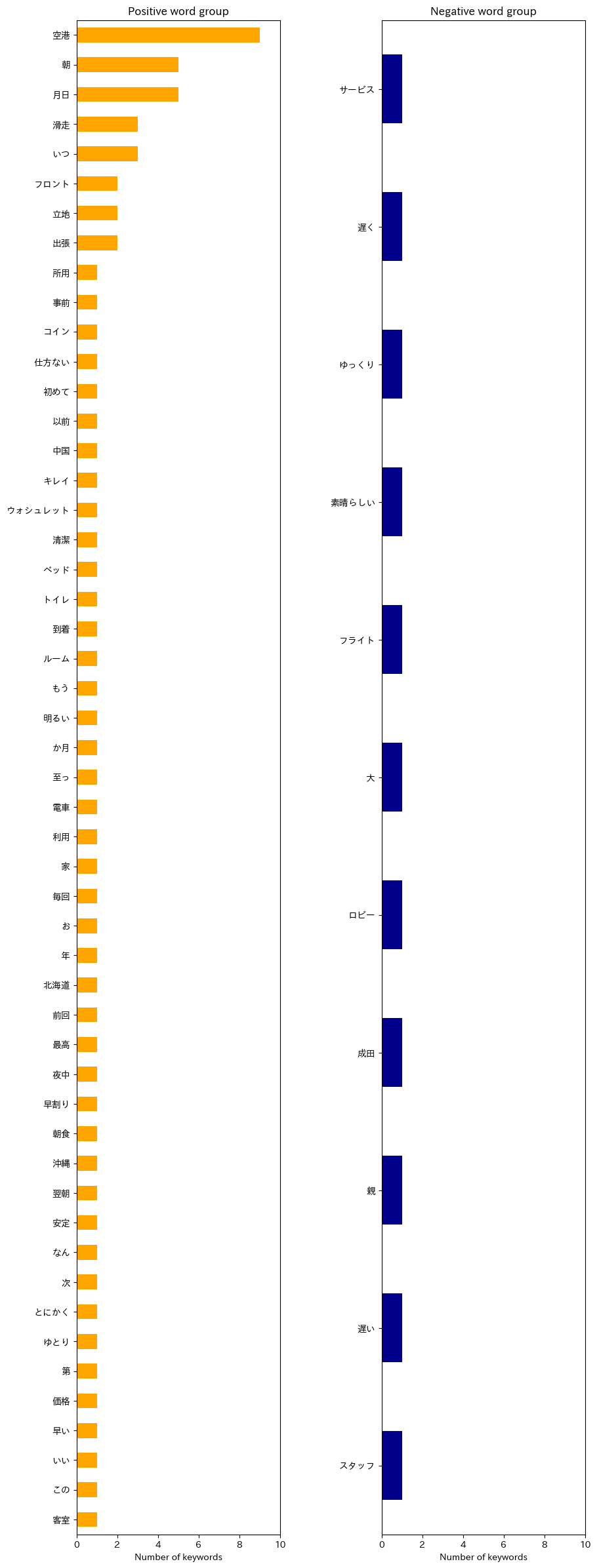
グランドプリンスホテル新高輪に関するコードは折り畳み
#グランドプリンスホテル新高輪のポジティブな単語群、ネガティブな単語群を比較
fig = plt.figure(figsize=(10,30))
plt.subplots_adjust(wspace=0.5, hspace=0.5)
GR_pos_series = pd.Series(GR_pos_diclist).value_counts()
GR_pos_series = GR_pos_series[GR_pos_dif].sort_values(ascending=False)
ax1 = fig.add_subplot(1, 2, 1)
ax1 = GR_pos_series.plot.barh(color='orange')
ax1.set_xlim(0, 10)
plt.gca().invert_yaxis()
ax2 = fig.add_subplot(1, 2, 2)
GR_neg_series = pd.Series(GR_neg_diclist).value_counts()
GR_neg_series = GR_neg_series[GR_neg_dif].sort_values(ascending=False)
ax2 = GR_neg_series.plot.barh(color='darkblue')
ax2.set_xlim(0, 10)
plt.gca().invert_yaxis()
ax1.set_title('Positive word group')
ax2.set_title('Negative word group')
ax1.set_xlabel('Number of keywords')
ax2.set_xlabel('Number of keywords')
実行結果は以下の通り
5. ホテル毎の差異を分析
各ホテルの頻出単語に差異があるか確認するため、羽田エクセルホテル東急とグランドプリンスホテル新高輪のポジティブな単語群の差集合をとって、それぞれに固有の単語を取り出して比較してみた。
HN_GR_pos_dif = HN_pos_dif - GR_pos_dif
GR_HN_pos_dif = GR_pos_dif - HN_pos_dif
df_HNGR = pd.DataFrame((zip(list(HN_GR_pos_dif), list(GR_HN_pos_dif))),columns = ['HANEDA','Grand Prince'])
print(df_HNGR)
実行結果は以下の通り。

ううむ、正直想像していたよりも単語だけでは特徴が分かりづらかった。。
6. 考察・まとめ
分析を行う前に結果として期待していたのは、各ホテルのポジティブな単語群を見ることで自社がユーザーから評価されている点がわかり、ネガティブな単語群を見ることでサービスとして改善すべき点の示唆が得られることだった。
しかし、実際に分析してみて分かったことは、単語群の抽出のみでは上記のような示唆を得るのは難しいということであった。
例えば、羽田エクセルホテル東急のポジティブな単語群を見てみると「空港」「朝」「飛行」「海外」などの単語が頻出しており、空港に近いことなどが評価されていることは推察できるが、「朝」という単語からでは「朝早くに空港に行けるから便利」なのか、「朝の何らかのサービスが良い」のか、把握することができない。
ネガティブな単語群については、やはりデータ量が少なくて特徴を抽出することには成功しなかった。
また、「5. ホテル毎の差異を分析」についても、単語群のみからでは得られる情報が少なく、各ホテルの特徴を掴むのは難しかった。
改善点としては、Mecabの辞書を変更したり、名詞や動詞のみを抽出するなどで、今よりは特徴が分かりやすくなる可能性はあるが、本来果たしたかった目的を達成するためには、各単語に紐づく関連語を抽出して分析するなどさらなる工夫が必要であると感じた。