ガウス過程と機械学習3章のノート
- ガウス過程と機械学習を読んだ自分用のノートです
- 後で見返す用なので、細かすぎることは書かずあらすじ程度の内容
- 詳しいことは本を買って読んでみてください
- 誤字脱字、間違いなどが有りましたらコメントよろしくおねがいします。
今回のノートにおける主題:ガウス過程を用いることでランダムになめらかな曲線が得られることが理解・実装できること
3章ではガウス過程における詳細について議論される.
今回は3.2節まで.
3.1線形回帰モデルと次元の呪い
入力空間の次元が増えるたびにパラメータの個数が冪的に増える現象を次元の呪いと呼んでいる。
パラメータを用いたモデルの限界のを示す例の1つである。
次元の呪いを突破する方法として、 パラメータを全く使わないノンパラメトリックな方法がある。その例の一つがカーネル法である。テキストの3.2節ではカーネル法を見るために、まずはパラメトリックなモデルの簡単な例である線形モデルをノンパラメトリックなカーネルで記述することにする。
3.2 ガウス過程
本文の順番通りではないが、先にガウス過程の定義を述べておく。
ガウス過程の正確な定義
$N$個の入力 $(x_{1},\cdots,x_{N})$ に対しての出力 $\mathbf{f} = (f(x_{1}),\cdots,f(x_{N}))$ のセットを考える。
- 平均:$\mu = (\mu(x_1),\cdots ,\mu(x_{N}))$
- 共分散:$K_{nn'} = k(x_{n},x_{n'})$
であるような多変数ガウス分布$\mathcal{N}(\mu ,K)$に従うとする。
このとき関数$f(x)$を出力する確率分布をガウス過程とよび、$f\sim GN(\mu ,K)$で表す。
ガウス過程の出力結果として得られるものは、1つのランダムな滑らかな関数$f(x)$である。
つまり入力用の点$x_{1},\cdots,x_{n}$に対して, 出力$f(x_{1}),\cdots, f(x_{n})$がランダムに得られるが、これらをプロットすると曲線(曲面)が得られるのである。
まず線形モデルがガウス過程の1つの例で在ることを確認する。
線形モデルとは
\begin{align}
y &= f(x) = w_{i} \phi(x)_{i}
\end{align}
のようにパラメータ$w_{i}$と特徴量空間への写像$\phi(x)$の関係が線形になっているモデルのことである。
データセット, $\mathcal{D} = (x_{1},y_{1}),\cdots, (x_{N},y_{N}) $ に対して
\begin{align}
\hat{y}_{i} = w_{j} \phi_{j}(x_{i})
\end{align}
という予測モデルを建てる。 ここで $y_{i}$に対する予測を $\hat{y}_{i}$ とした。テキストでは観測データに近づけるための当てはめ値と呼んでいる。
線形モデルがガウス過程の一つであることを確認するために、テキスト の 3.2 章において次のような設定で議論が進む:
- $\mathbf{\Phi}$ という太字で行列, $\Phi_{ij} = \phi_{j}(x_{i})$を定義。
- $\hat{y} = y $つまり観測における誤差が全く無いと仮定
- $w$ はガウス分布 $\mathbf{w} \sim \mathcal{N}(0,\lambda^{2} I)$ に従う確率変数とする.
まず、ガウス分布に従う確率変数の線形結合もまたガウス分布に従っている。そのため、予測値 $\hat{y}$ はガウス分布に従う。 $\hat{y}$ の従うガウス分の平均と分散は簡単に計算でき,
- 平均: $E[\hat{y}] = 0$
- 分散: $ V[\hat{y}] = \Sigma_{ij} = E[y_{i}y_{j}] = \lambda^{2} \Phi_{ik}\Phi_{kj}^{T}$
で表される。 $\hat{y} = y $であるので、$y$ は
\begin{align}
y \sim \mathcal{N}(0,\Sigma)
\end{align}
というガウス分布で表される。ポイントは二点
- 与えられたデータ点$(x_{1},\cdots,x_{N})$に対して出力$(y_{1},\cdots,y_{N})$が$ \Sigma $という共分散行列に従うガウス分布である。つまり線形モデルをガウス過程の1種であるとみなせる。
- 線形モデルで用いたパラメータ$w$は最終的なモデルには現れていないためノンパラメトリックなモデルであると言える。
ガウス過程の「過程」という言葉は確率過程に由来しており、本来はランダムウォークなどの時間推移が確率的に与えられる状態から来ている。確率過程の一般的な性質がガウス過程においても成立しているためこう呼ばれているらしい。
また入力数$N$には制限がないのでこの意味で無限次元とよんでいる。しかし実際に計算できるのは有限のデータセットによる回帰分析だけであることに注意。
ガウス過程の意味(3.2.1)
テキストの目次はガウス過程の意味となっているが実際は共分散行列の意味である。
結論から言うと,共分散は異なる2つの確率変数の相関具合を表している.
線形モデルの場合、共分散行列は
\begin{align}
K_{nn'} = \lambda^{2} \phi_{j}(x_{n})\phi_{j}(x_{n'})
\end{align}
で表される. もちろん$j$に関する和はアインシュタインの縮約に基づいて省略している。
ここで共分散行列の成分の絶対値が大きい、つまり$\phi_{j}(x_{n})$ と $\phi_{j}(x_{n'})$の内積が大きいほど、その出力結果である, $y_{n}$と$y_{n'}$の値は確率的に似た値を取りやすくなる。
ここで注意してほしいのは、写像$\phi(x)$で送られた先、つまり、特徴量空間の世界で似た値を取る場合のことであり、 $x_{n}$と$x_{n'}$ が似た値を取る場合ではないことである。
そのためテキストの性質3.2のガウス過程の直感的な性質にかかれている、「入力$x$が似ていれば出力$y$も似ている」というのは若干のミスリードである。
カーネルトリック(3.2.2)
ガウス過程において重要なのはその共分散行列$K_{nn'}$だけである。(平均はいくらでも平行移動で0にすることができるのであまり重要ではない。)
共分散行列は特徴量空間上のベクトルの内積で与えられるが、その関数形さえわかっていれば別に$\phi(x)$を計算する必要はない. これをカーネルトリックという。
予め手計算で内積の関数系を$x,x'$で表して於けば良いよねっていう話.
ガウス過程からのサンプル(3.2.4)
実際にガウス過程によってなめらかな関数$f(x)$がランダムに一つ得られるということを確認してみる。
Pythonでガウス過程によって生成される分布が実際に曲線を描いていることを確認してみる。
まず必要なライブラリの呼び出し
import numpy as np
# 多変量正規分布の
from scipy.stats import multivariate_normal
import matplotlib.pyplot as plt
つぎにガウス過程の分布を生成するためにカーネル関数を定義する。ここではテキストに従ってガウスカーネルを用いる:
\begin{align}
k(x,x') = \theta_{1} \exp\left(-\frac{|x-x'|^2}{\theta_{2}}\right)
\end{align}
また, あまりパラメータを複雑にしたくないので、$\theta_{1,2} = 1$ に設定する。
ガウス分布の平均は$\mu = 0$とする。
Python 上では次のようにして表現される。
# xはN次元の配列であるとか?
K = np.exp([[- np.abs(x1-x2) **2 for x1 in x ]for x2 in x])
これで $N\times N $ の行列が生成される。
また入力ベクトル$x$から生成されたカーネル $K$にしたがって多変量ガウス分布に従う乱数を生成する関数を定義する:
def gauss(x):
mu = [0] * len(x)
K = np.exp([[- np.abs(x1-x2) **2 for x1 in x ]for x2 in x])
# size は出力する配列の Shape
y = np.random.multivariate_normal(mu, K, )
return y
実際にプロットしてみる. まず、$x$の範囲が$[1,4]$の間で、間隔が1づつの場合で実験してみる。
x = np.linspace(1,4,4)
y = gauss(x)
plt.scatter(x,y)
# 出力は乱数でありかつ seed を固定していないので同じ画像は出力されるとは限らない
plt.grid()
plt.show()
この状況だとまだなめらかな曲線が得られているようには見えない。
更に点の間隔を狭めていく:
x = np.linspace(1,4,20)
y = gauss(x)
plt.scatter(x,y)
plt.grid()
plt.show()
このような画像が得られる。若干曲線が得られているように見える。
さらに間隔を狭めると
x = np.linspace(1,4,100)
y = gauss(x)
plt.scatter(x,y)
plt.grid()
plt.show()
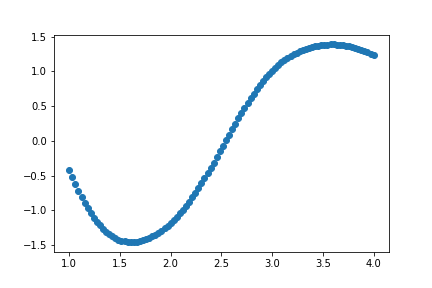
これはもうほとんど曲線である。
このように、$x$軸の表示領域の区間の間隔を狭めていくことで出力される乱数の集まりは曲線を描く。
なぜこのような曲線を描くことができるのかというのが共分散行列に隠されている。実際に共分散行列のヒートマップを作成すると
x = np.linspace(1,4,100)
K = np.exp([[- np.abs(x1-x2) **2 for x1 in x ]for x2 in x])
data = K
fig, ax = plt.subplots()
heatmap = ax.pcolor(data, cmap=plt.cm.Blues)
ax.invert_yaxis()
ax.xaxis.tick_top()
plt.savefig("test.png")
plt.show()

このような図が得られる。これは何度出力しても同じである。
色が濃いほど相関が高いことを表す。相関が高いとは確率変数の言葉でいうと、$x,x'$がランダムに出現したとしても, $x,x'$の値はなにか互いに示し合わせたかのように関連しあっているということである。
例えば、今の場合だと$y_{i} = f(x_{i})$ としたときに$x_{i}$と$x_{i+1}$は互いに最も相関が強いため、似たような値が出現する. 例えば,$y_{i} = 0.5000$のとき,$y_{i +1} = 0.4999$のような値が出現する。更に$x_{i+2}$は$x_{i+1}$と相関が最も強く、またそれよりは弱いが、$x_{i}$とも相関しているため、$y_{i+1},y_{i}$に近い値(例えば$y_{i +2} = 0.4997$)が出現する。
(注意:先程, $K_{nn'} = \lambda^{2} \phi_{j}(x_{n})\phi_{j}(x_{n'})$ の定義において$x,x'$の値の近さがそのまま,$y,y'$ の近さに対応することを意味しないといったが、今の場合は$x,x'$の近さとカーネルの値の近さに対応している。)
このように今与えられた共分散行列は隣接する点同士の相関が非常に強いので、乱数を振って$y_{i}$の値を決めているにもかかわらず、隣接する点は非常に近い値をとっている。
最後に同じ共分散行列を持つガウス分布から様々ななめらかな曲線が出力されるところをみて終わる。
x = np.linspace(1,4,500)
# x の入力は同じなので共分散行列はすべて同じ
for num in range(5):
y = gauss(x)
plt.scatter(x,y,s = 3)
plt.grid()
plt.show()
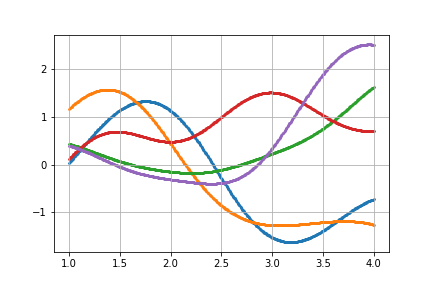
実際に見ると様々な曲線がランダムに描かれている。
(イメージとしては, 最初の点$x_{1}$の位置はランダムであるが、次の点は$x_{1}$に近い点が現れ、$x_{3}$以降も前の点から近い点が得られるという操作を繰り返してこのような曲線が描かれている.)