リアルタイムML基盤の現状と課題
リアルタイム機械学習(ML)は、データが到着するとすぐに処理し、即座に意思決定を行うシステムを指します。私たちが日常的に利用するサービスの多くは、このようなシステムに支えられています:
- 配車アプリの価格決定やETA計算
- ECサイトの商品レコメンデーション
- クレジットカード不正検知
- SNSのフィードやコンテンツのパーソナライゼーション
- LLMのための検索拡張生成(RAG)
Chip Huyenによれば、リアルタイムMLは主に「ストリーミングデータを使用して、より正確な予測を生成し、変化する環境にモデルを適応させるアプローチ」です。
これらのシステムを支える基盤技術として、「特徴量エンジニアリング」が極めて重要です。特徴量とは、MLモデルへの入力となるデータポイントのことで、その計算と管理は複雑な課題となっています。エンドツーエンドのリアルタイムMLシステム構築における最大の課題は、堅牢な特徴量エンジニアリング/計算/ストレージパイプラインの作成と維持にあります。
リアルタイムML基盤の歴史的発展
1. 初期のカスタム実装時代
最初は各チームが独自のパイプラインを開発していました。これはPythonスクリプト群やPandas/Sparkの関数の寄せ集めで、一貫性に欠け、バグも多く、開発サイクルも遅いものでした。
2. Feature Store(特徴量ストア)の登場
この問題に対処するため、Feature Storeが登場しました。これは特徴量のメタデータモデル(スキーマ、データ型、ID等)を提供し、ホットストレージ(Redis等)とコールドストレージ(SQL、データレイク等)へのコネクタを備えたストレージレイヤーです。代表例としてFeastがあります。
Feastのサイトによれば、「Feature Storeは機械学習のためのエンドツーエンドのオープンソースプラットフォームで、チームが特徴量を定義、管理、発見、および提供することを可能にします」。しかし、Feature Storeは主に特徴量のメタデータと保存に焦点を当てており、計算レイヤーの管理という課題を完全には解決できませんでした。
3. Feature Platform(特徴量プラットフォーム)の台頭
そこで、Feature Store + Feature Computation Engine(s)の組み合わせである「Feature Platform」が登場しました。これらは異なる計算エンジンを組み合わせ、プラットフォーム化して提供するものです。代表例として2020年に登場したTecton.aiや2022年に登場したFennel.aiなどがあります。
これらはMLデータパイプラインを自動化するための特徴量プラットフォームですが、これらはSaaSプロダクトであり、ベンダーロックインという課題を抱えています。
現在のリアルタイムML基盤の3種類の特徴量
現代の特徴量プラットフォームは、一般的に以下の3種類の特徴量をサポートしています:
1. オフライン特徴量(バッチ特徴量)
- 過去データに対してバッチ処理で計算され、モデルの学習/検証に使用
- 例:ユーザーが過去1週間に行った購入の平均数(過去1年分の各購入時点)
- レイテンシ要件:分単位〜日単位
- 計算インフラ:Spark、バッチ処理用Flink等
2. オンライン特徴量(ストリーミング特徴量)
- 新データが到着次第リアルタイムで計算され、モデル推論に使用
- 例:同じく購入平均数だが、データ受信時点でリアルタイム計算
- レイテンシ:ミリ秒〜秒単位
- 計算インフラ:Flink、Spark Streaming等
3. オンデマンド特徴量(リクエストタイム特徴量)
- 推論時にオンザフライで計算される無状態変換
- 例:サードパーティサービス(GPS位置情報等)の呼び出し、大規模埋め込みのドット積、ミリ秒精度のユーザー年齢計算
- レイテンシ:ミリ秒単位
- 計算インフラ:Pythonワーカーフリート(Celeryや独自実装)
現状の主な課題
これらの特徴量タイプをサポートするために、システムは2〜3の異なる計算エンジンに依存し、言語間(Java/Python)の統一インターフェースや、一貫した計算モデルを提供する必要があります。
この状況から、現在のリアルタイムML基盤には以下の選択肢しかありません:
-
マネージド特徴量プラットフォームの利用 - ベンダーロックイン、クローズドソース、特定クラウドへの依存
-
自社インフラの構築 - 複数の異種計算エンジン(Spark + Flink)の連携、異なる言語間のAPI統一、オーケストレーション層の構築が必要で、開発・運用コストが非常に高い
-
オンプレミスセットアップ - 上記両方の問題(社内インフラ保守+クラウド依存)を抱える
根本的な問題:全ての特徴量タイプに対して単一の統一された計算レイヤーを提供するオープンソースの特徴量計算エンジンが存在しない
Volgaによる新しいアプローチ
ここからがこの記事の本題でもありますが、そこで注目されているのがVolgaです。
Volgaは、これらの課題に対する新しい解決策として登場しました。モダンなAI/MLアプリケーション向けに設計されたオープンソースのリアルタイムデータ処理/特徴量計算エンジンです。
ハイブリッドアプローチ
VolgaはRay上に構築され、ハイブリッドなプッシュ+プルアーキテクチャを採用しています:
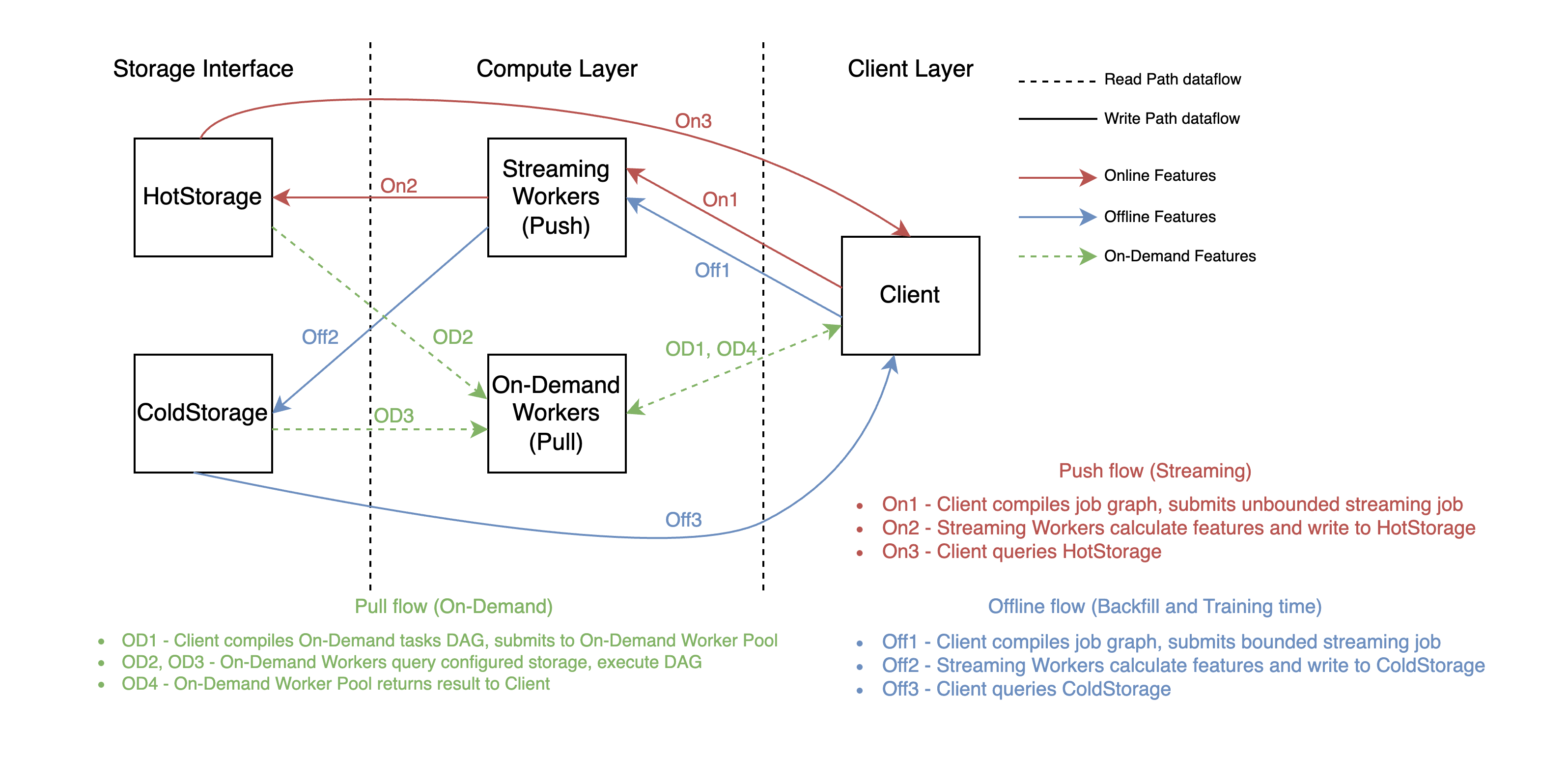
-
プッシュ部分(ストリーミングエンジン) - Ray Actors、ZeroMQ、Rustを使用したカスタムストリーミングエンジン。Python中心のAPIでシームレスなストリーミングデータ処理を実現。
-
プル部分(オンデマンド計算レイヤー) - リクエスト/推論時に任意の処理を実行するワーカー。メタモデルの照会、埋め込みドット積などを処理。
Ray(レイ)とは、UC Berkeleyの研究から生まれた分散コンピューティングフレームワークで、2016年に最初にオープンソース化されました。現在はAnyscale社が開発をリードし、Pythonプログラミングモデルを使って複雑な分散システムを簡単に構築できるよう設計されています。Kubernetes連携や自動リソース管理機能も備えており、機械学習ワークロードに最適化されています。
この設計により、Volgaはすべての特徴量タイプを一つの統合された計算レイヤーで処理できるそうです。
Volgaの特徴
Volgaは以下のような特徴を持っています:
-
単一計算レイヤー - オフライン、オンライン、オンデマンドの全特徴量タイプを一つのエンジンでサポート
-
一貫したAPI - Pandas風の直感的なAPIで、オンライン/オフライン/オンデマンドの一貫した特徴量定義を実現
-
クロスランゲージ課題の解消 - Python中心の設計により、Java/Pythonの架け橋が不要
-
オープンソースとベンダー非依存 - ベンダーロックインなしで、自由にカスタマイズ可能
-
簡易セットアップ - JVMベースの重いシステム構成が不要で、最小限のセットアップで動作
Volgaがもたらす可能性
Volgaの作者であるAndrey Novitskiyによれば、Volgaは「Python中心のランタイムを提供し、パフォーマンス向上のためにRustを活用し、便利なPandas風のAPIによってデータエンティティ、モジュラーなオンライン/オフライン/オンデマンドパイプラインとソース、一貫したオンライン+オフラインの特徴量計算セマンティクス、設定可能なデータ/ストレージコネクタ、特徴量検索、リアルタイム配信、オンデマンド要求時計算を定義できる」システムです。
まとめ
Chip Huyenの指摘するように、「リアルタイム機械学習は主にインフラストラクチャの問題であり、その解決にはデータサイエンス/MLチームとプラットフォームチームの協力が必要」です。「オンライン推論と継続的学習の両方が成熟したストリーミングインフラストラクチャを必要とする」中で、Volgaのようなツールが重要な役割を果たすでしょう。
リリースロードマップはGitHubで確認でき、主要なアーキテクチャの検証と開発が進められています。Volgaのブログによれば、ストリーミングエンジンはミリ秒単位のレイテンシの高スループットを達成し、スケーラビリティテストも実施されているそうです。
AI/MLシステムを構築する開発者やデータサイエンティストの皆さんにとって、Volgaは注目に値するプロジェクトではないでしょうか
参考URL
- Volga GitHub リポジトリ - プロジェクトのソースコードとドキュメント
- Volga ブログ - 開発者による技術記事シリーズ
- Real-time machine learning: challenges and solutions - リアルタイムMLの課題と解決策
- Feast - The Open Source Feature Store for Machine Learning - 代表的なオープンソース特徴量ストア
- Tecton - The Feature Platform for Machine Learning - マネージド特徴量プラットフォーム