この記事で学べる事
・簡単なページネーション付きwebページのデーターをスクレピング出来る。
・BeautifulSoupを使ってデーターのスクレピングが出来る。
・requestsの基本的な使い方。
・jupyter notebookの基本的な使い方
前提環境
・Mac OS
・python3.x系を使用している
・以下のモジュールがある(太字)
beautifulsoup4 4.9.3
certifi 2020.11.8
chardet 3.0.4
chromedriver-binary 87.0.4280.20.0
click 7.1.2
cssselect 1.1.0
idna 2.10
isodate 0.6.0
lxml 4.6.2
numpy 1.19.5
pandas 1.2.0
parsel 1.6.0
pip 20.3.3
ppprint 0.1.0
pyparsing 2.4.7
python-dateutil 2.8.1
pytz 2020.5
PyYAML 5.3.1
rdflib 5.0.0
requests 2.25.1
selectorlib 0.16.0
selenium 3.141.0
setuptools 49.2.1
six 1.15.0
soupsieve 2.1
SPARQLWrapper 1.8.5
urllib3 1.26.2
w3lib 1.22.0
ない場合は以下をコピペ
pip install beautifulsoup4 && pip install requests && pip install pandas
以下のwebページを参考にスクレピングしていきます。
opencoddez
全コード
from bs4 import BeautifulSoup
import csv
import pandas as pd
from pandas import DataFrame
import requests
import logging
import pdb
# requests.getする際にクライアント端末のヘッダー情報をサーバーに渡す。
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
article_link = []
article_title = []
article_para = []
article_author = []
article_date = []
def main():
opencodezscraping('https://www.opencodez.com/page', 0)
data = {'Article_link': article_link, 'Article_Title': article_title, 'Article_para': article_para, 'Article_Author':article_author, 'Ariticle_Date': article_date}
df = DataFrame(data, columns=['Article_link', 'Article_Title', 'Article_para', 'Article_Author', 'Article_Date'])
df.to_csv('./Opencodez_Articles.csv')
with open('Opencodez_Articles.csv', 'w') as csv_file:
fieldnames = ['Link', 'Title', 'Para', 'Author', 'Data']
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
def opencodezscraping(webpage, page_number):
next_page = webpage + str(page_number)
response = requests.get(next_page, headers=headers)
logging.info(f'scraping {page_number} page ・・・・')
soup = BeautifulSoup(response.content, 'html.parser')
soup_title = soup.findAll('h2', {'class': 'title'})
soup_para = soup.findAll('div', {'class': 'post-content image-caption-format-1'})
soup_date = soup.findAll('span', {'class': 'thetime'})
for x in range(len(soup_title)):
article_title.append(soup_title[x].a['title'])
article_link.append(soup_title[x].a['href'])
article_author.append(soup_para[x].a.text.strip())
article_date.append(soup_date[x].text)
article_para.append(soup_para[x].text.strip())
#ぺージが無くなるまで関数を実行。
if status_code != 404:
page_number = page_number + 1
opencodezscraping(webpage, page_number)
# これが記述されているファイルがメインファイルならばmain()関数を実行。
if __name__ == '__main__':
logging.basicConfig(level=logging.INFO)
main()
[参考記事]
関数単位でそれぞれ説明してきます。
main
主な用途は関数の呼び出し、オブジェクトの定義です。
def main():
#opencodezscraping関数の呼び出し
opencodezscraping('https://www.opencodez.com/page', 0)
#DataFrameに渡すデーター群
data = {'Article_link': article_link, 'Article_Title': article_title, 'Article_para': article_para, 'Article_Author':article_author, 'Ariticle_Date': article_date}
df = DataFrame(data, columns=['Article_link', 'Article_Title', 'Article_para', 'Article_Author', 'Article_Date'])
#渡されたデーターをCsvに出力
df.to_csv('./Opencodez_Articles.csv')
opencodezscraping
def opencodezscraping(webpage, page_number):
#urlとページ番号を連結
next_page = webpage + str(page_number)
#webページを取得
response = requests.get(next_page, headers=headers)
logging.info(f'scraping {page_number} page ・・・・')
#BeautifulSoupを定義
soup = BeautifulSoup(response.content, 'html.parser')
#記事タイトルを取得
soup_title = soup.findAll('h2', {'class': 'title'})
#記事説明を取得
soup_para = soup.findAll('div', {'class': 'post-content image-caption-format-1'})
#記事投稿日を取得
soup_date = soup.findAll('span', {'class': 'thetime'})
#記事のタイトルの数だけループ
for x in range(len(soup_title)):
#上部で定義した環境変数群に各データを追加
article_title.append(soup_title[x].a['title'])
article_link.append(soup_title[x].a['href'])
article_author.append(soup_para[x].a.text.strip())
article_date.append(soup_date[x].text)
article_para.append(soup_para[x].text.strip())
#ページが無くなるまで、関数を呼びだす。
if status_code != 404:
page_number = page_number + 1
opencodezscraping(webpage, page_number)
jupternotebookで挙動の確認
jupyternotebook(※pythonの対話型コンソールでもOK)でrequests.get,getsoupのfindall()メソッドの等を確認しましょう。
jupyternotebookがない場合は以下をコピペ。
pip instal jupyter notebook
起動は以下コマンドをコピペ。
webブラウザーが起動する。
jupyter notebook
requests.getの確認
webページにgetリクエストを送信し、正常にresposeが返ってくる事を確認。
以下の場合、ステータスコードが200なので正常にページを取得できている事が確認できます。

findAll()の確認
# 記事タイトルを取得
soup_title = soup.findAll('h2', {'class': 'title'})
# 記事説明を取得
soup_para = soup.findAll('div', {'class': 'post-content image-caption-format-1'})
# 記事投稿日を取得
soup_date = soup.findAll('span', {'class': 'thetime'})
それぞれ三つのメソッドの返り値を確認しましょう。
記事タイトル
以下では、記事のタイトル情報を含むhtmlタグを取得している。

結果から、aタグのtitle属性の値にタイトル情報は含まれるので、個別の情報を抜き出すには以下のようにする。

記事説明
以下では、記事説明情報を含むhtmlタグを取得している。

結果から,記事説明文はpタグ内にあることがわかる。
個別に説明文を取得する場合は以下。

strip()は文字列内に含まれる特殊文字を消してくる。
記事投稿日
以下では、記事の投稿日情報を含むhtmlタグを取得している。
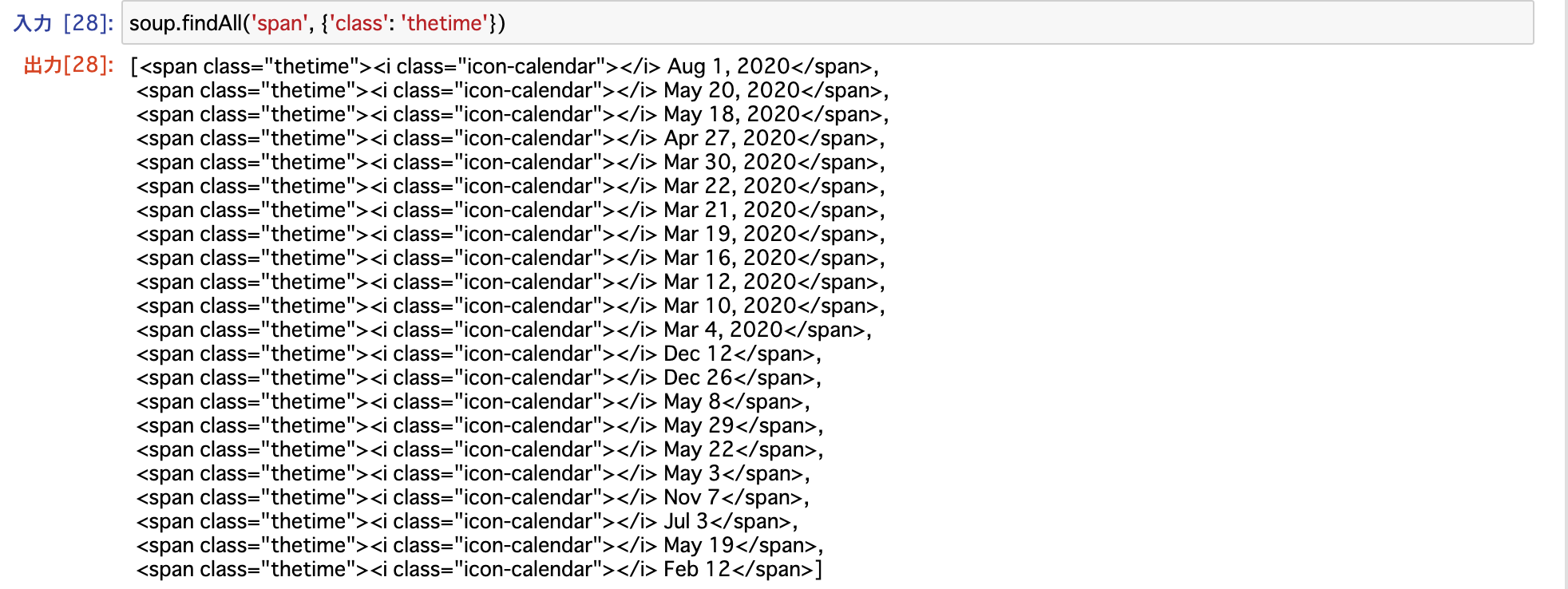
結果から、class='thetime'を持つspanタグ内に記事投稿日があるのがわかる。
個別に投稿日を取得する場合は以下。

まとめ
今回はurlのパラメーターが単純で、page_numberの値を一つずつインクリメントして指定すれば
それをrequests.getしてページ情報が取得できた。
urlのパラメーターが複雑なサイトをスクレピングするとなると一気に難しくなる。
僕は今とあるECサイトをスクレピングしようとしているが、複雑怪奇で泣いています。
完成したらまた記事にします!
間違っているところがあれば、どしどし指摘して頂ければ幸いです!
参考記事
Web Scraping a Site with Pagination using BeautifulSoup