psql や pgcli や mysql みたいにRDSのData APIをクエリするためのクライアントがほしいなと思いChatGPTに頼んだらサクッと作ってくれたので、こちらでも共有しておきます。
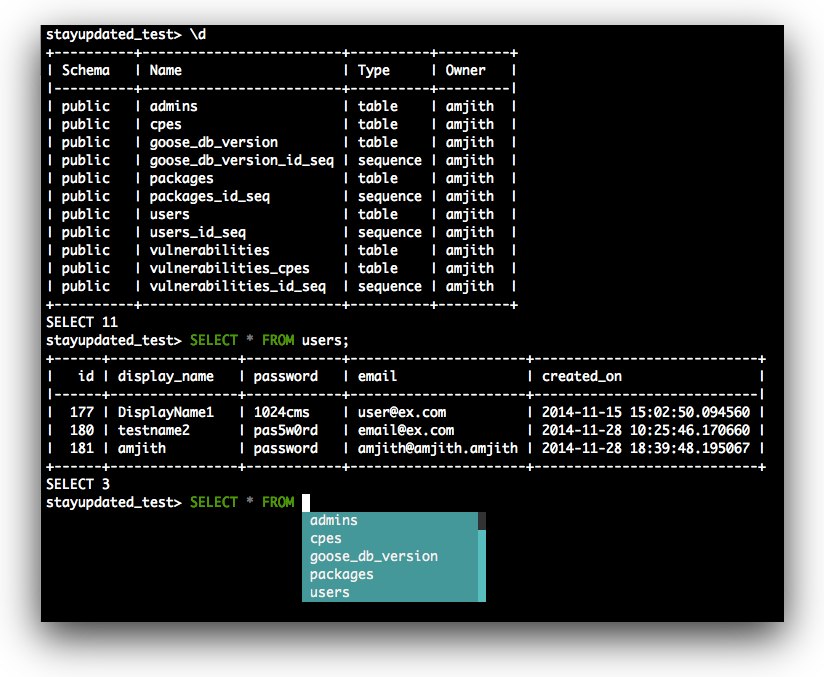
↓こんなのが欲しかった。(これはpgcli)
Pythonコード
rds-data-cli.py などの名前で保存して実行権限つけておきます。
#!/usr/bin/env python3
import os
import sys
import boto3
import pandas as pd
import yaml
import argparse
from dataclasses import dataclass
from typing import Any, Dict, List, Optional
from prompt_toolkit import PromptSession
from prompt_toolkit.completion import WordCompleter
from botocore.exceptions import BotoCoreError, ClientError
@dataclass
class DBConfig:
profile: str
dbname: str
dbarn: str
secretarn: str
# Example .rdsConfig.yaml file format:
# mydatabase:
# profile: my-aws-profile
# dbname: mydb
# dbarn: arn:aws:rds:region:account-id:cluster:my-cluster
# secretarn: arn:aws:secretsmanager:region:account-id:secret:my-secret
def load_config(config_file: str) -> Dict[str, DBConfig]:
"""Load the YAML configuration file."""
try:
with open(config_file, 'r') as file:
raw_config = yaml.load(file, Loader=yaml.FullLoader)
return {key: DBConfig(**value) for key, value in raw_config.items()}
except FileNotFoundError:
sys.exit(f"Configuration file not found: {config_file}")
except yaml.YAMLError as e:
sys.exit(f"Error reading configuration file: {e}")
def execute_query(db_config: DBConfig, sql: str) -> pd.DataFrame:
"""Execute the SQL query using AWS RDS Data API."""
try:
sess = boto3.session.Session(profile_name=db_config.profile)
rds_data = sess.client('rds-data')
response = rds_data.execute_statement(
resourceArn=db_config.dbarn,
secretArn=db_config.secretarn,
database=db_config.dbname,
includeResultMetadata=True,
sql=sql
)
column_names = [col['name'] for col in response['columnMetadata']]
rows = [[list(col.values())[0] for col in row] for row in response['records']]
return pd.DataFrame(rows, columns=column_names)
except (BotoCoreError, ClientError) as e:
print(f"AWS RDS Data API error: {e}")
return pd.DataFrame()
def paginate_dataframe(df: pd.DataFrame, page_size: int) -> None:
"""Paginate the DataFrame for better viewing."""
total_rows = len(df)
page = 0
while True:
start = page * page_size
end = start + page_size
if start >= total_rows:
print("No more rows to display.")
break
print(df.iloc[start:end])
user_input = input("Press Enter to see the next page, or type 'q' to quit: ")
if user_input.lower() == 'q':
break
page += 1
def interactive_mode(config: Dict[str, DBConfig]) -> None:
"""Launch an interactive SQL shell."""
print("Entering interactive mode. Type 'exit' to quit.")
session = PromptSession(history=PromptSession().history)
session.history.append_string("select * from information_schema.tables;")
sql_completer = WordCompleter([
"SELECT", "FROM", "WHERE", "INSERT", "UPDATE", "DELETE", "LIMIT", "JOIN", "ORDER BY", "GROUP BY"
], ignore_case=True)
config_name = input("Enter config name: ")
db_config = config.get(config_name)
if not db_config:
sys.exit("Invalid config name")
while True:
try:
sql = session.prompt("sql> ", completer=sql_completer)
if not sql.strip():
continue
if sql.lower() in ['exit', 'quit']:
print("Exiting interactive mode.")
break
result = execute_query(db_config, sql)
paginate_dataframe(result, page_size=10)
except KeyboardInterrupt:
print("Exiting interactive mode.")
break
except Exception as e:
print(f"Error: {e}")
def main() -> None:
parser = argparse.ArgumentParser(description="Query AWS RDS Data API from the command line.")
parser.add_argument("config_name", nargs="?", help="The name of the database configuration to use.")
parser.add_argument("sql", nargs="?", help="The SQL query to execute.")
parser.add_argument("-i", "--interactive", action="store_true", help="Launch interactive mode.")
args = parser.parse_args()
config_file = os.path.join(os.getcwd(), '.rdsConfig.yaml')
config = load_config(config_file)
if args.interactive:
interactive_mode(config)
elif args.config_name and args.sql:
db_config = config.get(args.config_name)
if not db_config:
sys.exit("Invalid config name")
result = execute_query(db_config, args.sql)
paginate_dataframe(result, page_size=10)
else:
parser.print_help()
if __name__ == "__main__":
main()
必要なパッケージ
以下の4つのパッケージが必要です。
pip install prompt-toolkit pyyaml boto3 pandas
設定ファイル
YAML形式で用意して .rdsConfig.yaml として同じディレクトリにおいておきます。
stg:
profile: my-aws-profile
dbname: mydb
dbarn: arn:aws:rds:region:account-id:cluster:my-cluster
secretarn: arn:aws:secretsmanager:region:account-id:secret:my-secret
prd:
profile: my-aws-profile
dbname: mydb
dbarn: arn:aws:rds:region:account-id:cluster:my-cluster
secretarn: arn:aws:secretsmanager:region:account-id:secret:my-secret
実行してみます
-i でインタラクティブモードで実行できます。
config名にYAML設定ファイルのKeyとなっている文字列を入れます。
$ ./rds-data-cli.py -i
Entering interactive mode. Type 'exit' to quit.
Enter config name: stg
あとはクエリしてみるだけです。Pandasをプリントして表示されます。
表示に関してページネーションもしてくれます。
sql> select * from information_schema.tables;
table_catalog table_schema table_name ... is_insertable_into is_typed commit_action
0 postgres pg_catalog pg_type ... YES NO True
1 postgres pg_catalog pg_foreign_table ... YES NO True
2 postgres pg_catalog pg_roles ... NO NO True
3 postgres pg_catalog pg_settings ... NO NO True
4 postgres pg_catalog pg_prepared_statements ... NO NO True
5 postgres pg_catalog pg_user_mappings ... NO NO True
6 postgres pg_catalog pg_stat_progress_vacuum ... NO NO True
7 postgres pg_catalog pg_stat_progress_cluster ... NO NO True
8 postgres pg_catalog pg_stat_progress_create_index ... NO NO True
9 postgres pg_catalog pg_stat_progress_basebackup ... NO NO True
[10 rows x 12 columns]
Press Enter to see the next page, or type 'q' to quit:
exit で出ることができます。
sql> exit
Exiting interactive mode.
細かくは調整したいところありますが、ちょっと作ってもらっただけなのに、十分実用的で便利です。
