Glueの開発エンドポイントとは
AWS Glueはデータレイクやビッグデータ系の複数の機能を持ったサービスですが、その主な機能の一つに、サーバレスのSparkとして使えるETLジョブ機能があります。
AWS Glueの開発エンドポイントはこのETLジョブの開発を行うための仕組みです。
GlueのETLジョブはサーバーレスで実行されるSparkなので、ETLスクリプトを投入すればジョブを実行はしてくれるのですが、OSにログオンしたり、デバッグをしながら開発することができません。
開発エンドポイントがあると、Jupyter NotebookやZeppelinでGlueの管理しているSparkにアクセスしてインタラクティブにコードを実行しながら、開発を進めることができます。
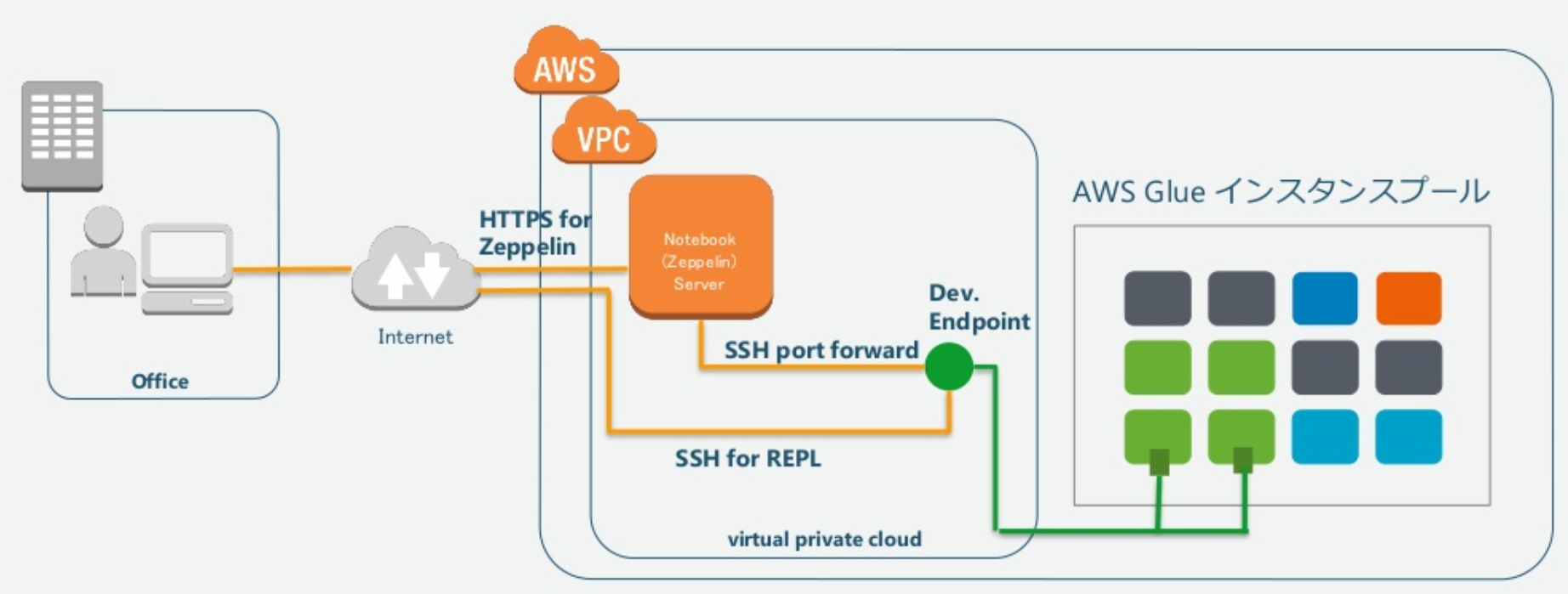
図の引用元: https://www.slideshare.net/AmazonWebServicesJapan/aws-black-belt-aws-glue/50
Glue開発エンドポイントの費用
Glueの開発エンドポイントは高い
開発エンドポイントという名前から、サーバーレスのSparkに接続できるポイントが作成されるだけ。費用は実際にジョブを実行して計算している時間だけお金がかかると考えてしまいがちですが、そこが落とし穴になります。
開発エンドポイントは作成している間、設定されただけのSparkリソースがエンドポイントにアサインされてしまいます。
もう少し具体的に言うと、裏でインスタンスが立ち上がり、処理を動かしていなくても、そのリソース分が課金されます。先程の図で表せば、以下の赤枠のインスタンスは開発エンドポイントを起動している間、専有されていて課金されることになります。
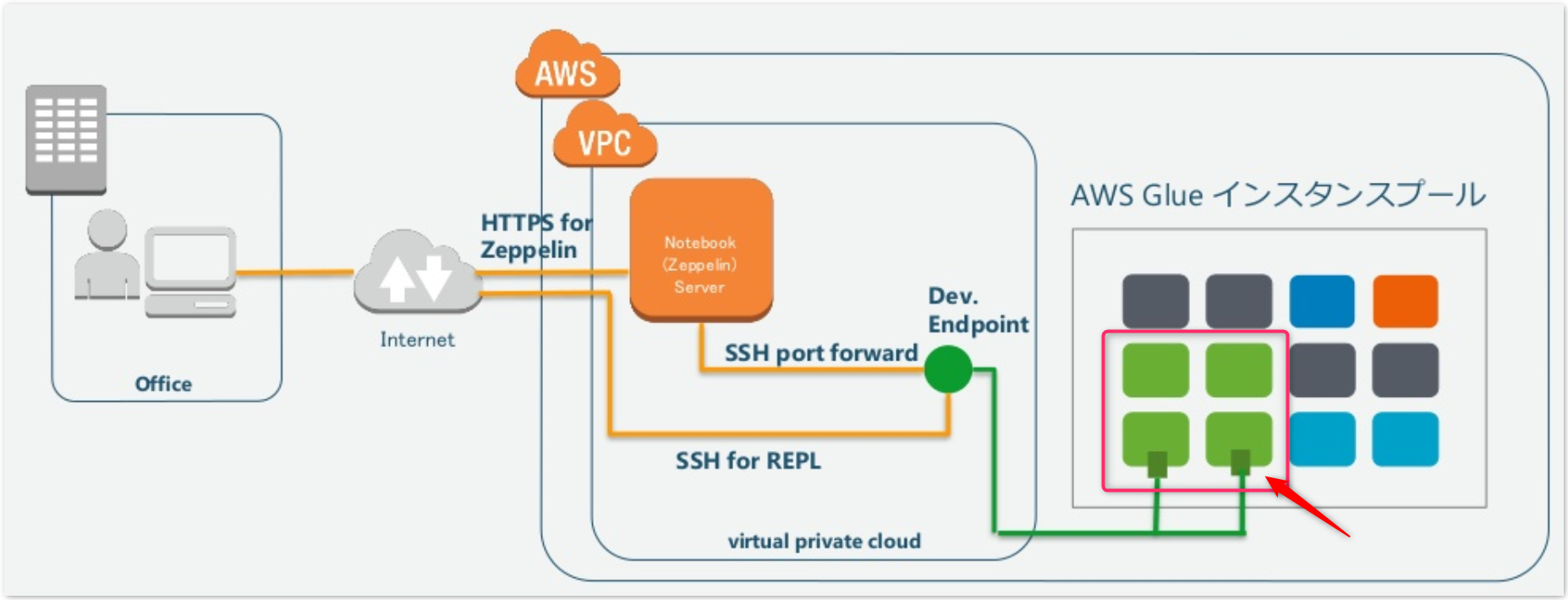
開発エンドポイントの実際の費用
2019/12/08時点でのGlueの金額は以下の通りです。
1DPU = 0.44USD/時間
DPU というのはGlueのリソースの単位になるのですが、以下のように定義されています。
1 個の DPU (Data Processing Unit) では 4 つの vCPU と 16 GB のメモリが提供されます。
https://aws.amazon.com/jp/glue/pricing/
このDPUですが、Glueのウィザードに沿ってエンドポイントを作成すると、デフォルトで 5 DPU が割当たります。4CPU 16GBRAMのインスタンスが5台。20CPU 80GB RAM と、ちょっとサンプルデータで、コード動かしてみるには大きめなリソースが割当たります。
では、このデフォルトの5 DPU の設定として起動すると月額料金はどのくらいでしょう?
ちょっと計算してみると、1ヶ月間 開発エンドポイントを起動しておくと、タイトルの通り 18万円 の費用になります。
$0.44/Hour * 5DPU * 24Hour * 31Days
= $1,636.8 ≒ 180,048円
※ 1USD =110円計算
開発エンドポイント破産への対策
AWSの予算機能
AWSの予算アラート等の話は、ここで書くまでもないと思いますので省略します。
開発エンドポイント作成用のスクリプトを準備する
1度知ってしまえば、DPUは注意するべき最重要設定項目なのですが、Glue初心者だと気付きにくいポイントだったりします。
と言うのも、このDPU 、かなり重要な設定にも関わらず、知らないとデフォルトでは折りたたまれて隠れている設定だったりします。
↓ここに隠されている。
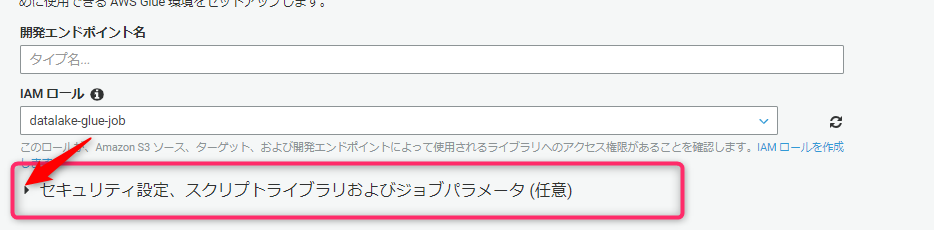
↓開くと設定部分が表示される。
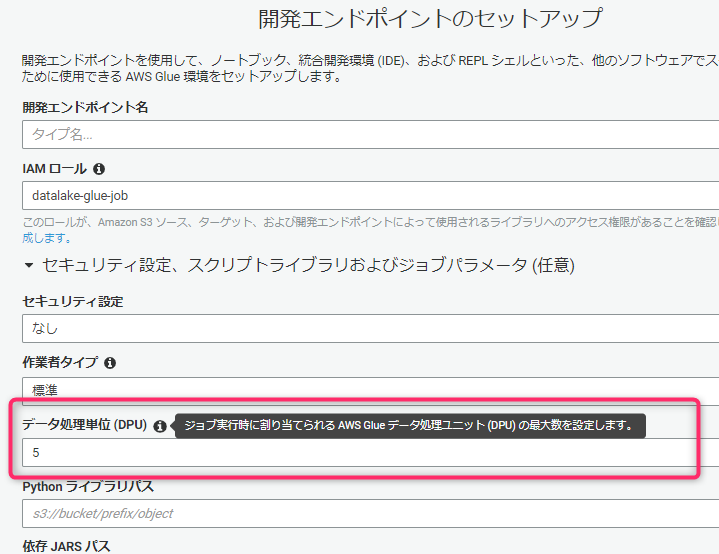
このようにGUIがわかりにくいので、Glueに不慣れなメンバーが参画してきた際に、小さい処理でも`5 DPU`で起動して作業してしまいがちなポイントです。
対策として、Glueの開発エンドポイント作成用のスクリプト等を作成して、デフォルトパラメータを最小構成の 2 DPU などに設定しておくという方法があります。
パラメータが多いCLIコマンドを使う場合は、 --generate-cli-skeleton が便利です。ここから必要なパラメータを埋めたJSONファイルを作成します。
件のDPUの設定は NumberOfNodes の部分になります。
EndpointName には開発者名を入れた名前にしておくと、残っていた時に問い合わせる先がわかって便利です。
$ aws glue create-dev-endpoint --generate-cli-skeleton
{
"EndpointName": "",
"RoleArn": "",
"SecurityGroupIds": [
""
],
"SubnetId": "",
"PublicKey": "",
"PublicKeys": [
""
],
"NumberOfNodes": 0,
"WorkerType": "G.2X",
"GlueVersion": "",
"NumberOfWorkers": 0,
"ExtraPythonLibsS3Path": "",
"ExtraJarsS3Path": "",
"SecurityConfiguration": "",
"Tags": {
"KeyName": ""
},
"Arguments": {
"KeyName": ""
}
}
上記で設定したJSONを --cli-input-json で読み込みます。これで簡単に適切なDPUを使った開発エンドポイントが作れます。
$ aws glue create-dev-endpoint --cli-input-json file://devendpoint.json
エンドポイント削除用のバッチもつくっておきましょう。
aws glue delete-dev-endpoint --endpoint-name dev-otomo
Lambda等で長時間実行の開発エンドポイントを検知
開発エンドポイントを使う時には、Notebookで小規模のサンプルデータを使ってインタラクティブに挙動を確認しながらの開発が多いと思うので、長時間実行されている開発エンドポイントがあれば、通知する仕組みをLambda等で作ってみても良いと思います。
# 12時間以上起動している開発エンドポイントを検知
MAX_TIME = 60 * 60 * 12
def get_glue_endpoints():
logger.info("get glue client")
cli = boto3.client('glue')
now_datetime = datetime.datetime.now(datetime.timezone.utc)
endpoints = cli.get_dev_endpoints()['DevEndpoints']
logger.info("Glue Endpoint -> {}".format(endpoints))
return endpoints
def get_longrun_endpoints_count():
endpoints = get_glue_endpoints()
now_datetime = datetime.datetime.now(datetime.timezone.utc)
logger.info("endpoints exists -> {}".format(len(endpoints)))
longtime_endpoints = [e for e in endpoints if (now_datetime - e['CreatedTimestamp']).total_seconds() > MAX_TIME]
if longtime_endpoints:
logger.info("longtime endpoints -> {}".format(longtime_endpoints))
return len(longtime_endpoints)
def detect_glue_longrun_endpoint():
logrun_endpoints_count = get_longrun_endpoints_count()
if logrun_endpoints_count > 0:
# SNS等で通知処理
logger.error("longrun endpoints detected -> {} endpoints".format(logrun_endpoints_count))
else:
logger.info("long run endpoints not detected")
SageMakerを使わない構成(万人にオススメではない)
Glueの開発エンドポイントに接続する方法としてデフォルトではSageMakerが利用されます。当然、SageMakerのインスタンスにもお金がかかります。
これは万人にオススメする内容でも無いのですが、SageMakerを使わずに、既存のEC2インスタンスからGlueの開発エンドポイントに接続する方法もあります。
Glueの開発エンドポイントはApache Livyを介して接続することでJupyter NotebookからSparkを制御できます。EC2上で起動したJupyter Notebookから開発エンドポイントへ繋ぐ方法です。
Glueの開発環境をVPC内に閉じるためSageMaker止めてEC2で構築してみた
さいごに
開発エンドポイントは、特にGlue使い始めでお金溶かしてしまいがちなポイントですが、情報少なそうなので書いてみました。