以下のようにAWS Data Wrangler使ってAthenaからロードした時系列データを時間単位毎に集計する処理を実行していました。
df.resample("min").mean()
よく考えればSQLでもWindow関数使えばできるよな。Athenaでもできるなかな。ということでAthena(というかPresto)のリファレンス読みながら探ってみました。
結論として date_trunc関数 を使うことで似たような実装が可能でした。以下にサンプルを書いておきます。
使うのは以下のsampleテーブルです。
| Col | Type | Desc |
|---|---|---|
| time | string | ISO8601形式の文字列形式で入っている |
| value | int | サンプル値 |
WINDOW句で定義したもの使い回せなそうなのでPARTITION BYを何度も書くのが面倒ですが。
SELECT
time,
DATE_TRUNC('minute',from_iso_timestamp(time)),
value,
MAX(value) OVER (PARTITION BY DATE_TRUNC('minute',from_iso8601_timestamp(time)) ORDER BY time) AS value_max,
MIN(value) OVER (PARTITION BY DATE_TRUNC('minute',from_iso8601_timestamp(time)) ORDER BY time) AS value_min,
AVG(value) OVER (PARTITION BY DATE_TRUNC('minute',from_iso8601_timestamp(time)) ORDER BY time) AS value_avg,
ROW_NUMBER() OVER (PARTITION BY DATE_TRUNC('minute',from_iso8601_timestamp(time)) ORDER BY time) AS row_num
FROM "sample"
ORDER BY time
上記のSQL実行してみた結果です。WINDOW関数慣れてない人向けに少し注釈付けています。
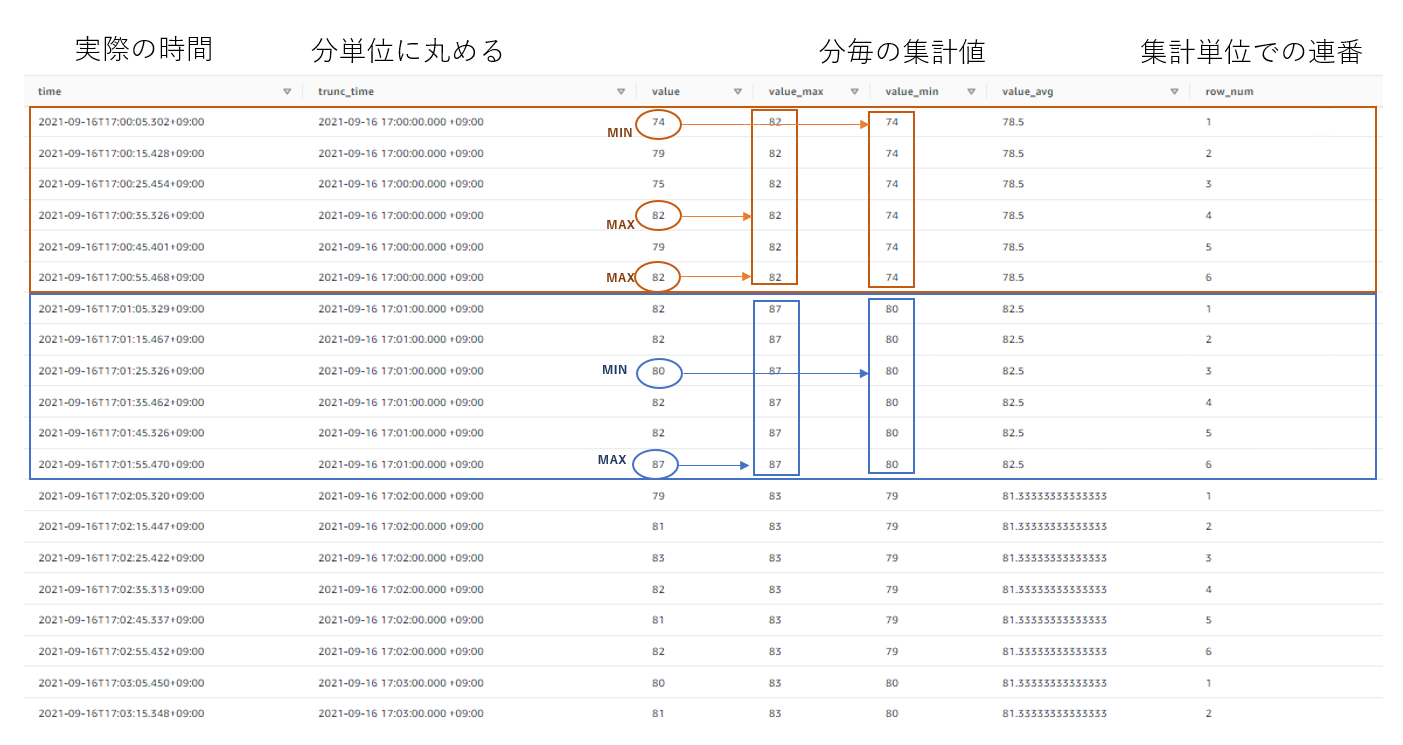
つまりはパーティションを作れば良いので、UNIXTIMESTAMP形式にしてEXCELのFLOOR関数のように特定の秒毎に切る方法もあります。
-- 15秒毎のパーティション作成
FLOOR(unix_timestamp/15) * 15
-- 30秒毎のパーティション作成
FLOOR(unix_timestamp/30) * 30
参考URL