はじめに
社内に蓄積された膨大なナレッジを有効活用する手段として、生成AIのRAG(Retrieval-Augmented Generation) 型チャットボットが注目されています。RAG型チャットボットは、社内の文書データベースを検索して最新の情報を取得し、大規模言語モデル(LLM) の生成能力と組み合わせて回答を生成する仕組みです。これにより社内の独自知見や最新情報に基づいた高精度な回答が得られ、従来のQAシステムより実用的なビジネス活用が可能になります。
RAGを用いたLLMの回答生成イメージ
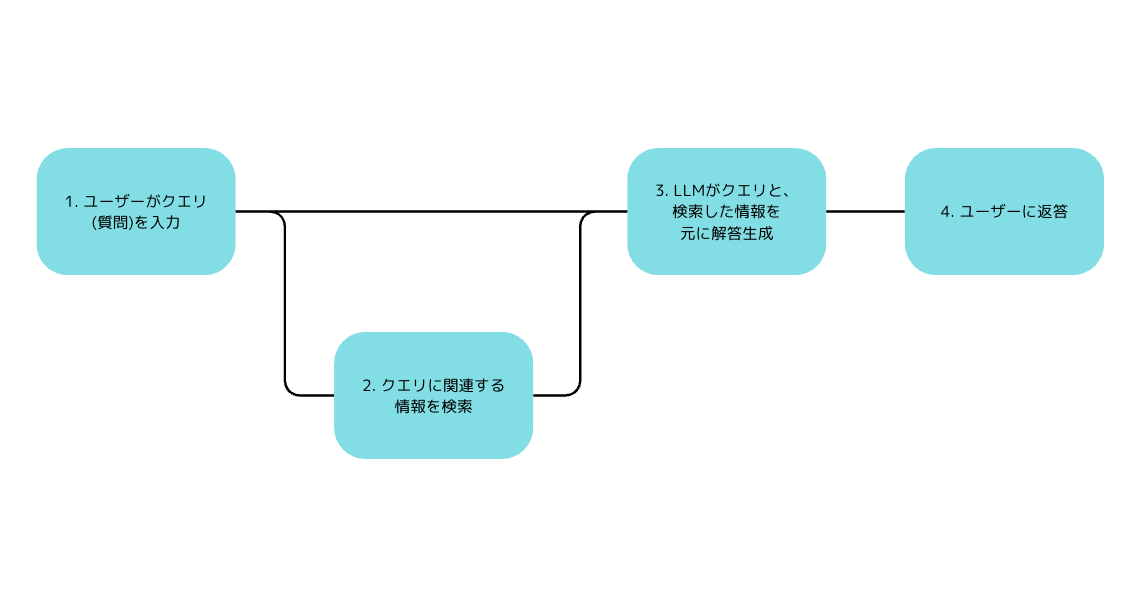
RAGアーキテクチャの概念図。ユーザーの質問に対し(①)、関連情報を内部データベースから検索し(②)、その結果をもとにLLMで回答を生成(③)してユーザーへ返答(④)する流れ。
このプロセスによりAIの回答精度が向上し、最新の社内情報に基づく信頼性の高い応答が可能となる。
本稿では、社内ナレッジ検索 を目的としたチャットボットを導入するにあたり、考えられる以下の導入形態について比較検討します。
- SaaS型サービスの利用: 専門ベンダーが提供するクラウドサービスを契約し、自社のナレッジをアップロードして使う形式
- Azure上で構築: Microsoft AzureのAzure OpenAIサービスや検索サービスを用いて、自社クラウド環境内にシステムを構築する形式
- AWSやGCPなど他クラウドで構築: 他のクラウドプラットフォーム上で、類似のLLMサービスや検索基盤を組み合わせて構築する形式
- オンプレミス構築: 自社サーバー上にオープンソース等のLLMと検索基盤を導入し、社内完結型で運用する形式
導入形態ごとの特徴比較 🔍
それぞれの導入モデルについて、コスト・機能・セキュリティ・拡張性の観点で特徴を整理します。
SaaS型ソリューション
コスト 💰
初期費用が低く抑えられるのが大きな特徴です。専門ベンダーのクラウドサービスを利用すれば、自社でサーバーやGPUを用意する必要がなく、契約後すぐに使い始められます。料金体系は月額費用やユーザー数に応じた課金が一般的で、小規模なスモールスタートに適しています。一方で利用ユーザーや問い合わせ数が増えると、それに比例して月額費用が高額になる可能性があります。長期的にはトータルコストが割高になるケースもあるため、将来の利用規模を見据えた費用試算が必要です。
提供機能・品質 ⚙️
多くの場合、チャットボットの基本的なUIとQA機能が提供されており、利用企業は自社の文書データをアップロードするだけで導入できます。サービスによってはPDFやWord、Excelなどのドキュメントをドラッグ&ドロップで登録するだけで自動的にインデックス化・ベクトル化され、すぐに質問応答が可能になる手軽さがあります。検索精度や回答の品質はベンダー側のエンジン性能に依存します。高度な生成AI(例えばGPT-4クラスのモデル)を裏側で使用しているサービスであれば回答精度や多言語対応力も高いですが、そうでない場合は専門用語への対応力や日本語のニュアンス理解に差が出る可能性があります。多言語対応についてもサービスごとに差異がありますが、グローバル展開しているベンダーのものは日本語を含む主要言語に対応しているケースが多いです。ログの記録や分析機能はベンダー提供の管理画面で基本的な利用統計を確認できる程度で、個別の発話内容の監査や社内ポリシーに沿ったログ保持を細かく制御するのは難しい場合があります。
セキュリティ 🔒
データ取り扱いの面では、自社の機密文書データをベンダーのクラウドに預けて利用する形になります。信頼できるベンダーであっても、自社外に情報を置くことに不安を持つ経営層も多いため、契約上のデータ保護措置(暗号化やアクセス制限、契約終了時のデータ削除保証など)を確認する必要があります。一般にパブリッククラウド上のサービスとなるため、自社専有環境ではなくマルチテナント環境で運用されます。他社データと論理的に分離されてはいるものの、情報漏えいやプライバシー保護の観点で自社構築型より信頼性が劣ると見なされることがあります。もっとも、著名な生成AI搭載チャットボットSaaS(例:MicrosoftやOpenAI系のサービス)の場合は「ユーザーの入力したプロンプトや社内データを学習用途に再利用しない」「一定期間後にログを消去する」などプライバシー配慮が公表されています。セキュリティ面の安心感を得るには、各サービスのプライバシーポリシーや認証取得状況(ISO27001やSOC2等)を確認し、自社のセキュリティ基準に適合するか精査することが重要です。
拡張性・統合柔軟性 🔄
SaaSは基本的にスケーラビリティが高く、ベンダー側でシステムを自動スケールしてくれるため、ユーザー数やQA頻度が増えても応答性能を維持しやすいです。ただし機能やインターフェースのカスタマイズ性は限定的で、提供された範囲内のUI・機能を使う形になります。他の社内システムとの統合については、APIが用意されていれば社内ポータルやTeams/Slackと連携させることも可能ですが、細かな連携要件(例えば社内の人事データベースと照合して回答内容を変える等)には対応できないこともあります。将来的にシステム拡張して社内のワークフローと結びつけたり、独自機能を追加したい場合、SaaSでは制約が大きいため対応が難しい点に留意が必要です。
Azure環境での構築(Azure OpenAI + Azureサービス)
コスト 💰
Azure上に自社専用のチャットボット環境を構築する場合、初期構築にある程度の開発コスト(システム設計・実装工数)が発生します。ただし基盤となるAzureの各サービス利用料は従量課金が中心で、使った分だけの支払いとなります。Azure OpenAIサービスの利用料金はOpenAI提供APIと概ね同等の単価(トークン使用量課金)であり、少ない利用からでも開始しやすいです。PoCで構築済みのRAG基盤を活かせるなら、追加開発を抑えつつ本格導入に移行できます。月額の運用費用は主にLLM利用料(APIコール課金)と検索インデックス維持費用、および付随するクラウドリソース(例えばアプリ実行環境やストレージ)のコストとなります。利用が増えればコストも増加しますが、不要時はスケールダウンしてコスト最適化が可能な点がクラウド利用の利点です。全社展開する場合でも、従量課金モデルのため明確な予測のもとでコスト管理がしやすく、長期的に見ても無駄の少ない運用が期待できます。
提供機能・品質 ⚙️
Azure上に構築する最大のメリットは、最先端のAIモデルと高度な検索機能を組み合わせられることです。Azure OpenAIサービスを使うことで、GPT-4など高精度で多言語対応力のあるモデルを利用可能です。これは日本語を含むあらゆる言語で高い理解度・生成品質を発揮し、専門性の高い質問や長文の要約などにも対応できます。検索部分ではAzure Cognitive Searchなどのサービスを活用でき、社内文書のインデックス作成やベクトル検索による類似文書検索を高精度に行えます。Azure Cognitive Searchは日本語を含む各言語の形態素解析や自然文検索にも対応しており、検索品質の面でも優れています。またAzureのAIサービスにはテキスト要約や言語検出などの機能もあるため、必要に応じてチャットボットの応答ロジックに組み込むこともできます。社内データ連携については、Azure ADでのシングルサインオンや権限管理、SharePointやOneDriveからのクロール、社内DBへの安全な接続(Azure上からVPN経由など)といった連携が比較的容易です。UIは要件に合わせて自由に構築できます。例えば社内WebポータルにチャットUIを埋め込んだり、Teamsのチャットボットとして提供することも可能です(Microsoft Bot FrameworkやPower Virtual Agentsを利用)。ログについても自社で管理でき、ユーザーの質問や回答履歴を詳細に記録・監査できます。Azure MonitorやApplication Insightsを使えばチャットボットの利用状況を分析したり、不適切な質問が無いか監視する仕組みも構築できます。
セキュリティ 🔒
Azureでの自社構築は、セキュリティ面で非常に高いコントロール性を持ちます。まずデータは自社のAzure環境下に保持され、ベクトルデータベースやインデックスも自社リソース上にあります。質問時にLLMへ送信する社内データの断片(プロンプト中の参照テキスト)もAzure経由でOpenAIモデルに渡されますが、Azure OpenAIサービスでは入力データや応答内容が他の顧客と共有されたり、モデルの学習に使われることが無いと公式に保証されています。さらに、AzureはGDPRやISO27001など企業向けの各種規制・標準に準拠しており、データの保存期間やアクセス権を細かく管理する機能も備えています。必要に応じてAzure OpenAIをプライベートネットワーク接続(Private Link) で利用し、社内ネットワークから直接アクセスさせることで、通信経路をインターネットから遮断することも可能です(※Azureの設定による)。こうした仕組みにより、クラウド上にありながら社内システムと同等のデータ機密性を実現できます。また、自社でログデータを保持・分析できるため、内部監査やコンプライアンス対応にも役立ちます。他システムとの連携時も、Azure ADによる認証・権限管理を通じて利用者ごとにアクセス制御をかけるなど、エンタープライズ向けのセキュリティ設計が可能です。
拡張性・統合柔軟性 🔄
Azureクラウド上の構築ということでスケーラビリティは高く、需要に応じてインフラリソースをスケールアウトできます。ピーク時にはGPUを備えたVMや推論専用リソースを増強し、閑散時には縮退させることでコストと性能を調整できます。今後のシステム統合の柔軟性という点でも、Azureベースであれば他の社内Azureサービス(例えばデータレイクやAnalytics基盤)との連携がスムーズです。チャットボットで得られたQ&Aログを分析して社内のナレッジギャップを特定しPower BIで可視化するといった発展も考えられますし、将来的に社内のあらゆる問い合わせを集約するポータルとの統合も容易です。Azure上に構築したシステムは自社資産としてカスタマイズ自由度が高く、APIを公開すれば別の社内ツールからこのチャットボット機能を呼び出すことも可能です。例えば社内のRPAやワークフローからナレッジ検索を自動実行するといった高度な統合も、自社構築ならではの柔軟性で実現できます。
AWS・GCP他クラウドでの構築
コスト 💰
基本的な考え方はAzure構築の場合と似ており、クラウドサービス利用料の従量課金+開発運用コストという形になります。AWSやGCPにも大規模言語モデルのAPIサービスや検索サービスがありますが、利用料金はモデルによって様々です(たとえばAWS BedrockでAnthropic Claude等を使う場合の料金体系など)。またAWSにはAmazon Kendra(エンタープライズ検索サービス)などもありますが、これは利用ボリュームに応じた月額費用がかかります。全体的に、クラウドサービスを複数組み合わせることで費用構成が複雑になる傾向があります。初期構築のためのエンジニアリングコストもAzure同様に必要です。特にAzureで既にPoCを行っている場合、AWS/GCPで一から構築し直すと追加費用が発生する点も考慮する必要があります。
提供機能・品質 ⚙️
AWSやGCP上でもRAG型チャットボットは構築可能ですが、利用できる技術スタックがAzureとは異なります。たとえばAWSの場合、OpenAI系モデルは直接は提供されていないため、選択肢としては①オープンソースLLM(Llama2等)をAWS上でホストする、②Amazon提供のLLM(例:AWSが提供予定のTitanや、Bedrock経由で使える他社モデル)を利用する、③OpenAIのAPIをAWS上から呼び出す(この場合データはOpenAI社に渡る点に注意)といった方法があります。いずれにしても、日本語での高精度な応答という意味では現状GPT-4やClaudeなどがリードしているため、AWS上で同等の品質を得るには工夫が必要です。検索に関してAWSは前述のKendraやElasticsearch(OpenSearch)サービスがあり、GCPもElasticsearch相当や独自のEnterprise Search機能を持ちます。GCPの場合はGoogleの大規模言語モデル(PaLM 2など)をVertex AI経由で利用できます。これも多言語対応していますが、日本語の社内文書を扱う精度や、モデルのチューニング容易性でGPT-4と異なる特性があります。UIやシステム挙動は自社で自由に開発可能で、これはAzure構築時と同様です。ただし各クラウドのサービス仕様に合わせた実装が必要で、例えばGCPの認証機構やAWSの権限管理(IAM)を考慮した設計を行う必要があります。ログ取得もクラウド上に構築する限り自前で可能ですが、利用するモデルによってはログデータの一部が外部に保管される可能性がある点(例:外部APIを使う場合のログ)には注意が必要です。
セキュリティ 🔒
基本的にAzureの場合と同じく、自社クラウド環境内でシステムを構築すればデータは自社管理下に置けます。ただ、AWSやGCPでどのモデルを使うかによってデータの扱われ方が変わります。仮にオープンソースモデルを自前ホストすれば、社外にデータが出る心配はありませんが、オープンAI社のAPIをそのまま利用する場合は社内情報がOpenAI社(米国)のサーバーに送信されます。Claudeなど他社モデルを使う場合も同様です。したがって、AWS/GCPで構築する際は「クラウド上ではあるが一部SaaS利用が混在するハイブリッド型」になりやすく、その部分のデータガバナンスに注意が必要です。一方、AWSやGCP自体はAzure同様に企業向けセキュリティ・コンプライアンス機能は整っており、各種認証や暗号化、ネットワーク分離も設定可能です。自社で鍵管理(KMS)を使って機密データを保護し、アクセス制御を厳密に行えば、基本的な安全性は担保できます。ただしAzure OpenAIのような「LLM利用部分まで含めたエンドツーエンドのデータ機密保持」が標準で提供されているわけではないため、利用するモデル/APIごとに利用規約を確認し、機密データが外部に蓄積されないよう配慮する必要があります。
拡張性・統合柔軟性 🔄
クラウド基盤である以上、スケーラビリティは高く必要に応じリソースを増減できます。ただし前述のように外部APIを組み合わせる場合、そのサービス側の制限(例えばAPI呼び出しのレート制限など)がボトルネックとなる場合があります。他システムとの連携については、AWSもMicrosoft 365との直接的な親和性は低いため(Azure ADとの統合などは自前で実装が必要)、もし社内がMicrosoft製品中心の場合は若干手間がかかります。逆に社内がGoogle Workspace中心であればGCP上で構築するほうが、Google DriveやCloud Searchとの統合に利点があります。このように、自社の既存システム環境との親和性を考えてクラウド選定をすることが重要です。将来的な機能拡張の自由度そのものはAzureと同様に高いものの、コミュニティやエコシステムの充実度ではAzure(Microsoft系)は業務アプリとの連携ノウハウが多く蓄積されている強みがあります。他クラウドでも技術的には実現できますが、実装コストや情報量に違いが出る点も考慮すべきでしょう。
オンプレミス構築
コスト 💰
オンプレミスでLLM+ベクトルデータベース環境を構築する場合、初期投資コストが最も高額になります。高性能なGPUサーバーやストレージ設備を自社で購入またはリースする必要があり、数百万円規模の設備費用が発生し得ます。また物理サーバーの設置・電源・冷却といったインフラ費用も考慮が必要です。一方、ランニングコストは主に電力や保守人件費となり、クラウドのような従量課金はありません。利用が増えても追加の従量料金は発生しないため、長期的かつ大規模利用ではトータルコストを抑えられる可能性があります。ただしこれは常に最大活用した場合の話で、使用率が低いと設備投資が無駄になるため、費用対効果を見極めることが重要です。またソフトウェアはオープンソースを用いればライセンス費用は抑えられますが、エンタープライズサポートが必要なら商用サポート契約費が別途かかります。
提供機能・品質 ⚙️
オンプレミスの場合、使用できるLLMは主にオープンソースまたは自社契約可能なモデルになります。現状もっとも精度が高いGPT-4などはオンプレミス実行できないため、Llama 2やBloomといったオープンモデルを自社でチューニングして使うケースが多いでしょう。日本語の細かなニュアンス理解や高度な推論では、これらオープンモデルは最新商用モデルに一歩譲る部分もありますが、学習データの工夫や追加訓練である程度カバーできます。また機密データをモデルに学習させる社内ファインチューニングもオンプレであれば自由に行えます。検索品質についても、ElasticSearchやMilvus等のベクトルデータベースを自前で構築し、チューニングすることで高い精度を目指せますが、設定や最適化には専門知識が必要です。UIやアプリケーション部分は完全に自前開発となり、Webアプリケーション開発スキルが求められます。既存の社内ポータルに組み込む場合でも、APIや認証基盤を含めた統合開発が必要です。ログ監査や分析機能も全て自作になりますが、その分取得したいデータは制限なく取得可能です。例えば「どの部署のユーザーがどのような問い合わせをしたか」「どの文書が頻繁に参照されているか」など細かな分析も、設計次第で実現できます。
セキュリティ 🔒
オンプレミス構築の最大の強みは、機密データを完全に社内環境から出さずに済む点です。社外クラウドを使わないため、情報漏えいやプライバシー侵害のリスクは最小限になります。特に機密性が最重要の業種(官公庁、金融、医療など)ではオンプレミス以外許容されないケースもあり得ます。ただし、オンプレ環境を安全に運用する責任は全て自社にあります。物理サーバーの置かれたサーバールームの入退室管理、ネットワークの防御策、OSやミドルウェアのセキュリティパッチ適用など、クラウド利用時にはベンダーに任せられた領域も自社対応が必要です。逆に言えば、自社ポリシーに沿って隅々までセキュリティを施せるため、要件さえ明確にしておけば理想的な堅牢性を実現できます。また、ユーザーの利用ログや問い合わせ内容が第三者に閲覧される心配もありません(クラウドSaaSでは運営側によるレビューの可能性がゼロではありませんが、オンプレなら完全に自社管理下です)。コンプライアンス上、データを国内設置サーバーから出せないといった要件にもオンプレは確実に対応できます。
拡張性・統合柔軟性 🔄
オンプレミス環境では、サーバー増設などハードウェア対応がない限りリソースに上限があります。利用が想定以上に拡大した場合、追加ハード調達に時間がかかったり、一時的に応答が遅延する可能性があります。一方で、ソフトウェア的なカスタマイズや他システムとの高度な連携はもっとも自由度が高いと言えます。社内のレガシーシステムと直接ファイル連携したり、独自のビジネスロジックをチャットボットに組み込むなど、オープンソースを改変して目的に合うよう作り込むことも可能です。将来的なシステム統合についても制約はありませんが、その実現には自社内に高度な技術力を持つ人材が必要です。ベンダーに頼らず内製で発展させていける体制があるか否かが、オンプレ活用の鍵となります。
以上を踏まえ、各導入形態の特徴を要約すると以下のとおりです。
| 導入形態 | コスト | 機能・検索品質 | セキュリティ | 拡張性・統合 |
|---|---|---|---|---|
| SaaS型 | 初期費用が低く、月額課金制。利用規模拡大時は費用増大。 | ベンダー提供の基本機能を即利用可能。高精度モデル採用サービスなら品質○。多言語対応はサービス依存。 | データをベンダークラウドに預ける(機密性は契約と運用に依存)。標準的なセキュリティ対策あり。 | スケーラビリティ高(ベンダー側で自動拡張)。カスタマイズ性は低め。他システム連携は提供API範囲内。 |
| Azure構築 | 初期構築に開発コスト。利用料は従量課金で調整可能。全社展開でも効率的。 | GPT-4等高度なモデルで高品質回答。Azure検索で精度・多言語◎。UIや機能を自由設計可。ログ詳細取得◎。 | データは自社Azure環境内に留まる。入力・出力も他社と隔離。規制準拠や監査機能も充実。 | スケーラビリティ非常に高い。Azureサービスや社内ADと円滑に統合可能。自社業務に合わせた柔軟な拡張が可能。 |
| 他クラウド | 従量課金+開発コスト(Azureと同等)。既存PoC資産の流用難はコスト増要因。 | モデルやサービス選定次第。GPT-4直接利用不可など制約あり。日本語対応は工夫次第。UI/機能は自由設計。 | 自社クラウド内に構築すれば基本安全。外部LLM利用部分のデータ扱いに要注意。 | スケーラビリティ高いが外部API依存部分に制限も。既存システム環境との親和性を考慮(MS製品との統合は工夫要など)。 |
| オンプレミス | 初期投資大(ハード購入)。ランニングは自社保守中心で長期的には割安の可能性。 | モデル性能は内部実装に依存(精度向上には専門知識要)。完全カスタムUI・機能。 | データが社外に出ない最高度の機密性。自社で物理・ネットワーク含め全対策が必要。 | ハード増設しない限り容量に制限あり。カスタマイズ自由度最高、あらゆる社内システムと統合可能(要技術力)。 |
チャットボット以外のUI形態の検討 🧐
RAGを用いた社内ナレッジ検索では、必ずしもチャットボット形式(対話型UI)だけが唯一の解ではありません。エンタープライズサーチ(社内検索システム) のように、キーワード検索や絞り込み条件で文書を探す従来型のUIが適しているケースも存在します。
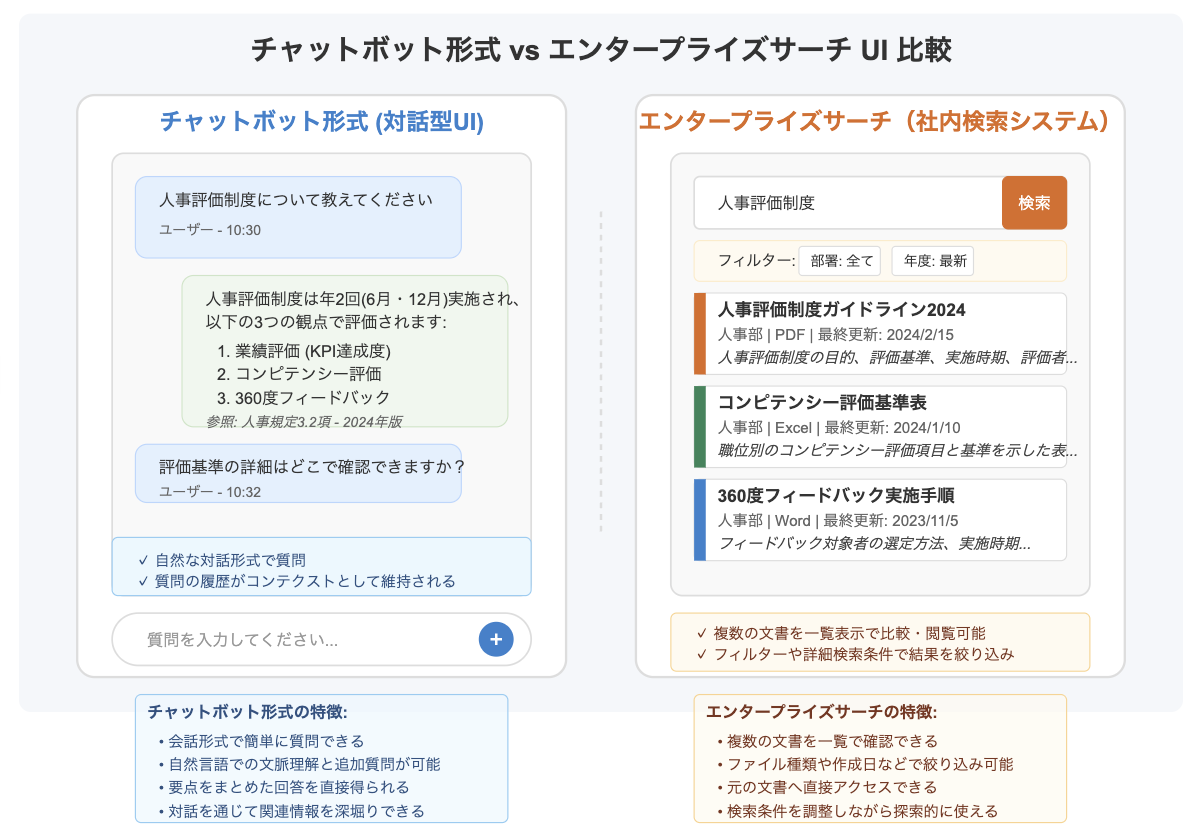
チャットボット形式のメリットは、自然な文章で質問できる直観的な操作性と対話を通じた追加質問への柔軟な応答です。ユーザは検索キーワードを工夫する必要がなく、「○○について教えて」など問いかけるだけで関連する情報を引き出せます。特にヘルプデスク的な用途(例:「◯◯の手順を教えて」→回答→「それに必要な書類は?」→回答…のような逐次対話)や、迅速な問題解決が求められるシーンではチャットボット形式が威力を発揮します。また、回答とともに参照元ドキュメントへのリンクや原文を提示する機能を組み合わせれば、回答の信頼性をユーザ自身が確認できる利点もあります。
一方で、エンタープライズサーチ型のUIは一覧性や能動的な情報探索に優れるという利点があります。検索結果が関連度順のリストやカテゴリー別に表示され、ユーザは自分で複数の結果を比較検討しながら必要な情報に辿り着けます。法務文書や技術資料、研究開発文献など、元のドキュメントそのものを精査・引用することが求められるケースでは、まず関連資料のリストアップとその中身プレビューが重要になります。チャットボットが一つの回答を提示するだけでは不十分で、ユーザ自身が複数の情報源を当たりたい場面では、検索UI+生成AI要約の組み合わせが有効です。
近年はエンタープライズサーチ製品にも生成AIによる要約やQ&A機能がオプション搭載されつつあり、「検索システムにRAG的な回答生成機能を付加する」アプローチも登場しています。このようなハイブリッド型では、基本は検索UIで必要に応じて生成AIが回答を補助するため、使い慣れた検索インターフェースのまま生成AIの利便性を享受できます。
以上より、利用シーンに応じてUI形態を選定することが重要です。例えば、「社内マニュアルや規程類の改定履歴を調べたい」「特定プロジェクトの関連資料を網羅的に集めたい」といった場合は検索画面で絞り込みながら探す方が効率的です。一方で「特定の疑問に対して部署横断で回答を得たい」「手順を対話形式でナビゲートしてほしい」といった場合はチャットボットが適します。実際の導入では、チャットボットと検索UIを併設しユーザーが選べるようにしたり、段階的にUIを切り替えることも検討できます。経営層や非技術者には直観的なチャットボットが親切ですが、エキスパート人材には詳細な検索機能も提供するといった使い分けも有効でしょう。
Azure OpenAIを活用するアプローチのメリット 🌟
前述の比較を踏まえ、本章では特にAzure環境でOpenAIサービスを活用して構築するアプローチの優位性を整理します。Azure採用のメリットは多岐にわたりますが、特にセキュリティ、コスト効率、拡張性、社内システム統合の4点で顕著です。
セキュリティ・信頼性 🔒
Azure OpenAIサービスはエンタープライズ向けの高度なプライバシー保護を特徴としており、ユーザーデータが他者と共有されたり勝手に学習に使われることがありません。Microsoftの厳格な基準の下で運用され、GDPRやHIPAAなど各種規制に準拠したデータ管理がなされています。加えて、Azure上にシステムを構築することで、自社の仮想ネットワーク内に閉じたアーキテクチャを実現できます。例えばベクトルデータベースやストレージを社内VNet内に配置し、OpenAI呼び出しもプライベートエンドポイント経由とすることで、通信経路まで含めたエンドツーエンドのセキュリティ確保が可能です。信頼性の観点でも、MicrosoftのSLAに支えられた安定稼働が期待でき、クリティカルな社内業務で安心して生成AIを活用できます。
コスト効率とスモールスタート 💰
Azure利用は一見すると自社開発が必要な分コスト高に思えますが、実際には使った分だけ課金というモデルのため無駄がありません。特にPoC段階から本番展開への移行に際し、スモールスタートで効果検証を行いながら段階的に利用範囲を広げる戦略を取りやすいのも利点です。Azure OpenAIの料金はOpenAI直販のAPIと同程度であり、ベンダー独自SaaSのようなマージンが上乗せされた価格設定ではないため、性能あたりの費用対効果が高いです。また既存のAzure契約(例えばマイクロソフトのエンタープライズ契約)があれば、社内の他部門で余ったAzureリソース枠を本システムに活用するような柔軟な予算運用も可能です。総じて、Azureベースの構築は初期こそ投資が必要ですが、中長期的には自社運用ゆえのコスト最適化余地が大きい点を強調できます。
拡張性・将来の発展性 🔄
Azure上に構築したRAGチャットボットは、社内IT戦略に沿って自由に拡張・改良していけます。例えば社内で新たなデータソース(データレイクやCRMデータなど)が生まれれば、それをAzure Data Factoryでクロールして検索インデックスに加えることが容易です。将来的に他の生成AI機能(自動要約やレポート生成)と連携させ、包括的な社内AIアシスタントへ発展させることもできます。AzureにはLogic AppsやPower Automateといったツールもあるため、チャットボットを起点にワークフローを自動化することも検討できます。こうした発展性の高さは、自社で基盤を持つからこそ実現できることであり、ブラックボックス化しがちなSaaS利用では得難いメリットです。Azure自体のサービスも進化し続けており、新機能(例えばより高速なベクトル検索やドメイン特化LLMなど)が出れば柔軟に取り入れられる拡張性も備えています。
社内システムとの統合容易性 🔗
Microsoftエコシステムとの親和性が高いAzureを選択することで、既存の社内システム群とシームレスに統合できます。具体的には、Active Directoryとの連携によりユーザー認証やアクセス制御を一本化できるため、チャットボット利用権限を社員の役職や部署に応じて制限するといったポリシー実装も容易です。また、社内の情報共有基盤であるSharePointやTeamsと直結させることもスムーズです。TeamsにAzure Bot Service経由でチャットボットを組み込めば、社員は普段使い慣れたTeams上でナレッジ検索ができますし、SharePoint上の資料を問い合わせに応じて引っ張ってくることも可能になります。さらに、Azure上で蓄積したQ&Aログやメタデータを他のデータ分析基盤と統合することで、社内のナレッジフロー全体を可視化・最適化するといった高度な活用も視野に入ります。例えば、どの部署でどんな質問が多いかを分析し、人材育成やFAQ整備に活かすといった展開です。Azure採用により、このような全社的データフローの実現に繋げやすい点は、大きな付加価値と言えます。
以上の理由から、Azure OpenAIサービスを活用した社内ナレッジ検索チャットボットの構築は、単なるシステム導入に留まらず企業の情報資産活用インフラを強化する戦略的選択肢となります。セキュリティ担保の下で先進技術を取り入れ、必要に応じて柔軟に拡張できるため、経営層にとっても長期的な視点で安心できるアプローチです。
おわりに 📝
社内ナレッジ検索チャットボットの導入形態について、SaaS、クラウド構築、オンプレミスそれぞれの特徴を比較し、加えて利用シーンに応じたUI形態の検討ポイントを述べました。その上で、Azure OpenAIサービスを活用したアプローチが、セキュリティの確保と高性能の両立、コスト管理のしやすさ、将来にわたる柔軟な拡張性といった面で優れており、単なる問い合わせ対応ツールに留まらない全社的なデータ活用プラットフォームへと発展し得る可能性を示しました。
経営層や非技術部門にとっても、本提案は「自社の知的資産を守りつつ活用する戦略的投資」であることを強調できます。適切な要件定義とベンダー選定の工夫によって、社内に安心して浸透するナレッジ検索基盤を構築できるでしょう。今回比較した各方式のメリット・デメリットを踏まえ、自社に最適な形でプロジェクトを推進されることを期待します。
参考文献・出典 📚
本レポートの内容は、各種クラウドサービスの公開情報や専門記事に基づいています。具体的な数値や事例については、Microsoft社および他クラウドベンダーの公式ドキュメントや国内企業でのRAG導入事例記事等を参照しています。各導入形態の比較表やメリット・留意点は執筆時点(2025年)での一般的な傾向をまとめたものであり、自社の状況に応じてカスタマイズする際の指針としてご活用ください。
https://www.nttpc.co.jp/gpu/article/knowledge07_gpu-rag.html#:~:text=