はじめに
今回やりたいこと
前回の記事の続きとして、scrapyというクローラーフレームワークを使って、Jリーグのデータサイトの選手情報をクローリングして取得したいと思います。
結果
こんな感じで一覧表になりました。
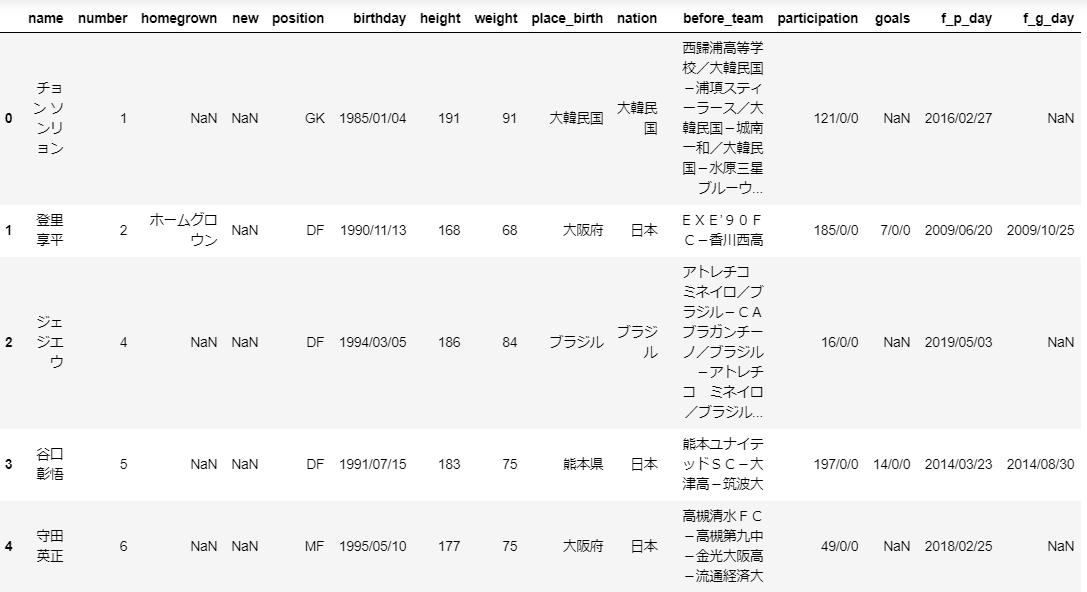
※Jupyter-notebookでCSVファイルを読み込んで、DataFrameで表示しています。
コードと解説
前提
- 開発環境
- Anaconda
- Python3
流れ
1.Jリーグのデータサイトのをチェック
2.scrapyのプロジェクト作成
3.settingとItemを修正
4.複数サイトをクローリング設定
5.Jリーグのサイトを見ながら選手情報をスクレイピング
6. CSVファイルとして出力
7. CSVファイルをJupyter-notebookでチェック
コード
まず、scrapyをインストール。
次に、$ scrapy stratproject <プロジェクト名>でプロジェクトを作成。
これで、プロジェクトが作成され、必要なファイルができます。
そして、settings.pyを修正。以下の部分のコメントアウトを外します。
DOWNLOAD_DELAY = 3
クローリング感覚を調整する設定です。スクレイピング相手先に負担をかけすぎないように気をつけましょう。
さらに、items.pyを修正します。こんな感じに書き換えました。
import scrapy
class Player(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
number = scrapy.Field()
homegrown = scrapy.Field()
new = scrapy.Field()
position = scrapy.Field()
birthday = scrapy.Field()
height = scrapy.Field()
weight = scrapy.Field()
place_birth = scrapy.Field()
nation = scrapy.Field()
before_team = scrapy.Field()
participation = scrapy.Field()
goals = scrapy.Field()
f_p_day = scrapy.Field()
f_g_day = scrapy.Field()
team = scrapy.Filed()
最後に、サイトをチェックしながらスクレイピングする部分を書いていきます。
BeautifulSoupを使っているので、大体の部分は前回の記事と同じです。
まず、$ scrapy genspider <スパイダー名> <クロール対象ドメイン>でスパイダー名のPythonファイルを作成。
import scrapy
import requests
from bs4 import BeautifulSoup
class PlayerSpiderSpider(scrapy.Spider):
name = 'player_spider'
allowed_domains = ['data.j-league.or.jp']
start_urls = [
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=14&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E5%8C%97%E6%B5%B7%E9%81%93%E3%82%B3%E3%83%B3%E3%82%B5%E3%83%89%E3%83%BC%E3%83%AC%E6%9C%AD%E5%B9%8C',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=54&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E3%83%99%E3%82%AC%E3%83%AB%E3%82%BF%E4%BB%99%E5%8F%B0',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=1&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E9%B9%BF%E5%B3%B6%E3%82%A2%E3%83%B3%E3%83%88%E3%83%A9%E3%83%BC%E3%82%BA',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=3&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E6%B5%A6%E5%92%8C%E3%83%AC%E3%83%83%E3%82%BA',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=11&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E6%9F%8F%E3%83%AC%E3%82%A4%E3%82%BD%E3%83%AB',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=22&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%EF%BC%A6%EF%BC%A3%E6%9D%B1%E4%BA%AC',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=21&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E5%B7%9D%E5%B4%8E%E3%83%95%E3%83%AD%E3%83%B3%E3%82%BF%E3%83%BC%E3%83%AC',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=5&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E6%A8%AA%E6%B5%9C%EF%BC%A6%E3%83%BB%E3%83%9E%E3%83%AA%E3%83%8E%E3%82%B9',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=34&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E6%A8%AA%E6%B5%9C%EF%BC%A6%EF%BC%A3',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=12&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E6%B9%98%E5%8D%97%E3%83%99%E3%83%AB%E3%83%9E%E3%83%BC%E3%83%AC',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=7&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E6%B8%85%E6%B0%B4%E3%82%A8%E3%82%B9%E3%83%91%E3%83%AB%E3%82%B9',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=8&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E5%90%8D%E5%8F%A4%E5%B1%8B%E3%82%B0%E3%83%A9%E3%83%B3%E3%83%91%E3%82%B9',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=9&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E3%82%AC%E3%83%B3%E3%83%90%E5%A4%A7%E9%98%AA',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=20&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E3%82%BB%E3%83%AC%E3%83%83%E3%82%BD%E5%A4%A7%E9%98%AA',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=18&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E3%83%B4%E3%82%A3%E3%83%83%E3%82%BB%E3%83%AB%E7%A5%9E%E6%88%B8',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=10&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E3%82%B5%E3%83%B3%E3%83%95%E3%83%AC%E3%83%83%E3%83%81%E3%82%A7%E5%BA%83%E5%B3%B6',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=33&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E3%82%B5%E3%82%AC%E3%83%B3%E9%B3%A5%E6%A0%96',
'https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=31&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E5%A4%A7%E5%88%86%E3%83%88%E3%83%AA%E3%83%8B%E3%83%BC%E3%82%BF',
]
def parse(self, response):
soup = BeautifulSoup(response.text, "lxml")
base = soup.find("div",class_="pd10-box")
print(base)
for div_player in base.find_all('div',class_='box-info register-list'):
team =base.find('h3',class_='st-base-type2').text #チーム名の取得
team = team.replace('2020J1リーグ\xa0','')
p_name_tags =div_player.find('p',class_='name')
p_name_tags_tx = p_name_tags.text
p_name_tags_array = p_name_tags_tx.split('\n') #改行ごとに配列に入れる
# player_number = p_name_tags_array[1].strip()
player_name = p_name_tags_array[2].strip()
player_name = player_name.replace('\u3000', ' ') #名前の名字の間の整える
player_number = p_name_tags_array[1].strip()
if '新加入' in p_name_tags_array[4]: #'ホームグロウン'ありなしで配列の位置がずれるため
player_new = p_name_tags_array[4]
player_homegrown = ''
else:
player_homegrown = p_name_tags_array[4]
player_new = p_name_tags_array[5]
#1~10の要素取得
dl_base_tags = div_player.find('dl',class_='dl-base')
dl_base_tags_tx = dl_base_tags.text
dl_base_tags_array = dl_base_tags_tx.split('\n') #改行ごとに配列に入れる
player_position = dl_base_tags_array[2]
player_birthday = dl_base_tags_array[4]
player_h_w = dl_base_tags_array[6].split('/') #身長と体重を分割
player_height = player_h_w[0]
player_weight = player_h_w[1]
player_place_birth = dl_base_tags_array[8]
#以降、要素が抜けている場合があるのでtry文で条件分け
try:
i = dl_base_tags_array.index('5')
except:
player_nation = '日本'
else:
player_nation = dl_base_tags_array[i+1]
try:
i = dl_base_tags_array.index('6')
except:
player_before_team = ''
else:
player_before_team = dl_base_tags_array[i+1]
try:
i = dl_base_tags_array.index('7')
except:
player_participation = ''
else:
player_participation = dl_base_tags_array[i+1]
try:
i = dl_base_tags_array.index('8')
except:
player_goals = ''
else:
player_goals = dl_base_tags_array[i+1]
try:
i = dl_base_tags_array.index('9')
except:
player_f_p_day = ''
else:
player_f_p_day = dl_base_tags_array[i+1]
player_f_p_day = player_f_p_day.replace('\xa0\r','') #整形
try:
i = dl_base_tags_array.index('10')
except:
player_f_g_day = ''
else:
player_f_g_day = dl_base_tags_array[i+1]
player_f_g_day = player_f_g_day.replace('\xa0\r','') #整形
yield {
"name": player_name,
"number": player_number,
"homegrown": player_homegrown,
"new": player_new,
"position" : player_position,
"birthday": player_birthday,
"height": player_height,
"weight": player_weight,
"place_birth": player_place_birth,
"nation": player_nation,
"before_team": player_before_team,
"participation": player_participation,
"goals": player_goals,
"f_p_day": player_f_p_day,
"f_g_day": player_f_g_day,
"team": team,
}
最後に、これを実際に動かしてCSVファイルとして出力させます。
$ scrapy crawl player_spider -o j_allplayer2020.csvで出力できます。
これをJupyter-notebookにアップロードして、見てみます。
※Jupyter-notebookの最初の画面で、Uploadのボタンでアップロードで来ます。
そして以下のコードで最初のように出力されます。
import pandas as pd
# csvの読み取り
df= pd.read_csv("j_kawasaki2020.csv")
df.head()
完成!
感想・反省
・フレームワークを使うと複数サイトのクローリングも簡単にできて便利ですね。
・start_urlsで複数サイトを書くところも自動化出来たらよかったですね。どうするんだろう…