この記事って何?
本質的に良い分析ができても、最終的な図がわかりにくい/汚いと伝わらない
筆者は受託分析・AIシステム開発を行っているデータサイエンティストです。
コンサルタント的な面もあり、顧客と話す機会が多い立場です。
さて、我々データサイエンティストが
- どのような素晴らしい分析をしたり
- グレートなAIシステムを創ったり
- 顧客の長年の悩みへの解決策を見つけたりしても
社内の意思決定者や顧客にうまく伝えられないことには最終的な顧客価値に繋がりません。
社内外の関係者への各種説明のためには、ダッシュボードでもスライドでも、何らかの図版は欠かせません。
このとき、本質的な部分でなかったとしても、図が相手の視点でわかりにくい・単純に汚いと、うまく伝わらなかったり、相手が理解を諦めてしまったりします。
クソどうでも良い体裁の指摘でデータサイエンティストは簡単に死ぬ
しかし、データサイエンティストやエンジニアの目線に立つと
「技術的な本質部分はもう解決したのに、非本質的な体裁に何度も突っ込まれる」
のは大きいストレスになりがちです。
目的 : 図の体裁はこれだけ気をつければ8割方OK!という内容を明文化したい
レビューで体裁の指摘をされるのがストレスになるので、「最初から気をつけるべき観点が明文化できていて、それだけ気をつけていればOK」という状態を目指したいと思っています。
もちろん全ての指摘をなくすのは難しいですが、8割が明文化できていればかなり体裁の指摘が減らせて、本質的なところに集中できる時間が増えるはず!
(補足) matplotlib / seabornの準備
- 特に弊社データサイエンティストはPythonを多用するのでmatplotlib, seabornのサンプルを込みで記述します
- 以下を実行済みの状況を仮定
- サンプルデータはみんな大好きiris と COVID-19新規感染者数データを利用します
from matplotlib import pyplot as plt
import seaborn as sns
import pandas as pd
import datetime
# irisデータセット
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = iris.target_names[iris.target]
# COVID-19 データセット
covid_df = pd.read_csv("https://covid19.mhlw.go.jp/public/opendata/newly_confirmed_cases_daily.csv")
covid_df.Date = pd.to_datetime(covid_df.Date)
s_dt = datetime.date(2021, 12, 1)
e_dt = datetime.date(2022, 1, 31)
covid_df = covid_df.query("Date >= @s_dt and Date <= @e_dt") # 2021/12〜2022/1に限定
ほぼ必須の内容
とりあえず sns.set()
-
sns.set()を実行するだけで図の配色やら何やらがそれっぽくなるので、脳死実行を推奨します
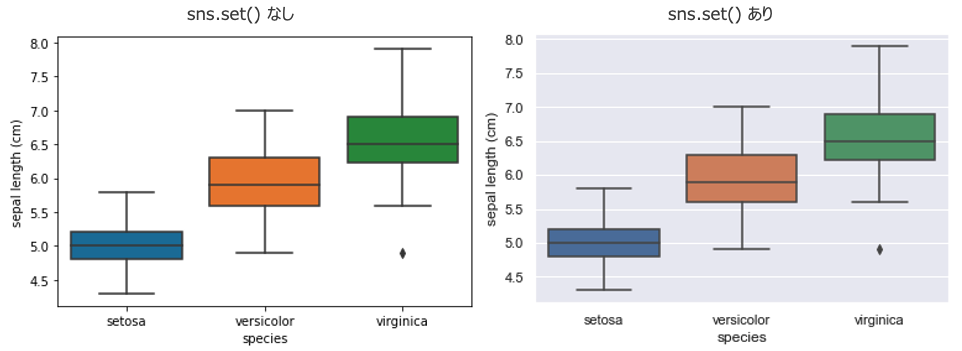
sns.set() # <-- (1回実行すればOK)
fig, ax = plt.subplots(figsize=(6, 4))
sns.boxplot(data=df, x="species", y="sepal length (cm)")
plt.savefig("snsset_true.png", bbox_inches="tight")
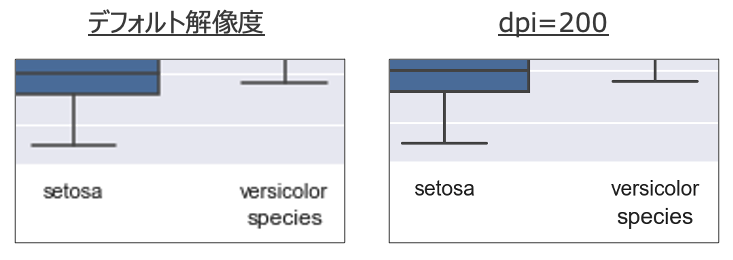
解像度を上げる
- matplotlibのデフォルトでは解像度は低く、特に字が粗く読みにくくなります
- 例えばデフォルトと
dpi=200で拡大して比較すると以下の感じで、文字の粗さが違う - 論文投稿などでは
dpi=300が推奨ですが、実用上はdpi=150くらいあれば十分だと思います
fig, ax = plt.subplots(figsize=(6, 4))
sns.boxplot(data=df, x="species", y="sepal length (cm)")
plt.savefig("dpi_200.png", dpi=200, bbox_inches="tight") # <-- dpi設定
Title, 軸ラベル, 凡例をつける
- 当たり前ではあるのですが、忘れることが多々あります
- 特に**「レポート上の文章で図の説明」をしている場合に忘れがちですが「図単体で意味がわかる」ようにする**ことが大切です
- 基本的に人間は文章を読みません
fig, ax = plt.subplots(figsize=(6, 4))
sns.boxplot(data=df, x="species", y="sepal length (cm)")
plt.title("Sepal length comparison among species") # <-- Title指定
plt.savefig("with_title.png", dpi=200, bbox_inches="tight")
コード内の変数名/列名ではなく顧客が利用する業務名でラベルをつける
- データサイエンティストはコード内の変数名/列名でラベルなどをつけがちです
- しかし、顧客や経営層からすればそれでは伝わらないので「顧客がわかる業務名」でラベルをつけましょう
- 顧客が日本語話者であれば、可能なものは日本語にしたほうが良いです
- (補足)matplotlibで日本語を使うには
japanize_matplotlibが便利です - 例えば先ほどまでのアヤメの花のデータを日本語でわかりやすくすると以下

import japanize_matplotlib # <-- これで日本語が使えるようになる。1回実行すればOK
fig, ax = plt.subplots(figsize=(6, 4))
sns.boxplot(data=df, x="species", y="sepal length (cm)")
plt.title("アヤメ 品種ごとのがく片の長さの比較") # <-- 日本語説明
plt.ylabel("がく片の長さ(cm)") # <-- 日本語説明
plt.xlabel("品種") # <-- 日本語説明
# 凡例が必要な場合は plt.legend(title="ほげ") など
plt.savefig("with_japanese_labels_boxplot.png", dpi=200, bbox_inches="tight")
場合によって重要な内容
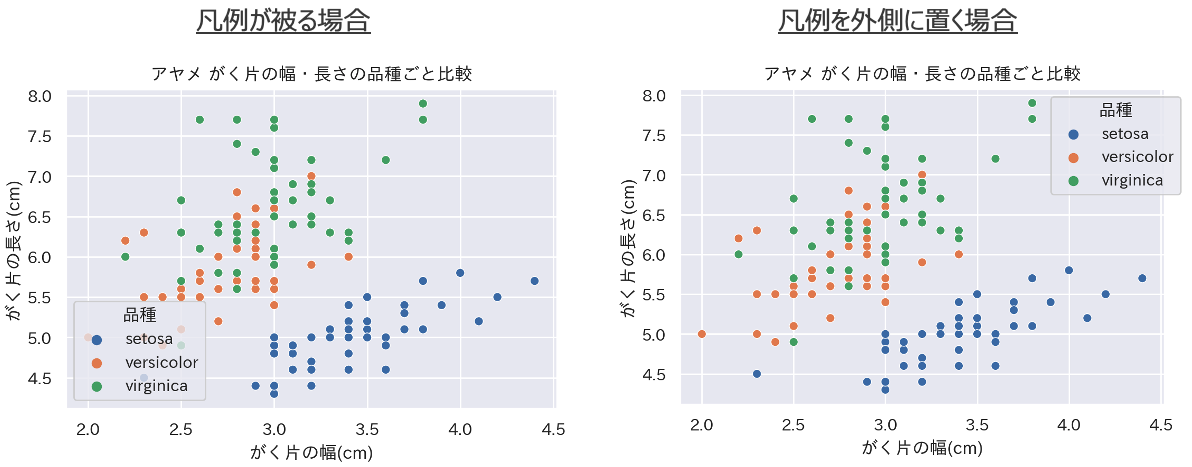
重要な部分に凡例を重ねない
- 凡例が図の内容に重なる場合があります(非重要な部分であれば問題ない)
- 凡例を図の外側に持ってくることもできます
-
bbox_to_anchorなどを利用
-
fig, ax = plt.subplots(figsize=(6, 4))
sns.scatterplot(data=df, x="sepal width (cm)", y="sepal length (cm)", hue="species")
plt.title("アヤメ がく片の幅・長さの品種ごと比較")
plt.ylabel("がく片の長さ(cm)")
plt.xlabel("がく片の幅(cm)")
plt.legend(title="品種", bbox_to_anchor=(1.05, 1)) # <-- ココ
plt.savefig("with_japanese_labels_scatter_legend.png", dpi=200, bbox_inches="tight")
画像サイズは使用イメージを考えて設定
- 例えばこの記事で以下のように縦長なグラフを貼ると無駄に幅を取って読みにくくなります
- この場合は横長の方がスッキリします
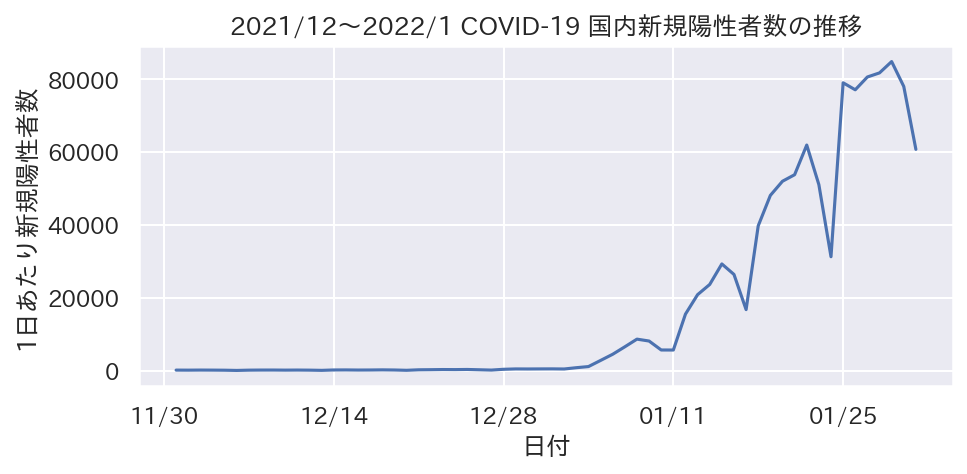
fig, ax = plt.subplots(figsize=(7, 3))
plt.plot(covid_df.Date, covid_df.ALL)
plt.title("2021/12〜2022/1 COVID-19 国内新規陽性者数の推移")
plt.xlabel("日付")
plt.ylabel("1日あたり新規陽性者数")
# x軸の日付目盛りの整形のための設定
import matplotlib.dates as mdates
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter("%m/%d"))
plt.gca().xaxis.set_major_locator(mdates.DayLocator(interval=14))
plt.savefig("covid_positive_wide.png", dpi=150, bbox_inches="tight")
軸範囲を調整する
0を軸範囲に入れるかどうか
- 例えば以下の図はy軸範囲に0を含んでおらず感染者数の変化に誤った印象を与える可能性があります
- 1/15(29279人) → 1/22(61922人) で、実数値は倍増
- この軸設定だと0を含まないので、ぱっと見3倍程度の増加の印象も与えうる
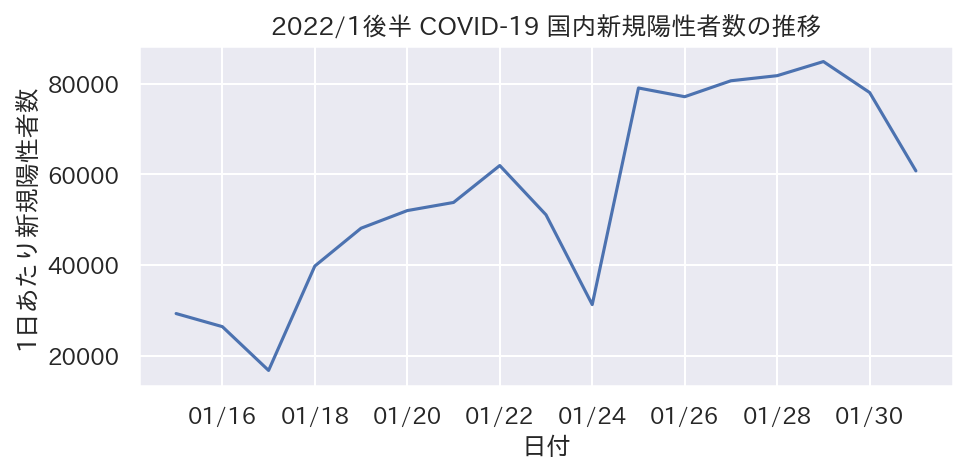
- 場合によって(0が意味を持つ場合など)0を軸範囲に含むように調整した方が良い可能性があります
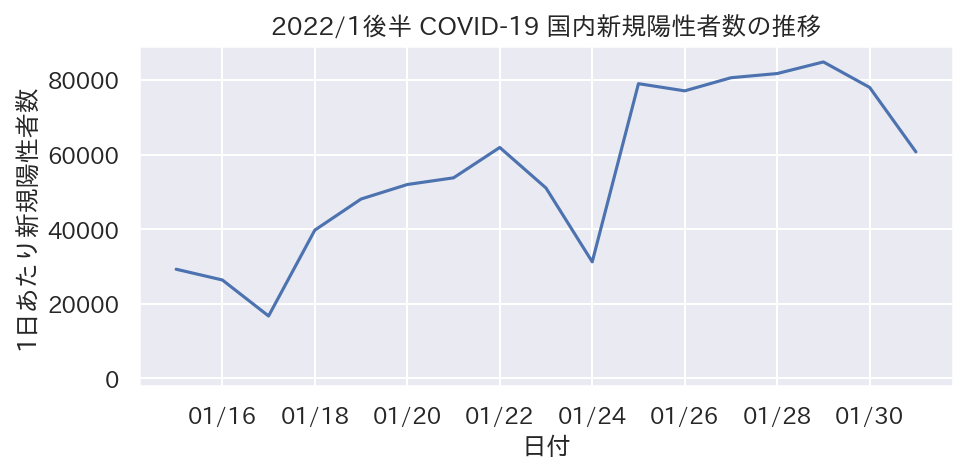
tmp_dt = datetime.date(2022, 1, 15) # 1月後半に限定
fig, ax = plt.subplots(figsize=(7, 3))
plt.plot(covid_df.query("Date >= @tmp_dt").Date, covid_df.query("Date >= @tmp_dt").ALL)
plt.title("2022/1後半 COVID-19 国内新規陽性者数の推移")
plt.xlabel("日付")
plt.ylabel("1日あたり新規陽性者数")
plt.ylim(-2000, covid_df.ALL.max() * 1.05) # <-- 軸範囲調整
# x軸の日付目盛りの整形のための設定
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter("%m/%d"))
plt.gca().xaxis.set_major_locator(mdates.DayLocator(interval=2))
plt.savefig("covid_positive_zero.png", dpi=150, bbox_inches="tight")
異常値によって図が潰れないように軸範囲を設定する
- 実データではさまざまな異常値が存在します
- 例 : ある商品の売上がある1日にいきなりスパイクする場合など
- 軸範囲を正しく調整しないと異常値により図が潰れて、他の部分の変化が読み取りにくくなります
- 例(意図的にデータに異常値を入れた場合)
- 1日分の異常値により、それ以外の日の変化が潰れて読み取りにくい

- 改善例 : 異常値を含めずにプロット
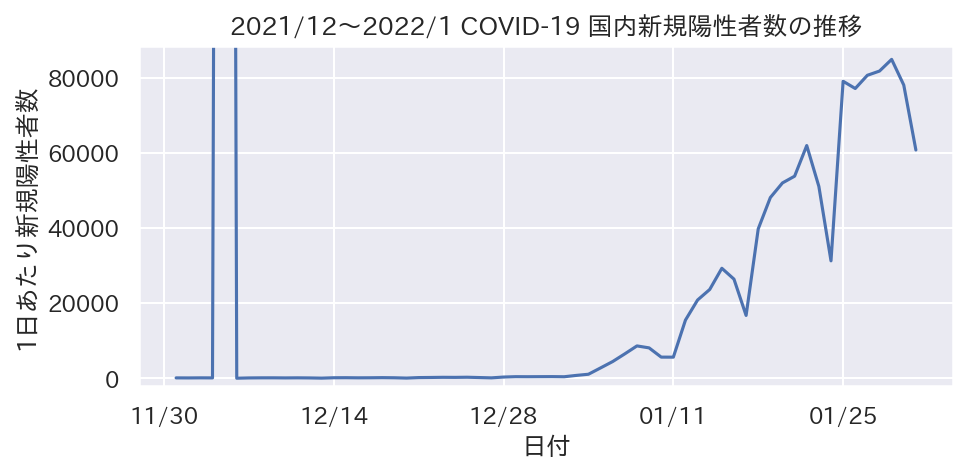
covid_df.loc[689, "ALL"] = 1000000 # 異常値を意図的に入れる
fig, ax = plt.subplots(figsize=(6, 3))
plt.plot(covid_df.Date, covid_df.ALL)
plt.title("2021/12〜2022/1 COVID-19 国内新規陽性者数の推移")
plt.xlabel("日付")
plt.ylabel("1日あたり新規陽性者数")
plt.ylim(-2000, covid_df.ALL.quantile(0.98)*1.05) # 異常値を軸範囲から除く(98パーセンタイルを基準に設定する)
# x軸の日付目盛りの整形のための設定
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter("%m/%d"))
plt.gca().xaxis.set_major_locator(mdates.DayLocator(interval=14))
plt.savefig("covid_positive_annomaly.png", dpi=150, bbox_inches="tight")
(補足) 体裁以前の図の組み立て方について
- 以下のような「そもそもの図の組み立て方」については本記事の対象外です
- そもそもどのような図を選ぶべきなのか(scatter, barplot, boxplot, heatmap, ...)
- 何と何を比較するべきか
- これらはイシューからはじめよ──知的生産の「シンプルな本質」とかを読むのが良いかなあと思います