背景
目標は画像認識を使った何かしらのシステムを構築することであるが、画像認識の分野では知識が少なすぎる。よってKaggleを通して、画像認識のモデルを構築する方法を学ぶ。 ただあまりにも知識量が少なすぎる。したがって、画像認識に関する調査を続行し、問題へのアプローチの手段を獲得する。
画像認識の分類
画像認識にはどのような分類があるのか、改めて復習する。参考
- 特定物体認識
- データベースには認識対象とする物体の画像をすでに持つことを前提として、入力画像に写る物体とデータベース内の画像を照合すること
- 一般物体認識
- データベースに存在しない入力画像の物体のカテゴリを予測すること
- 画像アノテーション
- 複数ラベルが付与された画像データセットから,入力画像に複数のラベルを付与すること。
→作ろうとしているシステムは特定物体認識の分野。共通するところを何とか学び取りたい。
FGVCとは?
Fine-Grained Visual Categorization.日本語では、詳細画像識別。簡単に言えば、似たような画像に対して、非常に局所的な特徴を頼りに、画像を識別する問題のことである。つまり、ある特定の対象領域に対して、高粒度に多クラス分類を行うものである。
一般物体認識からスピンアウトして発展してきている。
下記slideshareでかなり詳しく解説していただいており、とても分かりやすかった。
これからの記述はこのリンクを参考に書かせていただいております。
- 意味的・視覚的に非常に類似したクラスを扱う。
- 一般的な人間をはるかに超えるレベルの詳細な識別能力を目指す。
難しいポイント
一般物体認識に比して、同じ数の多クラス分類でも非常に低い識別精度しか得られない。
→似たような画像がたくさん出てくるが、その中で分類をしなければならない。
研究としてのアプローチ方法
一般的物体認識の技術を応用させて解決を図っている。
- 領域を記述する画像特徴量(コードブック1の拡張、生画像のパッチを生かす、次元圧縮など)
- セグメンテーション(上記のさらに前処理。物体領域のみを切り出すなど)
- 正規化(物体の部位を検出し、位置、姿勢のノイズを減らすなど)
→おそらくコンペではこの中からいくつかの方法を導入していくことになる。
Herbarium 2020 - FGVC7
概要
google翻訳のコピー
Herbarium 2020 FGVC7チャレンジは、ニューヨーク植物園(NYBG)から提供された大規模なロングテールコレクションの植物標本から維管束植物種を特定することです。
Herbarium 2020データセットには、32,000を超える植物種を表す100万を超える画像が含まれています。 これはロングテールのデータセットです。 種ごとに最低3つの標本があります。 ただし、一部の種は100を超える標本で表されます。 このデータセットには、小葉植物、シダ、裸子植物、顕花植物を含む維管束植物のみが含まれています。 小葉植物の絶滅した形態は石炭鉱床の主要な構成要素であり、シダは生態系の健康の指標であり、裸子植物は動物の主要な生息地を提供し、顕花植物は私たちのすべての作物、野菜、果物を提供します。
データの可視化
画像ファイルがとても多いため、trainとtestのmetaデータを確認する。
train
trainフォルダの中のmetadataには以下の項目が入っている。これをdict型で読み込み、メモリに展開する。
dict_keys(['annotations', 'categories', 'images', 'info', 'licenses', 'regions'])
各カテゴリには以下のようなデータが入っている。
annnotations
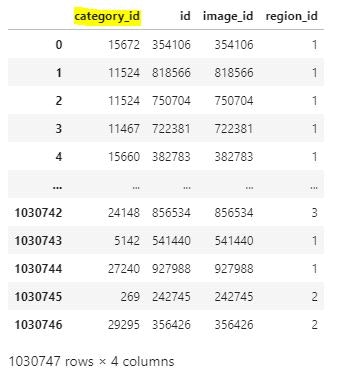
categories
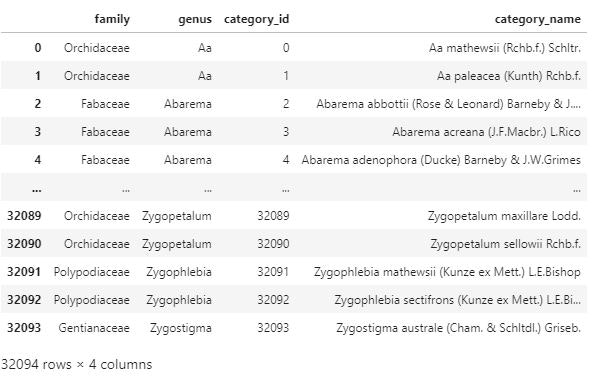
images
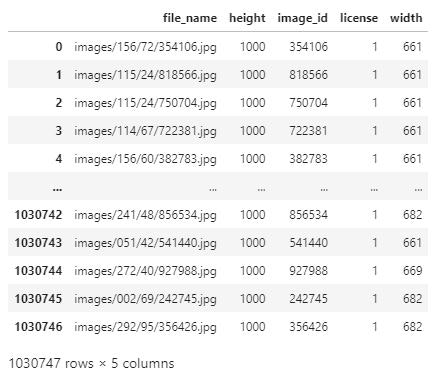
regions

各テーブルをマージし、画像ごとのidとラベルを一つのテーブルにまとめた。
(このときNanを含む行を落としている。)
test
一方testデータは以下からなる。
dict_keys(['images', 'info', 'licenses'])
データの考察
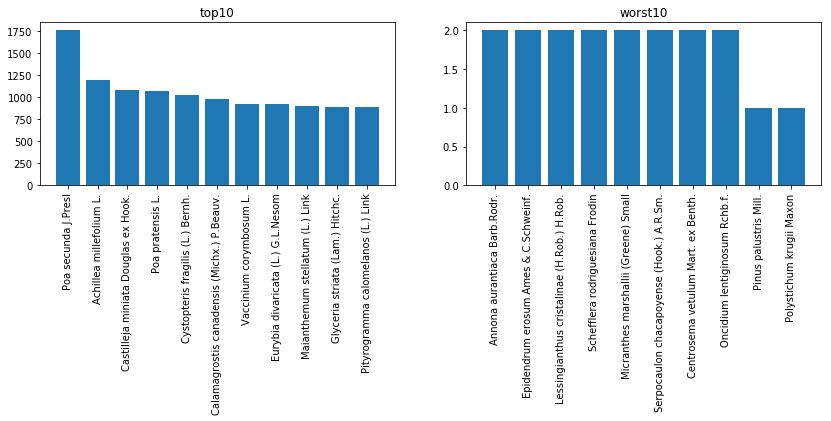
教師データ数について
本コンペティションで問われているのは、各画像データに対して、category_name(category_idと1:1対応)を予測することである。現在予測対象とするカテゴリ数は32093 種類存在する。
まずはカテゴリごとに学習できる画像の数が異なるため、それを可視化する。(画像は教師データ数上位10カテゴリと下位10カテゴリを示したものである。)
このことから、下位カテゴリの中には数枚のみしか画像データがないカテゴリが存在した。これを画像のみから分類することは難しいと考えられる。
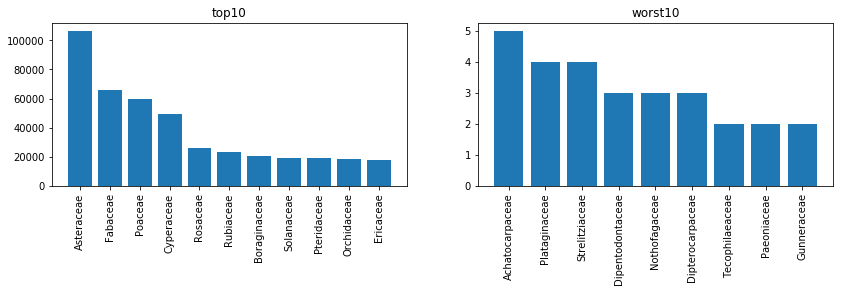
「科」による分類について
教師データにはfamily列が存在する。この列は日本語でいう「科」にあたり、全部で310種類存在する。カテゴリ数よりかなり少なく、こちらを予測するのはやや簡単であると予想される。
これについても上位と下位をグラフ化する。下位のものは2セットと少ないものもある。
「属」による分類について
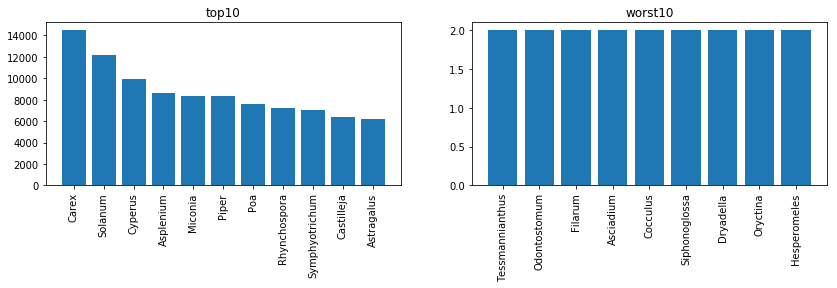
「科」よりも詳細な分類では「属」(genus)がある。全部で、3678種類存在する。これを予測に使う手段もある。
生物学による階級の話
一般に「科」>「属」>「種」の順で分類が大きくなっていく。今回の分類問題は「種」を当てる問題であることに注意する。(参考)
モデル検証
前回参加したコンペで優秀な成績を収めたEfficeintNetを使用して、精度を確かめてみる。
検証するのはB0からとする。→submit完了。testデータのスコアは0.0000。
(参考)Kaggleに臨む心構え
いくつかのコンペに取り組んできてこちらの記事を読んで気を引き締めることができた。ぜひ参考にするべきであると思います。
-
ある画像が何かを表すベクトルのようなもの。Bag of Featureとかがその例 ↩