はじめに
こんにちは!株式会社Relicでフロントエンドエンジニアとして働いてこれから3年目になる@yokajimaです。
本記事では、よくあるCRUD機能のフロントエンドをReactで作るときのコードの役割の捉え方について、私なりの方法を紹介していきます。
この方法により、特にReact触りたてで仕様を作るのもヒヤヒヤだよ〜という方がコードに向き合う余裕を取り戻す一助になればと思っています。
要点
以下に共感できれば、記事に共感できたと判断できると思います。
- この世は大体 インプット → 処理 → アウトプット の3ステップに分割できる
- 3ステップに分ける方法は仕様といったマクロな対象にも、関数といったミクロな対象にも適用できる
- まず仕様を「インプット → 処理 → アウトプット」の3ステップに分け、各ステップの実装の検討も同様の3ステップで分けて考える。分け続けて簡単な関数まで分解できれば実装できたに等しくなる(Type-Driven)
今回考える画面
まずはコンテキストの共有です。
冒頭で、本記事では「CRUD機能のフロントエンド」とスコープを指定しました。それ以外の仕様でも適用可能な基本骨格の捉え方ではありますが、分かりやすいのでこれに焦点を絞ります。
CRUDとは、Create, Read, Update, Deleteの頭文字をとったものでデータの読み書きの分類をまとめたものです。フロントエンドはDBへの読み書きの手段をユーザーに提供するものだったりするので、画面もなんらかの形でCRUDに対応しがち(=あるある実装=骨格)です。
例えば、ユーザー情報に関するCRUDであれば以下のような画面構成が考え得ます
Create: 新規登録フォーム
Read: ユーザー一覧/ユーザー詳細
Update: ユーザー情報編集フォーム
Delete: ユーザー削除/退会画面
こうやって画面構成だけ挙げてしまうと簡単そうですが、実際に初めて作るとなると、APIは叩けて、JSX部分も静的な部分は書けたけど...次は?となったりしがちです。
それは即ち「困難は分割せよ」という、デカルトさんなる有名な人が残したと聞く格言を実行すべきということです。今回ご紹介する3ステップに分ける方法は繰り返すことで無限に細分化できる(?)気がするので、是非試して見てください。
インプット → 処理 → アウトプット の3ステップに分ける
はい、見出しが結論です。
世の中の多くの事柄は、この3ステップに分割可能と思います。
まずは素直に、CRUDのうちのReadにあたるユーザー詳細画面で考えましょう。
ステップに分け、分けたステップを順番に考えていき、なんか実装できそう、と思える状態にします。
3つのステップへの帰属
現在の粒度だと、仕様とかは考えずとも以下の3ステップが思い浮かびます。
| インプット | 処理 | アウトプット |
|---|---|---|
| API | (何か必要な処理) | UI/コンポーネント |
流石に粒度粗すぎだったでしょうか。特に2ステップ目は何も述べていいないようにも見えます。しかし、これでいいとも思うのです。少なくとも分割はできているので、今度はどこから考えようという段階です。
順番に考えていく
私が思うに、基本的には以下の順番が良いことが多いです。
- アウトプットの要件をよく確認し、必要なデータを整理する
- 1で整理した必要なデータを得られる情報源(インプット)を探す
- 2で見つけたデータをどう変換したら良いか(処理)を検討する
1. アウトプット:要件をよく確認し、必要な情報を整理する
要件の確認といえば当然ですが、ここで特に大事なのはどんなデータが必要かです。
ユーザー詳細画面ならば、例えばQiitaにおいては以下のようにユーザー情報以外にも記事など多くの情報を含んでいます。このような画面では、REST APIで情報を取得した場合、一つのAPIでは情報が足りない場合が多いので、このステップで整理した必要なデータをどこから得られるのか考える必要があります。
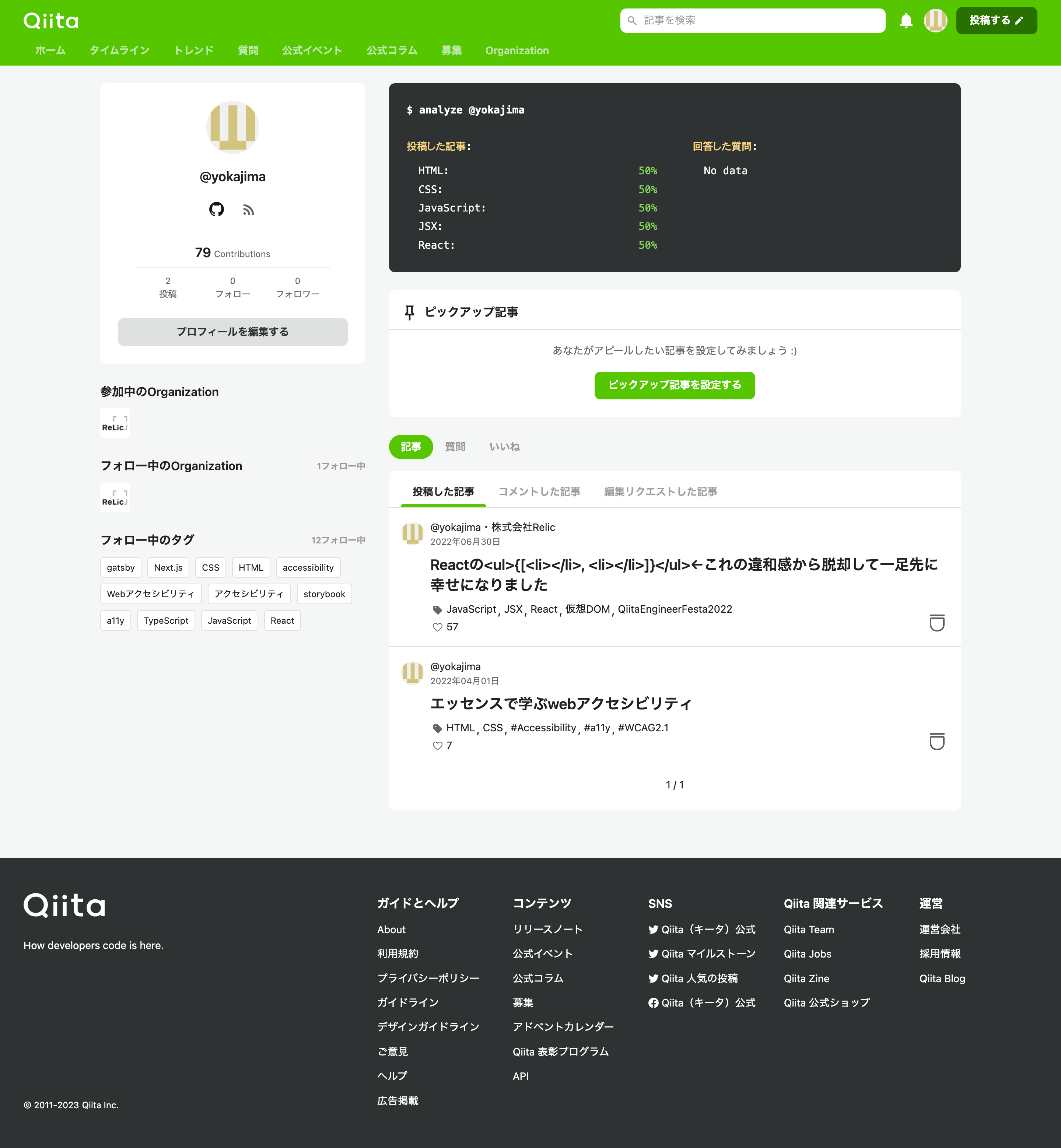
Qiitaのユーザー詳細画面においては、ざっくりでは以下が必要そうですね。
- ユーザーアイコン
- ユーザー名
- Github等のリンク
- コントリビューション数
- フォロー数
- フォロワー数
- 参加中のOrganization
- Organizationのアイコン
- フォロー中のタグ
- ピックアップ記事情報
- 投稿した記事の情報
- コメントした記事の情報
- 編集リクエストした記事の情報
2. インプット:必要な情報を得られる情報源を探す
前のステップで確認したように、一つの画面を構成するにも必要な情報は多いです。
このステップではどんなAPIを叩けば良いのか、あるいは、global stateなどAPI以外から得るべき情報はないかなどを整理します。
例えばQiitaのユーザー詳細画面では、以下のコンポーネント内でもユーザー情報と記事の情報が混在しています。

このような場合はSwaggerなどAPIの一覧を確認し、必要な情報が得られそうなAPIを選びます。ログイン中に自分のユーザー詳細を見る分にはユーザー情報は取得済みでキャッシュされているかglobal stateにもっているけど記事情報は新しくAPIを叩く必要があるかな、とかそういうことを考えます。
3. 処理:情報をどう変換したら良いかを検討する
このステップでようやく実装について考えます。
ステップ2で決定したAPIなどのデータは、そのままでは取り扱いにくいはずです。再び以下のコンポーネントについて考えます。

例えばいいね数は、いいね数という形ではなくいいねをしたユーザーの一覧がユーザーidの配列として用意されているとしましょう。
type Article = {
title: string // 例: エッセンスで学ぶwebアクセシビリティ
tags: string[] // 例: ['HTML', 'CSS', 'Accessibility', 'a11y', 'WCAG2.1']
favorites: number[] // 例: [1, 23, 35, 38, 88, 90, 99]
created_at: string // 例: '2022年04月01日'
}
こういう場合、いいね数を取得するには以下のようにlengthを使って配列長を取得する必要があります。
const article: Article = {...}
const favoriteNumber: number = article.favorites.length // Article → number に型を変換する処理
このくらいであれば非常に簡単ですが、色々な手段を使って型変換をする必要があります。
いい例が思いつかなかったので、イメージとして以下のような感じだと思ってください。
const 三本のわらしべ = ['わらしべ', 'わらしべ', 'わらしべ']
const 屋敷 =
三本のわらしべ // 最初は3本のわらしべからスタート(インプット)
.map(item => item === 'わらしべ' ? '蜜柑' : item) // 入力値が'わらしべ'か判定(処理)し、アウトプットとして'蜜柑'に交換
.map(item => item === '蜜柑' ? '反物' : item) // 入力値が'蜜柑'か判定(処理)し、アウトプットとして'反物'に交換
.map(item => item === '反物' ? '馬' : item) // 入力値が'反物'か判定(処理)し、アウトプットとして'馬'に交換
.map(item => item === '馬' ? '屋敷' : item) // 入力値が'馬'か判定(処理)し、アウトプットとして'屋敷'に交換
上のコードは、わらしべ長者が度重なる交換により屋敷を手にした様をあらわしています。何を伝えたいかというと、わらしべからいきなり屋敷に変えることはできないのと同じで大抵のデータは単純には変換できず配列操作を何回もメソッドチェーンして値を作る必要があるということ、一つ一つの配列操作に渡されるコールバック自体もインプット→処理→アウトプットの構造をもっていることです。
ただ、あまり処理が複雑になる場合は情報源を考え直したりAPIを作り直せないか検討するなど、前提を疑ってみるのも重要です。
実際の複雑さはどうあれ、このようにアウトプットたるUI即ちコンポーネントが望む形にインプットされたデータを変換できれば、それは即ち実装ができてしまっているということです。
他の例でコンパクトに実践する
先程までは長々と説明したので全体の構造が捉えにくくなっていました。今度は何か一般的なフォームの作成について、3ステップに分けて考えてみます。
1. まず、フォームの作成を3つのステップに分けます
| インプット | 処理 | アウトプット |
|---|---|---|
| フォームの入力値 | (フォーム送信〜POST Requestの間にする処理) | POST Requestのbody |
ユーザー詳細画面では、データの方向がバックエンド→フロントエンドだったのに対し今回はフロントエンド→バックエンドの方向でデータが渡されます。
2. 次にアウトプットから必要なデータを確認します
ここでは具体的な画面は出しませんが、フォーム送信の場合は明確にAPIに従うことになると思うので、APIの一覧をご確認いただければ十分そうです。
3. 次にどのようなインプットを受け取る必要がありそうか確認します
これは多くの場合APIで求められた値に従ったフィールドをフォームに設置すれば大丈夫ですね。
ただ、ユーザーのユニークIDなど、バックエンドが必要としているデータにはユーザー自身も知らないデータが含まれる場合があります。そういったデータはユーザーの代わりにアプリケーションが自分で知っているはずなので、hidden inputなどでフォームに渡したり、場合によってはインプット側ではなく処理側で担保するなど検討が必要です。
4. 処理の内容を考えます
フォームの入力値は大抵そのままAPIが求める形になっていません。例えば、普通にHTMLのフォームだとあらゆる入力値は文字列で渡されますが、checkboxはboolean値で渡したいという場合など、変換が必要です。
...いかがでしょうか。何となく、フォームの実装はできそうな気がしてきたのではないかと思います。かなり動的でstateを持つ必要がある場合は他にも色々考えることはありますが、骨子としては変わらないはずです
3つのステップに分けた意味を振り返る
一応、ここまでで細かい説明は終了です。流石にまだ何も得られていないと思うので、一体何だったのか、腹落ちさせるフェーズに入ります。
ここまででやっていたことは、Type-Drivenでデータの流れに着目しアプリケーションの構造を捉えようということでした。
現代のReactアプリケーションであれば当然TypeScriptは導入済みかと思います(迫真)。即ち、コンポーネントのpropsには型が定義され、APIで取得したデータにも型が明示され、それ以外の中間の処理においても型は明らかになっていると思います。
その中でも特に重要なのがインプットとアウトプットの両末端の方で、その中間の処理はインプットの型をアウトプットの型に変換するための補助的な層に過ぎないと考えることで困難の分割が進んだ状態になるという考え方です。
また、その中間の処理層も同様に3つのステップに分けられます。Reactコンポーネント自体、propsをインプットとして色々処理した結果JSXをreturnする、単純な構造の関数です。ここでも、3ステップあり、その結果型の変換がなされているという同様の構造があります。そうしてアプリケーション全体を大小さまざまなインプット→処理→出力の構造で捉えることで全体が非常にクリアになります。
これは、React以外のあらゆるアプリケーションでも同様に言える気もしますが、特にReactは関数型のプログラミングパラダイムを目指した宣言的UIのライブラリであるためこの構造が相当に通用します。この点はより専門的な記事が無限にあると思うので、googleやChatGPTにでも聞いてみてはいかがでしょうか
まとめ
今回はReactアプリケーションを3つのステップに分解することで、画面の作り方何も分からん地獄からは抜け出せることを目指しました。
実際には副作用やステートが増えるなど色々複雑化すると3ステップでは捉えにくくなるかもですが、基本骨格としては常に適用できるので意識していただければと思います。
今回とは別の分け方も考えうるはずで、色々な考え方と組み合わせて入れ子関係を作ることが適切にアプリケーションを構造化するコツだと思うので、ぜひ他の方法でも分割できないか考えていくことをお勧めします。
ここまで読んでいただきありがとうございました.
採用のお知らせ
株式会社Relicでは、エンジニアを積極的に採用中です。
またRelicでは、地方拠点がありますので、U・Iターンも大歓迎です!🙌
少しでもご興味がある方は、Relic採用サイトからエントリーください!
■新卒採用
https://relic.co.jp/categories/job_2302?utm_source=qiita&utm_medium=article&utm_campaign=qiita_article
■中途フロントエンドエンジニア
https://relic.co.jp/categories/job_4?utm_source=qiita&utm_medium=article&utm_campaign=qiita_article
■中途サーバーサイドエンジニア
https://relic.co.jp/categories/job_3?utm_source=qiita&utm_medium=article&utm_campaign=qiita_article