この話のゴール
- Python の list, int のデータ構造を理解する
- CPython のソースに向き合えるようになる(といいな)
CPython とは
https://en.wikipedia.org/wiki/CPython より
CPython is the default, most widely used implementation
of the Python programming language. It is written in C.
In addition to CPython, there are other "production-quality"
Python implementations: Jython, written in Java for the JVM,
PyPy, written in RPython and translated into C, and
IronPython, which is written in C# for the Common Language
Infrastructure. There are also several experimental implementations.
- Python の実装
- 標準の実装
- 最も広く使われている実装
- C で記述されている
ソースコードの取得
CPython のソースコードリポジトリは以下で公開されている。
- Mercurial repository
https://hg.python.org/cpython - Semi-official read-only mirror
https://github.com/python/cpython
今回は後者からとってきます。
% git clone https://github.com/python/cpython.git
Cloning into 'cpython'...
remote: Counting objects: 599980, done.
remote: Total 599980 (delta 0), reused 0 (delta 0), pack-reused 599980
Receiving objects: 100% (599980/599980), 236.15 MiB | 2.20 MiB/s, done.
Resolving deltas: 100% (483480/483480), done.
Checking connectivity... done.
% cd cpython
% git branch
* master
% ls
Doc/ Misc/ Python/ configure.ac
Grammar/ Modules/ README install-sh*
Include/ Objects/ Tools/ pyconfig.h.in
LICENSE PC/ aclocal.m4 setup.py
Lib/ PCbuild/ config.guess*
Mac/ Parser/ config.sub*
Makefile.pre.in Programs/ configure*
Python には 2.x 系と 3.x 系があります (https://wiki.python.org/moin/Python2orPython3) が、master branch に入っている後者の実装を見ていきます(読んでいく部分については違いはないと思いますが)
今回の読解対象
ソースコードを取ってきたものの、目的なしに読み始めると道に迷いそうなので、
みんなの大好きな list
>>> xs = [1, 2, 3]
>>> xs[1]
2
>>> type(xs)
<class 'list'>
を対象として、その基本的な部分を見ていくことにします。
実装箇所の特定
対象を決めたものの、取ってきたソースツリー上のいったいどこにその実装が存在しているのか
見当が付いていませんので、エラーが発生したときのメッセージを手掛りに当たりを付けていきます。
list の要素数よりも大きい index を与えて要素取得しようとすると以下のようなエラーになります:
>>> xs = [0, 1, 2]
>>> xs[3]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
エラーメッセージで grep をかけると、2つのファイルが該当します:
% find . -type f -print0 |xargs -0 grep -l "list index out of range"
./Doc/library/multiprocessing.rst
./Objects/listobject.c
前者の中身を見るとドキュメント中でエラーメッセージを例示しているように見えるので、
後者の listobject.c の方に実装が存在していると考えます。
そこで、listobject.c 内を "list index out of range" で探すと、関数 PyList_GetItem() と list_item() の二箇所で同じメッセージが使われていて、どちらか一方が探している実装のようです。
試しに後者の
static PyObject *
list_item(PyListObject *a, Py_ssize_t i)
の使用箇所の一つ
static PyObject *
list_subscript(PyListObject* self, PyObject* item)
{
if (PyIndex_Check(item)) {
Py_ssize_t i;
i = PyNumber_AsSsize_t(item, PyExc_IndexError);
if (i == -1 && PyErr_Occurred())
return NULL;
if (i < 0)
i += PyList_GET_SIZE(self);
return list_item(self, i);
}
else if (PySlice_Check(item)) {
...
から追っていってみると、list_methods という配列
static PyMethodDef list_methods[] = {
{"__getitem__", (PyCFunction)list_subscript, METH_O|METH_COEXIST, getitem_doc},
...
};
で使われていることがわかり、さらにその配列は
PyTypeObject PyList_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"list",
...
list_methods, /* tp_methods */
という構造体で使われています。ここで、listobject.c の中をもう少し眺めていると
PyDoc_STRVAR(getitem_doc,
"x.__getitem__(y) <==> x[y]");
という記述が見つかります。これは __getitem__ のドキュメントで、 Python からは
>>> xs.__getitem__.__doc__
'x.__getitem__(y) <==> x[y]'
とすると見れますが、xs[y] と __getitem__(y) は同じだということを言っています。
ドキュメントだけでは本当かどうかわかりませんので、動作を見てみると、
>>> xs = [0, 1, 2]
>>> xs.__getitem__(0)
0
>>> xs.__getitem__(1)
1
>>> xs.__getitem__(2)
2
>>> xs.__getitem__(3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
確かに同じ動作をしているようです。地道にコードを読解していってもよいのですが、駆け足で進むために、仮説を立ててそれを検証するという道筋で行きます。
上で見たことを元に仮説を立ててみます:
- python で
xs[3]とすると__getitem__が呼ばれる -
__getitem__の C による実装がlist_subscript()
検証してみましょう。二つあったメッセージのうち、list_itemの方の末尾に "!" を付けて区別できるようにして、
static PyObject *
list_item(PyListObject *a, Py_ssize_t i)
{
if (i < 0 || i >= Py_SIZE(a)) {
if (indexerr == NULL) {
indexerr = PyUnicode_FromString(
"list index out of range!"); /* "!" を末尾に付けた */
ビルドして確認すると
% ./configure
% make
% ./python.exe
Python 3.6.0a0 (default, Sep 20 2015, 00:14:29)
[GCC 4.2.1 Compatible Apple LLVM 6.1.0 (clang-602.0.53)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> xs = [1, 2, 3]
>>> xs[3]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range!
>>> xs.__getitem__(3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range!
と、xs[3] でも __getitem__(3) でも先程変更したメッセージが表示されました。
したがって、xs[i] としたときも __getitem__(i) としたときも list_item() が呼ばれていることが確認でき、上記の仮説の裏付けが取れました。
list の要素取得
異常系処理を手掛りとして list の要素取得の実装箇所がわかったので、今度は同じ関数の正常系パスの方を見ると、
static PyObject *
list_item(PyListObject *a, Py_ssize_t i)
{
...
Py_INCREF(a->ob_item[i]);
return a->ob_item[i];
}
と、PyListObject::ob_item[] の i 番目の要素(型は PyObject のポインタ)を単に返しているだけです。つまり、
- list のデータ構造は PyListObject として表現される。
- PyTypeObject PyListType で list に対する操作が表現される。
- list の各要素のポインタは
PyListObject::ob_item[]配列に格納されている。 - i番目の要素に到達するコスト: O(1)
- 要素を挿入するコスト: O(N)
- list の各要素のデータの実体は PyObject で表現されているようだ

PyObject
さて、 list の各要素のデータが PyObject で表現されていると書きましたが、PyObject は
/* Nothing is actually declared to be a PyObject, but every pointer to
* a Python object can be cast to a PyObject*. This is inheritance built
* by hand. Similarly every pointer to a variable-size Python object can,
* in addition, be cast to PyVarObject*.
*/
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;
と定義されていて、メンバの名前から推測すると参照カウントと型の情報しか持っていなさそうです。
じゃあ例えば整数とか文字列といったものはどこだ?という疑問が湧いてきます。
コメントによると
- 全ての Python object はキャストするとこの構造(PyObject)になる
- 継承を手動で構築したものになっている
とのこと。具体的な場合として整数(PyLongObject)について見てみましょう。
まず、PyLongObject は struct _longobject の別名になっています:
typedef struct _longobject PyLongObject; /* Revealed in longintrepr.h */
_longobject は
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
};
と PyObject_VAR_HEAD と ob_digit で構成されており、PyObject_VAR_HEAD は
/* PyObject_VAR_HEAD defines the initial segment of all variable-size
* container objects. These end with a declaration of an array with 1
* element, but enough space is malloc'ed so that the array actually
* has room for ob_size elements. Note that ob_size is an element count,
* not necessarily a byte count.
*/
# define PyObject_VAR_HEAD PyVarObject ob_base;
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;
と、PyObject と、それ以降の要素数を表す ob_size からなっています。
構造体 PyVarObject の先頭要素として PyObject が、struct _longobject の先頭要素として PyVarObject が現れているので、PyVarObject のポインタは PyObject のポインタに、struct _longobject のポインタは PyVarObject のポインタにキャストして使うことができる (キャストに関しては注意すべき点もあるので例えば http://stackoverflow.com/questions/8416417/nested-structs-and-strict-aliasing-in-c を参照のこと)。これが、"inheritance built by hand" の意味するところです。
また、 struct _longobject 構造体の最後は、 ob_digit[1] のようにサイズ1の配列が宣言されていますが、これは C で構造体メンバとして可変長配列を表現する手法です。
実際の確保は欲しい要素数分を取ったサイズで行い、それをキャストして利用します:
PyLongObject *
_PyLong_New(Py_ssize_t size)
{
PyLongObject *result;
/* Number of bytes needed is: offsetof(PyLongObject, ob_digit) +
sizeof(digit)*size. Previous incarnations of this code used
sizeof(PyVarObject) instead of the offsetof, but this risks being
incorrect in the presence of padding between the PyVarObject header
and the digits. */
if (size > (Py_ssize_t)MAX_LONG_DIGITS) {
PyErr_SetString(PyExc_OverflowError,
"too many digits in integer");
return NULL;
}
result = PyObject_MALLOC(offsetof(PyLongObject, ob_digit) +
size*sizeof(digit));
if (!result) {
PyErr_NoMemory();
return NULL;
}
return (PyLongObject*)PyObject_INIT_VAR(result, &PyLong_Type, size);
}
ここで、ob_digit のオフセット以降に、対象の整数値を格納するのに必要な size 個分の digit 配列を確保していて、例えば、1桁で値を格納する場合は _PyLong_New(1) で、2桁で値を格納する場合は _PyLong_New(2) でメモリを確保した上で、配列の各要素に値をエンコードして格納するという使い方をする(呼び出し元のコードをすぐ後で見ます)。
return する前に PyObject_INIT_VAR
# define PyObject_INIT(op, typeobj) \
( Py_TYPE(op) = (typeobj), _Py_NewReference((PyObject *)(op)), (op) )
# define PyObject_INIT_VAR(op, typeobj, size) \
( Py_SIZE(op) = (size), PyObject_INIT((op), (typeobj)) )
# define Py_TYPE(ob) (((PyObject*)(ob))->ob_type)
# define Py_SIZE(ob) (((PyVarObject*)(ob))->ob_size)
を用いて、
- ob_type に型クラスのオブジェクト PyLong_Type を設定
- ob_size に可変部分の digit の要素数 size を設定
というメンバ初期化を行ったものを返しています。
つぎに _PyLong_New() の呼び出し元を見よう:
PyObject *
PyLong_FromLong(long ival)
{
PyLongObject *v;
unsigned long abs_ival;
unsigned long t; /* unsigned so >> doesn't propagate sign bit */
int ndigits = 0;
int sign = 1;
CHECK_SMALL_INT(ival);
if (ival < 0) {
/* negate: can't write this as abs_ival = -ival since that
invokes undefined behaviour when ival is LONG_MIN */
abs_ival = 0U-(unsigned long)ival;
sign = -1;
}
else {
abs_ival = (unsigned long)ival;
}
/* Fast path for single-digit ints */
if (!(abs_ival >> PyLong_SHIFT)) {
v = _PyLong_New(1);
if (v) {
Py_SIZE(v) = sign;
v->ob_digit[0] = Py_SAFE_DOWNCAST(
abs_ival, unsigned long, digit);
}
return (PyObject*)v;
}
...
/* Larger numbers: loop to determine number of digits */
t = abs_ival;
while (t) {
++ndigits;
t >>= PyLong_SHIFT;
}
v = _PyLong_New(ndigits);
if (v != NULL) {
digit *p = v->ob_digit;
Py_SIZE(v) = ndigits*sign;
t = abs_ival;
while (t) {
*p++ = Py_SAFE_DOWNCAST(
t & PyLong_MASK, unsigned long, digit);
t >>= PyLong_SHIFT;
}
}
return (PyObject *)v;
}
- (説明しなかったが) 小さな整数の場合は
CHECK_SMALL_INTで確保済みオブジェクトを返す - 新たにオブジェクトを確保しない
- Python の int が immutable なのでできる芸当
- 続いて値が 1 桁で表現できる場合は
_PyLong_New(1)でオブジェクトを確保し、 -
ob_digit[0]に値を格納 -
ob_sizeに正負の情報を格納 - 値を複数桁で表現する処理が続く
ここまでで見たこと (+α) から、整数(Python の int)の構造を図示すると
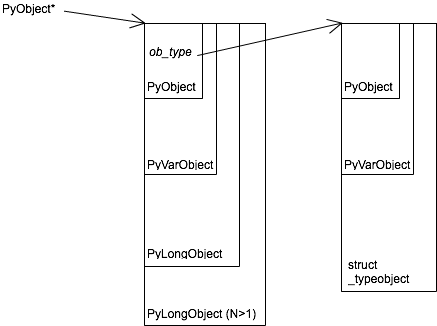
- 整数の実体の PyLongObject は PyObject を継承していた
- 型の性質を示す struct _typeobject (= PyTypeObject) も PyObject を継承していた
list への要素の追加
息切れしてきたので詳細説明は省いて listobject.c の要素追加処理のまとめだけ。
-
listappend()→app1()→list_resize() - 確保済みサイズが必要なサイズ以上で、かつ必要なサイズの倍以内なら領域の再確保をしない
- ob_size を更新するだけ
- そうでない場合は必要なサイズよりもちょっと多めに領域確保する
まとめ
- CPython の list, int のデータ構造をちょっとだけ読んでみた
- grep と想像力を使い、仮説と検証を繰り返すことで、何となく理解できた
- Python の list のデータ構造の中心には PyObject のポインタの配列が居た
- 配列のサイズとか、操作するための関数なども居る
- Python のオブジェクトは PyObject で表現されていた
- 具象クラス (e.g. PyLongObject) のインスタンスとして領域確保されている
- それを PyObject にキャストしたものが list から参照されている
- C 言語で継承関係や可変長配列を表現する典型的な手法が用いられている
- list への要素の追加、削除では、realloc の頻度を抑える工夫がなされていた
- list や dict の実装ではパフォーマンスを意識した工夫がいろいろ見れます