先日のMUTEKワークショップで@satoruhigaさんがOpenCVとの連携の例を取り上げてくださっていましたが、同じノリでOpenPoseも使えるようになるんじゃないかと思って試してみました。
OpenPoseとは
何をいまさらな感じですが、OpenPoseとはCMUが研究開発している人体認識ライブラリです。これがすごいのは、デプスセンサなどを搭載していない、いわゆるただのWebカメラの画像でもかなりの精度で複数人の姿勢や表情などを認識できる点です。
現状リアルタイムで動かすにはかなりのGPU性能を必要としますが、解像度を落とすなどすればGTX1080程度のグラボでもそれなりな感じで動きます。
元々はC++で開発されているのですが、今年の6月にPythonがサポートされました。今回はこのPythonのAPIを利用することにします。
**※なお、今回はWindows上の下記環境で動作確認をしていますが、Macで動くかは確認していません。**どなたか試してみたら結果を教えていただけるとありがたいです。
| Software | Version |
|---|---|
| Windows | 10 Home (Build 17134.345) |
| TouchDesigner | 2018.26750 |
| CMake | 3.13.1 |
| Visual Studio | Community 2017 Version 15.7.2 |
| CUDA | 9.2 |
| cuDNN | 7.3.1 |
(グラフィックボードはNVIDIA GeForce GTX 1060を使用)
OpenPoseのビルド
基本的には公式のインストール方法に従ってビルドしていきます。かなり丁寧に説明が書いてあるので、詳細な手順についてはそちらを参照して下さい。
ソースコードのダウンロード
最新リリース版の1.4.0を使用します。こちらよりソースをダウンロードします。(試していませんが)もちろんgitで最新をcloneしても構いません。
CMake
ビルドファイルを作成するためにCMakeを使います。インストールしていない場合はこちらよりダウンロードしてインストールします。
Visual Studio
2017 Community Editionで大丈夫ですが、Version 15.7.x以降の場合はCUDAのヘッダファイルを修正する必要があります(後述)。
CUDA
インストールドキュメントにVS 2017を使う場合はCUDA 9を使うようにとあるので、9.2をダウンロードしてインストールします。
CuDNN
CUDA 9.2用の7.3.1をダウンロードします。解凍してできたcudnn64_7.dll, cudnn.h, cudnn.libをCUDAのインストールディレクトリ(通常はC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.2)内にあるbin, include, lib\x64内にそれぞれコピーします。
CMakeの設定、ソリューションファイルの生成
CMake GUIを起動し、"Where is the source code:"にダウンロードしたソースのディレクトリ、"Where to build the binaries:"にビルドしたファイルを配置するディレクトリを指定し、”Configure"ボタンをクリックします。
ビルド環境を指定するダイアログが出てくるので、"Visual Studio 15 2017 Win64"を選択し、"Finish"をクリックします。
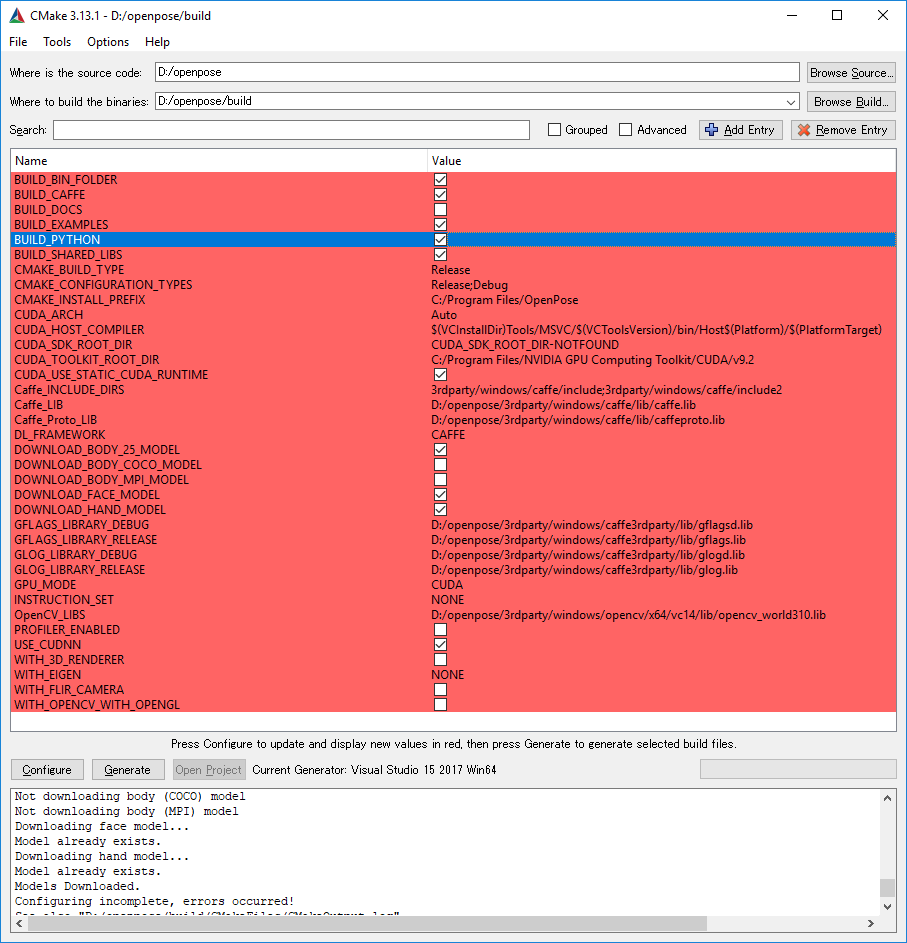
必要なファイルなどがダウンロードされたのちに、上のような画面が表示されます。Python APIはデフォルトではビルドされないので、BUILD_PYTHON_LIBSのチェックボックスをオンにします。
"Configure"ボタンをさらに2度ほどクリックすると、赤い箇所が消えますので、"Generate"ボタンをクリックしてソリューションファイルを生成します。
Visual Studio上でのビルド
出来上がったソリューションファイルを起動し、Releaseターゲットでビルドします。
この際、Visual StudioのバージョンがVersion 15.7.x以降の場合、_MSC_VERの値が変わっているため、CUDA 9.2内のヘッダファイルのバージョンチェックで弾かれてビルドできません。
CUDA\v9.2\include\crt\内のhost_config.hを編集します(要管理者権限)。
# if defined(_WIN32)
# if _MSC_VER < 1600 || _MSC_VER > 1913
# error -- unsupported Microsoft Visual Studio version! Only the versions 2012, 2013, 2015 and 2017 are supported!
131行目付近の_MSC_VER > 1913となっている箇所をMSC_VER > 1999に修正します。
※2018.12.14 追記: 早速1914以降のバージョンが出てきているので、1900番台ならOKということに変更しました。
# if _MSC_VER < 1600 || _MSC_VER > 1999
ビルドが完了したら、OpenPoseDemoプロジェクトをスタートアッププロジェクトに設定して動かしてみます。Webカメラの映像に対してトラッキング情報が重畳されているような絵が出れば無事成功です。
PythonのAPIもちゃんと生成されているか確認しましょう。ビルド先にpython\openposeというディレクトリができ、openpose.pyやRelease\_openpose.dllなどが生成されていればOKです(このディレクトリをあとでPythonから指定します)。
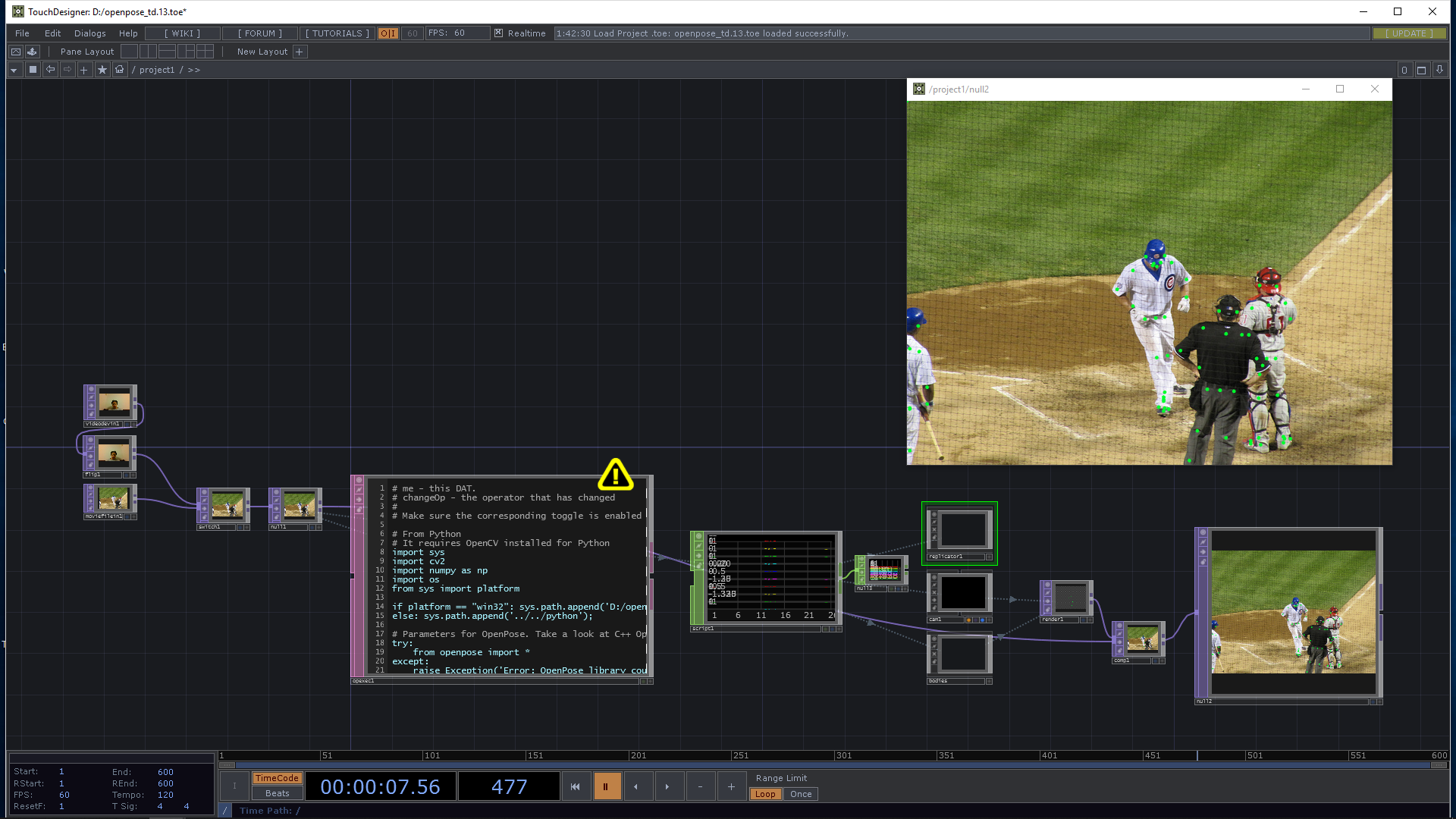
TouchDesignerからの呼び出し
.toeファイルはGitHubに上げてありますので適宜ダウンロードしてみてください。
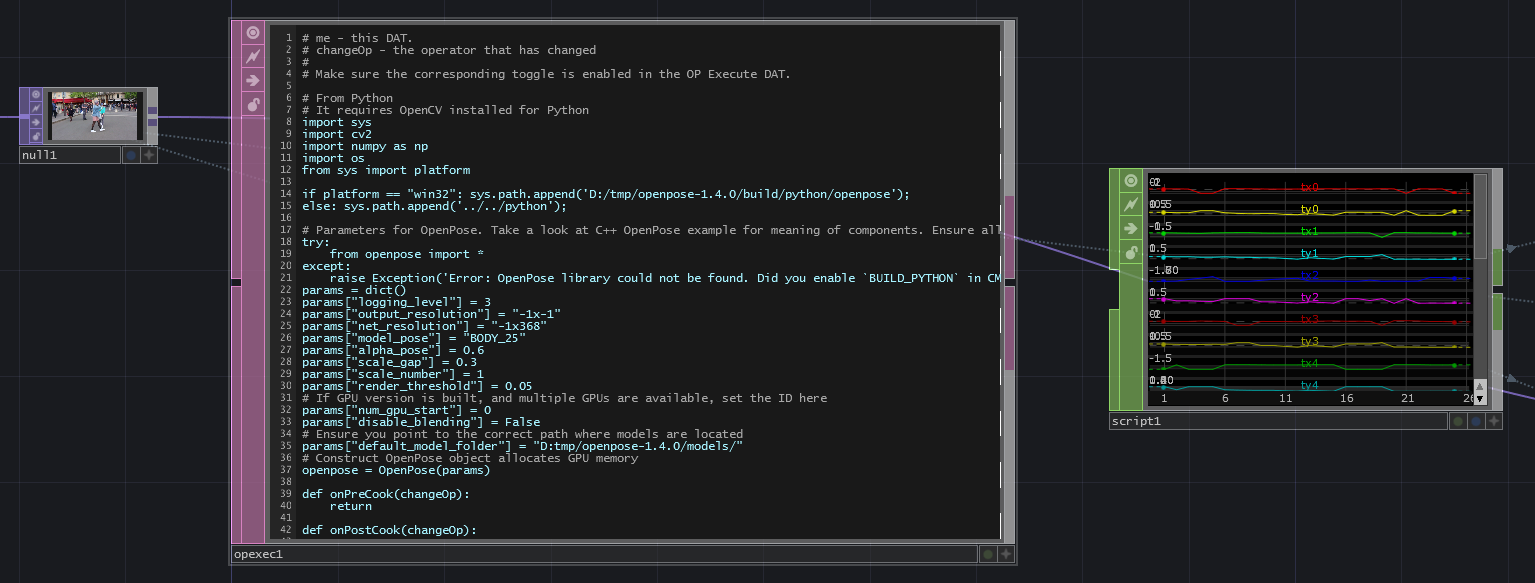
基本的な処理の流れは@satoruhigaさんのOpenCVのサンプルと同じです。OP Execute DATを使って、監視対象のTOPのCook処理が走るたびにOpenPoseのAPIを呼ぶようにしています。
前半はほとんど初期化処理です。
import sys
import cv2
import numpy as np
import os
from sys import platform
if platform == "win32": sys.path.append('D:/openpose/build/python/openpose');
else: sys.path.append('../../python');
# Parameters for OpenPose. Take a look at C++ OpenPose example for meaning of components. Ensure all below are filled
try:
from openpose import *
except:
raise Exception('Error: OpenPose library could not be found. Did you enable `BUILD_PYTHON` in CMake and have this Python script in the right folder?')
params = dict()
params["logging_level"] = 3
params["output_resolution"] = "-1x-1"
params["net_resolution"] = "-1x368"
params["model_pose"] = "BODY_25"
params["alpha_pose"] = 0.6
params["scale_gap"] = 0.3
params["scale_number"] = 1
params["render_threshold"] = 0.05
# If GPU version is built, and multiple GPUs are available, set the ID here
params["num_gpu_start"] = 0
params["disable_blending"] = False
# Ensure you point to the correct path where models are located
params["default_model_folder"] = "D:/openpose/models/"
# Construct OpenPose object allocates GPU memory
openpose = OpenPose(params)
このうち、OpenPoseライブラリへのパスを追加している以下の行と、
sys.path.append('D:/openpose/build/python/openpose')
認識モデルの場所を指定している下記の行は
params["default_model_folder"] = "D:/openpose/models/"
それぞれ適切なパスの値に変更して下さい。
OP Execute DATのPost Cookのスライダをオンにして、実際の処理の部分をonPostCook()内に記述します。
def onPostCook(changeOp):
img = changeOp.numpyArray(delayed=True)
h, w, ch = img.shape
aspect = w / h
#this comes with float32
img = img[:,:,:3]
img = np.flipud(img)
img = 255 * img
img = img.astype(np.uint8)
# Output keypoints and the image with the human skeleton blended on it
keypoints, output_image = openpose.forward(img, True)
# Print the human pose keypoints, i.e., a [#people x #keypoints x 3]-dimensional numpy object with the keypoints of all the people on that image
scriptOp = op('script1')
scriptOp.clear()
scriptOp.numSamples = 25
n = len(keypoints)
for i in range(n):
tx = scriptOp.appendChan('tx' + str(i))
ty = scriptOp.appendChan('ty' + str(i))
m = len(keypoints[i])
for j in range(m):
x = keypoints[i][j][0] / w * 2.0 - 1.0
x *= aspect
y = keypoints[i][j][1] / h * -2.0 + 1.0
tx[j], ty[j] = x, y
return
Python版のOpenPoseはOpenCVと同様に、numpyの配列を画像の入力として受け取るようになっていますので、TOPの画像をnumpyArray()を使ってnumpyに変換します。
この時注意が必要なのは、TouchDesignerのTOPはGPUで処理しやすいよう、内部のピクセルフォーマットが32bit float x 4 (RGBA) になっているのに対し、OpenPoseが受け取るのは8bit unsigned int x 3 (RGB) である点です。また、y座標もOpenPoseとは逆向きになるため、最初に前処理としてこれらの変換を行う必要があります。
逆に言うと気をつける点はそのくらいで、あとはAPI呼び出し1行で特徴点が返ってきます。これは画像内のピクセル座標なので、TouchDesignerで使いやすいように適当に正規化し、Script CHOPにチャンネルデータとして流し込みます。1人目の特徴点群がチャンネルtx0, ty0、2人目がtx1, ty1...という具合です。
今回使用したBODY_25というモデルの場合、人ひとりにつき25個の特徴点が返ってきます。何番目の特徴点が体のどのパーツに対応しているかはこちらの図を参照して下さい。
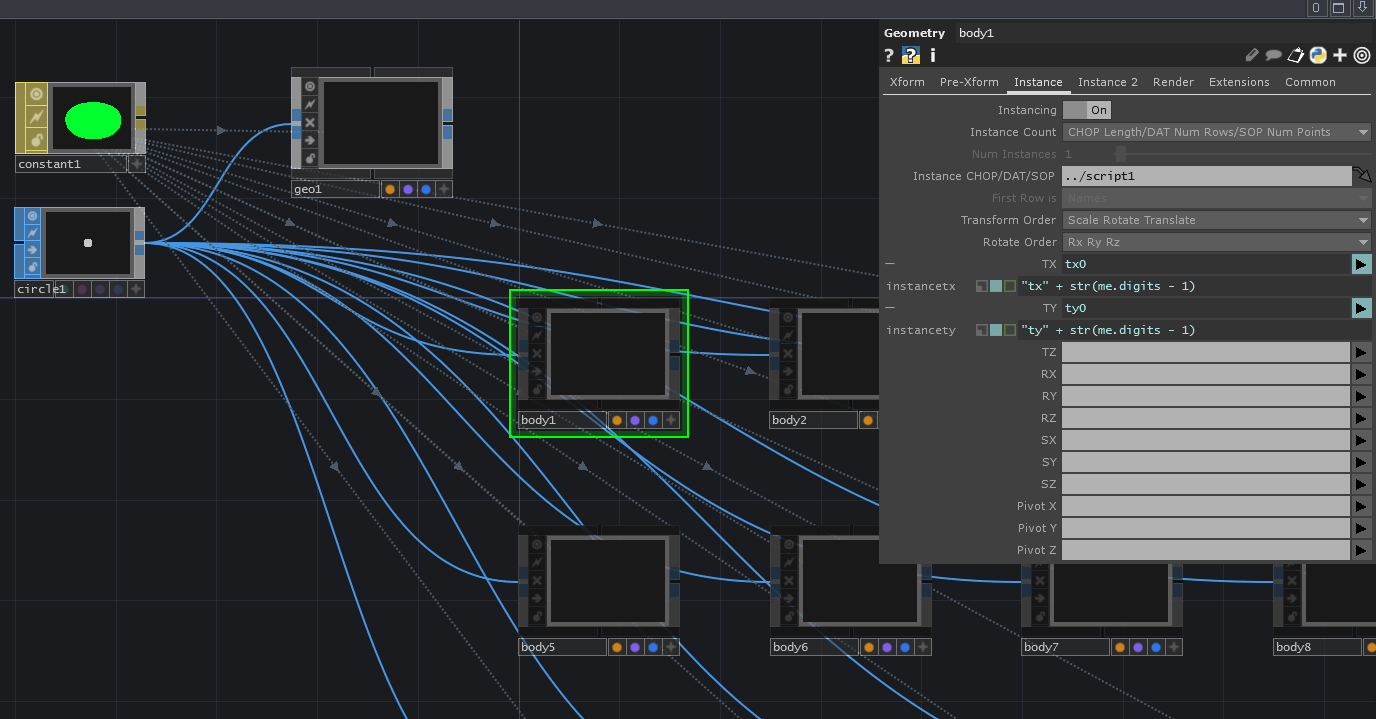
結果のレンダリング方法ですが、今回は25個のCircle SOPをインスタンシングしたGeometry COMPを用意し、それを検出した人数分だけReplicator COMPを使って複製するというやり方にしています。
おわりに
OpenPoseのサンプルで付属している動画や、Webカメラのライブ映像でも一応動作しました。フレームレートはGTX1060で3-4fpsといったところですが...。

現時点ではかなりマシンスペックを要求されるため使用用途は限られそうですが、ライブラリとハードウェアの両方が進化していくことでこうした処理も難なくこなせる時代が割とすぐ来そうな気がします。