はじめに
みなさん、Zoom楽しんでますでしょうか?
Webカメラが無いことを良いこと(?)に、自分のビデオ表示で好き勝手やってる人も
少なからずいるんじゃないかと思います。(いない)
前回記事参照: 「Zoom背景使いたいけどグリーンスクリーンもスペックも足りない・・・せや!!!」
電気屋さんでWebカメラ売ってないのは本当に困りますねーもう。
やったこと
音声認識結果を字幕としてバーチャルWebカメラにオーバーレイして表示します。
こんな感じ(出オチ感)↓
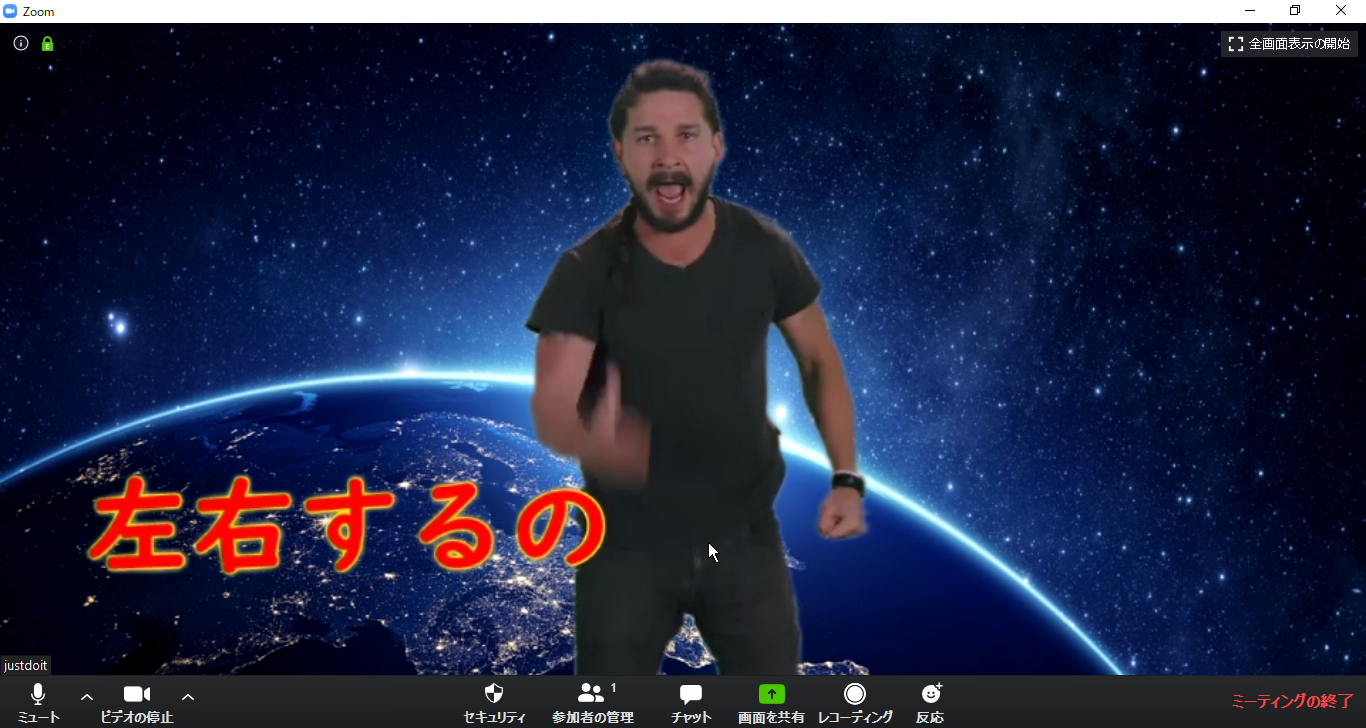
概要
こんな感じです。
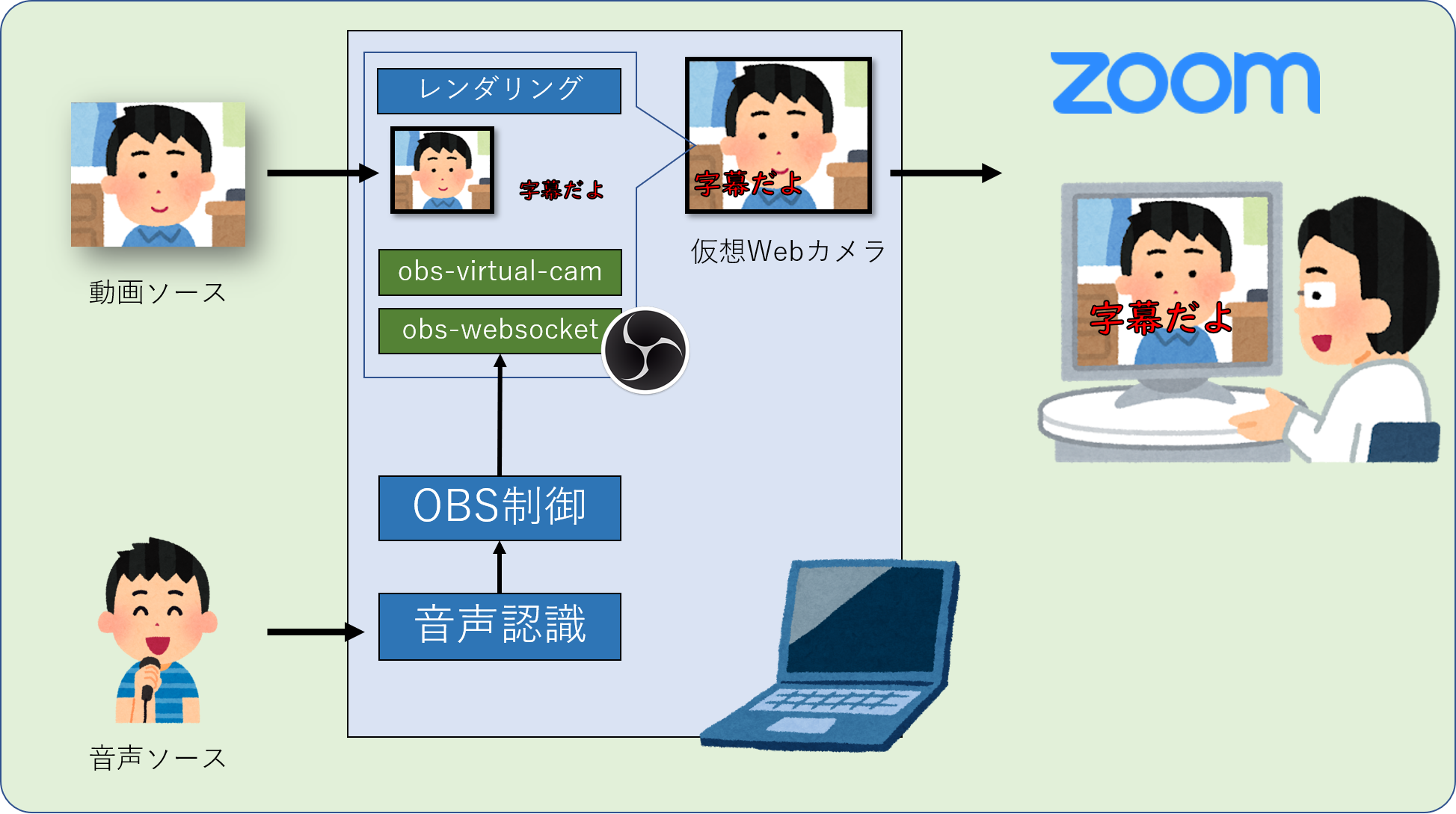
前回同様OBSを使用します。OBSで動画と字幕を仮想Webカメラにレンダリングして、それをZoomで配信する感じです。
なお、音声認識には .NET Framework を使用して、OBSの字幕制御にはプラグイン「obs-websocket」と node.js を使用しました。
やり方
環境としてはWindows 10 64bitのノートパソコンを使用して、開発/配信を行いました。
↓これぐらいの結構古いマシンでも全然イケます。
CPU: Core i5-2520M
RAM:16GB
準備(開発環境)
まずは開発環境を整えます。Visual Studioを入れます。
今回は同人(個人利用?)アプリの開発なのでCommunity Editionでいきます。
昔入れた Visual Studio 2015 Community が入っていたのでそれ使いました。
あとはnode.jsにPATHを通しておけば終わり!
> node --version
v8.9.1
バージョン v8.9.1 ←おい
準備(配信環境)
OBS v24系(←これ大事。らしいです)に obs-websocketを導入します。
インストーラーは、Releases のページからダウンロードしましょう。
「obs-websocket-4.7.0-Windows-Installer.exe」をダウンロード/実行しました。
シーンのセッティング
まずは背景を設定します。これは静止画でもシャイア・ラブーフさんの動画でもなんでも大丈夫です。

追加された画像を適当に配置した後は、右クリックして「追加」→「テキスト(GDI+)」を選択します。

名前は jimaku としておきましょう。

適当に自分好みのスタイルに設定して、配置を決定します。

開発
「音声認識」と「字幕制御」を分けて開発します。例外処理?知らん。
音声認識
.NET Frameworkの場合、 System.Speech.Recognition 名前空間の
SpeechRecognitionEngine クラスを使用することで追加インストール不要で音声認識できます。
ほぼドキュメントのコピペですが、標準出力に音声認識結果を出力するようにしましょう。
using System;
using System.Speech.Recognition;
namespace SpeechToConsole
{
class Program
{
static void Main(string[] args)
{
using (var recognizer = new SpeechRecognitionEngine(new System.Globalization.CultureInfo("ja-JP")))
{
recognizer.LoadGrammar(new DictationGrammar());
recognizer.SpeechRecognized += Recognizer_SpeechRecognized;
recognizer.SetInputToDefaultAudioDevice();
recognizer.RecognizeAsync(RecognizeMode.Multiple);
Console.ReadLine();
}
}
private static void Recognizer_SpeechRecognized(object sender, SpeechRecognizedEventArgs e)
{
Console.WriteLine(e.Result.Text);
}
}
}
Releaseでビルドして、EXEファイルとして実行できるようにしておきましょう。
実行してマイクに向かってしゃべった言葉が認識されてコンソールに出力されればOKです。
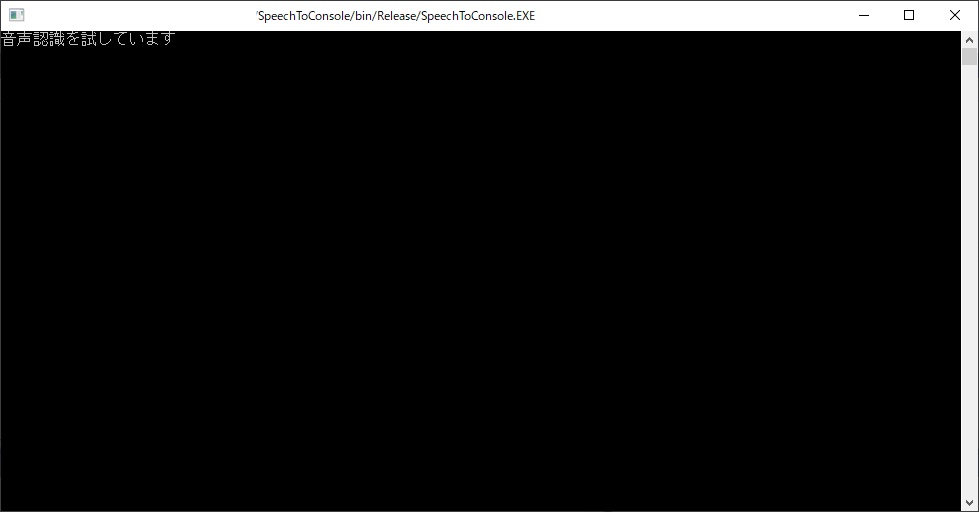
字幕制御
字幕制御は node.js でちゃちゃっとやります。下記コマンドで必要パッケージをインストールして…
mkdir text_to_obs
npm init
npm install obs-websocket-js --save
下記ファイルを index.js として作成します。
const OBSWebSocket = require('obs-websocket-js');
const obs = new OBSWebSocket();
obs.connect({ address: 'localhost:4444' })
.then(() => {
console.log("opened");
});
process.stdin.resume();
process.stdin.setEncoding("utf-8");
process.stdin.on("data", function(chunk) {
obs.sendCallback("SetTextGDIPlusProperties",
{
source: "jimaku",
text: chunk
}, prop => {
console.log(chunk);
});
});
process.stdin.on('end', function() {
obs.disconnect();
});
それが完成したら、先ほどビルドした音声認識EXEファイルを同じフォルダに入れます。
実行
WebSocketの有効化
ここからの設定は非常に危険です。設定内容を理解したうえで自己責任でお願いいたします。
まずはメニューを開きます。
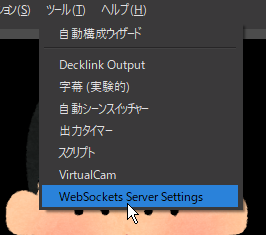
「WebSocketsサーバーを有効にする」にチェックを入れ、
ポート「4444」を選択し、OKを押します。
バーチャルWebカメラの起動
前回記事同様、OBSの内容をWebカメラからの入力として配信するために
VirtualCamを「Start」します
音声認識・字幕制御の起動
先ほどEXEファイルを格納したフォルダでcmdを起動し、下記コマンドを実行します。
chcp 65001 & SpeechToConsole.exe | node index.js
上記コマンドは コードページを UTF-8 に変換し、
SpeechToConsole.exe を実行し、出てくる出力内容を node index.js で起動されるプロセスにパイプしています。
このコマンドを実行して、うまく字幕制御プログラムがOBSと接続できると下記のような通知が出ます。
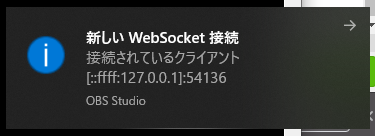
結果
「Zoomに字幕を表示しています」

「字幕のテストだよ」

「字幕なんですけど、ちゃんと音声認識されてるんですかね」

終わりに
Zoomって字幕表示機能あるんですね。
ただ、これは自分の顔に表示されるのが利点で、マイクがミュートになっていても
意思表示できるのが便利です!()
ちなみに先日開催されたZoom飲み会で披露したところ、
音声認識がダメダメすぎてしゃべっている内容の字幕だと認識されませんでした(完)