皆さんは絵を書くのは得意ですか?
僕は絵を書くのはとても苦手です。Twitterで絵師さんの描いた絵を見て、いつも「僕もこんな絵が描けたら楽しいだろうな〜」って思っています。
そんな僕のように絵を書くのが苦手な人でも、絵師さんに負けず劣らずの絵を書く手段があります。
それは「画像生成AI」です!
近年、深層学習モデルを利用した画像生成によって、ハイクオリティな画像を生成できることが話題になっています。
特に、絵の内容をテキストとして入力することで、その内容を描写した画像を生成してくれる「Text-to-Image」は使いやすくてとても有用です。
今回は Text-to-Image の画像生成モデルである Stable Diffusion を利用して画像生成してくれる DiscordBot を作っていきたいと思います!
以前紹介した ChatGPTAPI を利用した DiscordBot のコードを書き換えて作成するので、DiscordBot の作り方がわからない方はぜひ参考にしてみてください↓
1. Stable Diffusion とは?
Text-to-Image の画像生成モデルはいくつも存在します。
例えば DALL-E2 や Midjourney、Stable Diffusion などです。
今回はその中の一つである、 Stable Diffusion を使っていきます。
理由としては、「Diffusers」というモジュールを利用して簡単に Stable Diffusion を使うことができるからです(つまり惰性)。
それでは早速作業に入っていきます。
2. Diffuers のインストール
Stable Diffusion を使えるようにするために Diffuers をインストールします。
Diffusers のインストールは以下のページを参考にしました。
こんな簡単にモデルが使えるようになるなんて素晴らしすぎる。。。
3. 学習済みモデルのダウンロード
次に学習済みモデルをダウンロードします。
そのために、 Hugging Face にログインし、利用規約に同意、さらにアクセストークンの取得を行います。
アクセストークンを取得できればいよいよ Stable Diffusion を使うことができます。
アクセストークン取得までの流れは以下のページを参考にしました
4. BOTの動作を記述するPythonファイルを作成する
DiscordBot.pyという名前のファイルを作り、このファイル内でBOTの動作を記述します。
以下にDiscordBot.pyの記述内容を示します。
!img [描画したい画像の内容]
という形でディスコード上にテキスト送ると、その内容通りに画像を生成して送ってくれるというプログラムになっています。
import discord
from dotenv import load_dotenv
import os
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
# .envファイルから環境変数を読み込む
load_dotenv()
DISCORD_TOKEN = os.getenv('DISCORD_TOKEN') # Discord Botのトークン
MODEL_ID = os.getenv('MODEL_ID') # 学習済みモデルのID
DEVICE = os.getenv('DEVICE') # モデルを実行するデバイスの指定
HAGGINGFACE_TOKEN = os.getenv('HAGGINGFACE_TOKEN') # Hugging Face APIのトークン
# 学習済みモデルを設定し、StableDiffusionPipelineでパイプラインを作成する
pipe = StableDiffusionPipeline.from_pretrained(
MODEL_ID, revision="fp16", torch_dtype=torch.float16, use_auth_token=HAGGINGFACE_TOKEN
)
pipe.to(DEVICE)
# Discord Botを起動するための設定をする
intents = discord.Intents.all()
client = discord.Client(intents=intents)
# Botが起動した時にメッセージを表示する
@client.event
async def on_ready():
print("起動完了")
# ユーザーからメッセージが送信された時の処理を設定する
@client.event
async def on_message(message):
# Bot自身からのメッセージは無視する
if message.author == client.user:
return
# "!img [入力文字列]"という形式のメッセージが送信された場合
elif message.content.startswith('!img'):
prompt = message.content[5:] # ユーザーが入力した文字列を取得する
with autocast(DEVICE):
# パイプラインを実行し、画像を生成する
image = pipe(prompt, guidance_scale=7.5)["images"][0]
image.save("output.png") # 画像をファイルに保存する
with open('output.png', 'rb') as f:
picture = discord.File(f)
# 画像をDiscordに送信する
await message.channel.send(file=picture)
# Discord Botを起動する
client.run(DISCORD_TOKEN)
トークンやIDなどの変数は dotenv を利用して読み込んでいます。
具体的には DiscordBot.py と同じディレクトリに以下のような .env というファイルを作成すればOKです。
DISCORD_TOKEN = "ディスコードのトークン"
MODEL_ID = "CompVis/stable-diffusion-v1-4"
DEVICE = "cuda"
HAGGINGFACE_TOKEN = "Hugging Face のトークン"
この MODEL_ID で Stable Diffusion を指定しているため使えるようになっているということですね。
5. 試しに動かしてみる
では、正しく画像生成できるのか動作確認していきます。
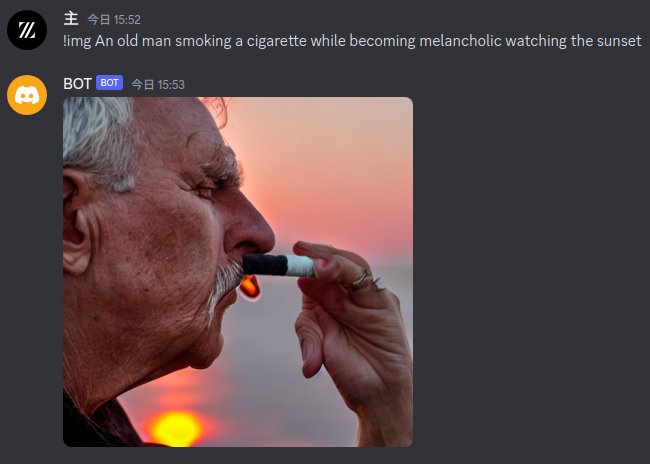
例 1
An old man smoking a cigarette while becoming melancholic watching the sunset
(夕焼けを見ながら黄昏れ、タバコをふかす老人)
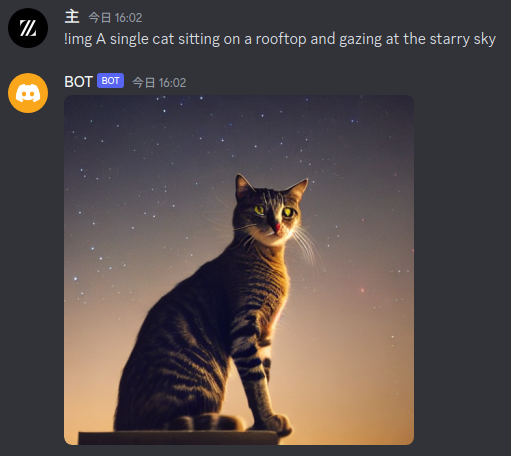
例 2
A single cat sitting on a rooftop and gazing at the starry sky
(屋根に座って星空を眺める一匹の猫)
なかなかいい感じですね!
6. 最後に
今回は Stable Diffusion を使って画像生成できる DiscordBot を作りました。
結構簡単にできてびっくりしました。
画像生成モデルは発想次第で様々なクリエイティブなアプリケーションに化けると思うので、今後の開発にも積極的に取り入れていきたいと思いました。