こんにちは。私は現在はレコメンドに関するデータ分析およびモデル検討などを担当しております。この記事はAMBL株式会社 Advent Calendar 2022の12日目の記事です。
本記事は、他の記事や書籍になっているようなレコメンドの入門内容を、私の経験を元にまとめ直したものになります。そのため、アルゴリズムの実装や先端技術を知りたい方は対象外となります。また、本記事の範囲としては、主に「ユーザの嗜好に合ったアイテムを1つ以上おすすめする」ようなタスクのレコメンドを対象としており、パーソナライズありのレコメンドを想定して用語・概念を整理しています。
なるべく具体的に説明しようとした結果かなり長くなってしまいましたので、必要に応じて読み飛ばしていただければと思います。
0.はじめに
この記事は、「自分が業務で初めてレコメンドを扱うことになったときに、こんな記事があったらな」ということを思い浮かべながら作成しました。そのため、対象者として「データ分析や機械学習の基本手法を理解しているものの、レコメンドに関しては未経験である」という人を想定しており、扱う範囲はレコメンドにおける基礎となる用語・概念の整理にとどめております。レコメンドに関する情報は、入門から先端技術まで、Web記事・著書などが多く執筆されています。例えば神嶌先生のテキスト「推薦システムのアルゴリズム」では、身近な例を用いながら入門的な概要が分かりやすくまとめられております。しかしながら、初学者だった私としては、テキストや教科書を読んでも、似たような用語や概念が上手く整理できなかったり、用語や概念の意味が分かっても実際に手を動かそうとすると具体的なイメージが湧かなかったりといった困難を抱えていたのを覚えております。そのため、より詳細で厳密な定義については他の媒体を参照していただくとして、本記事ではそれらの記事を読み解くために必要な基本的な用語・概念を、具体例を交えつつ整理していきたいと思います。この記事がこれからレコメンドを始める方の一助となれば幸いです。
1.本記事で扱う「レコメンド」について
本記事で説明する「レコメンド」の範囲を定義します。
『推薦システム実践入門』によると、レコメンドシステムは以下の4つに大別されると説明されています。
ユーザの目的は利用するサービスの性質やそのドメインなどによって多岐にわたりますが、ここではJ.Herlockerを参考に次の4つの分類に従って説明します。
・適合アイテム発見
・適合アイテム列挙
・アイテム系列消費
・サービス内回遊
詳細は書籍を参照していただきたいのですが、本記事ではこのうち「適合アイテム発見」や「適合アイテム列挙」、つまり「ユーザの嗜好に合ったアイテムを1つ以上おすすめする」という状況を想定したレコメンドについて説明していきます。例えば、NetflixやAmazonのようなたくさんの商品があるサービスにおける「おすすめリスト」を作成する手法になります。
「おすすめリスト」と一口に言っても、新着順やサービス全体の人気順にまとめただけものや、「一緒に購入されている商品」のようにアイテムどうしの関連性を利用したもの、「あなたへのおすすめ」のように各ユーザ個人の情報を利用したものなど、作成方法は様々です。新着順・人気順など、サービスを利用するユーザ全員の共通の「おすすめリスト」を提示するようなレコメンドを「パーソナライズなしレコメンド」、「一緒に購入されている商品」や「あなたへのおすすめ」など、ユーザごとにパーソナライズされたレコメンドを「パーソナライズありレコメンド」と呼びます。これらはどちらに優劣があるというわけではなく、状況に応じて使い分けることが望ましいです(例えば新着順などは、ニュースサイトなどの新着情報をチェックする要望があるサービスにおいては十分優れたレコメンド方法であることは、感覚的にも分かると思います)。
本記事では、具体的なアルゴリズムにまでは言及しませんが、主にパーソナライズありレコメンドの方を想定して説明しています。機械学習などのアルゴリズムが用いられるのはこちらのレコメンド方法であり、機械学習で作成したモデルでユーザごとに最適化された「おすすめリスト」を作成する、というような問題を解くことが多いです。
2. データについて
レコメンドで扱うデータ(言い換えるなら機械学習モデルや各種アルゴリズムのインプットとなるデータ)について説明します。本記事では、その中でも基本的かつ他のタスクと扱いが異なるテーブルデータを使ったレコメンドを想定し、このセクションでもテーブルデータについて説明します。ただし、機械学習の観点から言うと、レコメンドでは回帰・分類、画像解析、テキスト解析、音声解析、時系列解析など、様々なタスクのモデルが応用されています(例えば、ECサイトにおいて小説のあらすじをテキスト解析して似ている小説をレコメンドしたり、ショッピングサイトにおいてユーザの行動を時系列解析して次にクリックする商品を予測したりなどがあります)。それらについては私もまだまだ勉強中の身ですので、機会があればまとめてみたいと思います。
「テーブルデータ」と言うと、一般的には以下のような形式のデータが該当すると思われます。
| ユーザID | 性別 | 年代 | 勤続年数 | ... | 年収 | |
|---|---|---|---|---|---|---|
| 0 | 001 | 男 | 20代 | 3年 | ... | 350万 |
| 1 | 002 | 女 | 40代 | 15年 | ... | 700万 |
| ... | ... | ... | ... | ... | ... |
「ユーザIDでユニーク」で、「各個人の属性に関する情報」がまとめられているデータを想定しています。例えば「年収を予測するモデルを作成する」などタスクが与えられれば、ユーザ属性(性別・年代・勤続年数)をインプットにした線形回帰モデルを学習することが考えられます。
レコメンドでは、属性に関するデータに加え、ユーザの好き嫌い(嗜好)を反映したデータである「行動履歴(ログ)」も扱います。以下、個別に説明します。
2-1. 行動履歴(ログデータ)
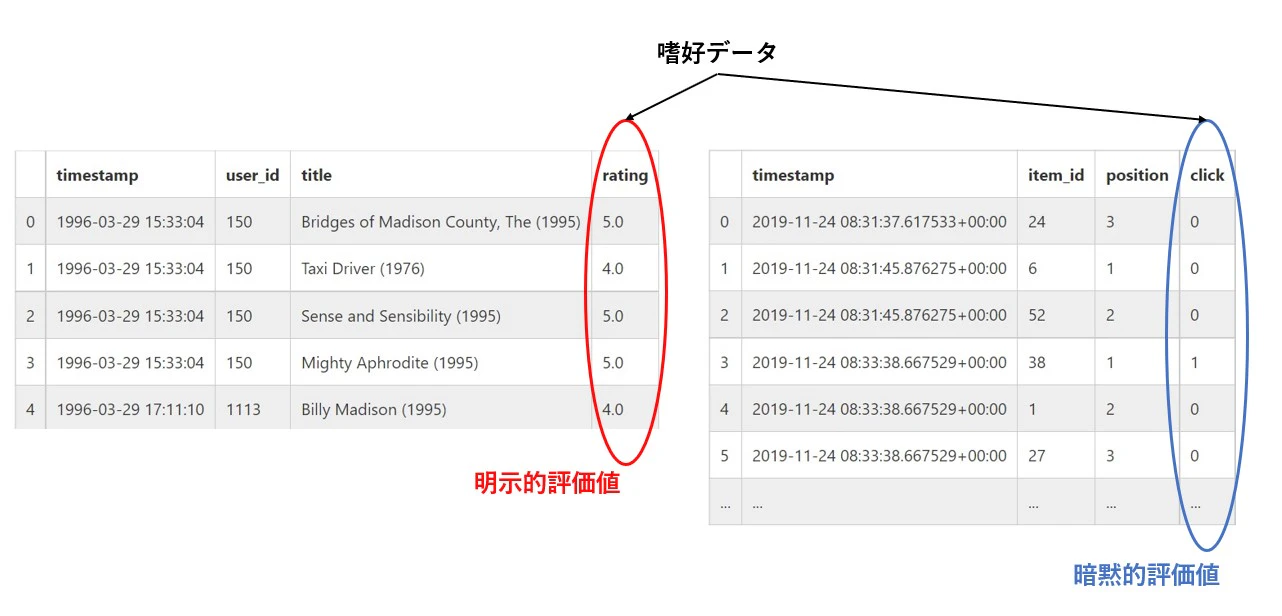
あるサービス内での全ユーザの行動(評価、クリック、視聴、購入など)の履歴データです。以下は「MovieLens」という、映画のレビューに関するオープンデータを私の方で一部抜粋・改変したものになります(MovieLens 10M Datasetを利用しています)。
| timestamp | user_id | title | rating | |
|---|---|---|---|---|
| 0 | 1996-03-29 15:33:04 | 150 | Bridges of Madison County, The (1995) | 5.0 |
| 1 | 1996-03-29 15:33:04 | 150 | Taxi Driver (1976) | 4.0 |
| 2 | 1996-03-29 15:33:04 | 150 | Sense and Sensibility (1995) | 5.0 |
| 3 | 1996-03-29 15:33:04 | 150 | Mighty Aphrodite (1995) | 5.0 |
| 4 | 1996-03-29 17:11:10 | 1113 | Billy Madison (1995) | 4.0 |
| ... | ... | ... | ... | ... |
左から順にレビューした時間(timestamp)、ユーザID(user_id)、レビューを付けた映画のタイトル(title)、映画に着けたレビュー(rating)です。なお、ratingは0.5~5.0の0.5刻みです。
上述した「一般的なテーブルデータ」と違いを考えると、
- ユーザIDでユニークではない
- ユーザに関する情報の他に、映画に関する情報(title)が格納されている
- 映画に関する評価値(rating)が格納されている。
などが挙げられると思います。例えばこのデータから機械学習のモデルを学習して「おすすめリスト」を作成するという場合、どのようなモデルを作成すればよいでしょうか?少なくとも、上述した「一般的なテーブルデータ」に適用するようなユーザ属性をインプットにした線形回帰モデルとは性質が異なることは容易に想像できると思います。
さて、「rating」カラムですが、これはユーザが映画に対しその評価を付けた値になり、ユーザの嗜好を強く反映した情報であると言えます。このように、行動履歴に残っている、各ユーザのアイテム(商品)に対する好き嫌いの情報のことを「嗜好データ」と呼びます。さらに、「rating」カラムのように、ユーザが映画・商品などに対し数値をつけて直接評価したような嗜好データのことを「明示的評価値」と呼びます。レコメンドの目的は「ユーザの嗜好に合ったアイテムをおすすめする」ことですので、この「明示的評価値」を使えば各ユーザの嗜好を分析できそうです。
しかしながら、すべてのサービスでユーザの「明示的評価」を得られるというわけではありません。以下は株式会社ZOZOがOff-Policy-Evaluation1の研究のために公開している、大規模ファッションECサイトZOZOTOWNで収集されたデータ「Open Bandit Dataset」の一部です(こちらから「all.csv」をダウンロードして利用しています)。説明のため任意の改変を加えています。
| timestamp | user_id | item_id | position | click | |
|---|---|---|---|---|---|
| 0 | 2019-11-24 08:31:37.617533+00:00 | 001 | 24 | 3 | 0 |
| 1 | 2019-11-24 08:31:45.876275+00:00 | 002 | 6 | 1 | 0 |
| 2 | 2019-11-24 08:31:45.876275+00:00 | 002 | 52 | 2 | 0 |
| 3 | 2019-11-24 08:33:38.667529+00:00 | 003 | 38 | 1 | 1 |
| 4 | 2019-11-24 08:33:38.667529+00:00 | 003 | 1 | 2 | 0 |
| 5 | 2019-11-24 08:33:38.667529+00:00 | 003 | 27 | 3 | 0 |
| ... | ... | ... | ... | ... |
左から順にレビューした時間(timestamp)、ユーザのID(筆者が任意に付与しました)、商品のID(item_id)、その商品のおすすめ順位(position)、その商品がクリックされたかどうか(click)です。
解釈してみると、例えば「ユーザ003が2019年11月24日の午前8時33分にアクセスしたところ、商品38、商品1、商品27が同時に表示(レコメンド)されたため、そのうち商品38のみをクリックした」ということになります(重ねて申し上げますが、上記のログは私の方で解釈のために改変したものであり、実際のシステムやデータとは異なりますのでご注意ください)。
重要なのが「rating」カラムの代わりに「click」カラムがあるということです。zozotownでは、いくつかの商品がおすすめとして表示されていて、クリックすると商品の詳細情報が確認できます。言い換えると、クリックしたということは(操作ミスでなければ)その商品の詳細を確認したかったということであり、その商品に興味があると言えます。このように、「嗜好データ」のうち、「ユーザが何かしらのアクションを起こしたこと」をユーザの興味関心(=嗜好)として解釈した値を「暗黙的評価値」と呼びます。「暗黙的評価値」は、クリックの有無の他にも「動画の視聴時間(長いほど興味あり)」などが挙げられます。
暗黙的評価値を扱う際には、「不支持(興味がない)」と「未評価(認識されていない)」が区別できないことに注意する必要があります。上記の例で考えると、ユーザ1は、商品1・商品27について「興味がなかったからクリックしなかった」のではなく単に「目に入らなかったからクリックしなかった」という可能性は捨てきれません。3つ程度ならその可能性は低いですが、例えばECサイトで100個の商品がレコメンドされていても、目を通すのは多くても上位10件程度で、すべて目を通す人は稀かと思われます。未評価だった商品を不支持として扱って分析を進めると、バイアスが生じる可能性があります。
2-2. メタデータ
ユーザおよびアイテム(映画、商品)に紐づいたデータのことです(「メタデータ」という単語はレコメンド用語としてあまり用いられませんが、説明のためここではそう呼ばせてください)。以下、アイテムについてのメタデータとユーザについてのメタデータについて説明します。
2-2-1. アイテム特徴(アイテムメタ)
商品や動画のジャンルや作者・著者、金額などの情報2のことです。これらのデータを「アイテム特徴」と呼びます。すでにお気づきかとは思いますが、レコメンドにおいては商品や動画などのレコメンド対象物のことを一般的に「アイテム」と呼びます。
以下はMovieLensを一部改変し、映画についてのメタデータ(アイテム特徴)を作成したものになります。
| title | genre | tag | |
|---|---|---|---|
| 0 | Bridges of Madison County, The (1995) | ['Drama', 'Romance'] | ['based on a book', 'book', 'heartwarming', 'd… |
| 1 | Taxi Driver (1976) | ['Crime', 'Drama', 'Thriller'] | ['cameo:martin scorsese', 'cinematographer:mic... |
| 2 | Sense and Sensibility (1995) | ['Comedy', 'Drama', 'Romance'] | ['ang lee', 'jane austen', 'british', 'jane au... |
| 3 | Mighty Aphrodite (1995) | ['Comedy', 'Drama', 'Romance'] | ['woody allen', 'woody allen', 'adoption', 'pr... |
| 4 | Billy Madison (1995) | ['Comedy'] | ['school', 'funniest movies', 'seen more than ... |
| ... | ... | ... | ... |
左から順に、映画のタイトル(title)、その映画のジャンル(genre)、その映画につけられたタグ(tag)です。作品ごとにジャンルとタグがまとめられたテーブルになります。「title」カラムはより一般的にはアイテムIDであり、アイテム特徴はアイテムIDでユニークなテーブルとなります。
2-2-2. ユーザメタ
ユーザに関する情報のことです。さらに以下2つに分類できます。
1) ユーザ属性
ユーザの性別、年齢、居住地、年収などの情報のことです。本セクションの冒頭で触れた「一般的なテーブルデータ」に登場していたようなデータに最も近いデータと言えます。当然、ユーザIDで一意なデータです。
| ユーザID | 性別 | 年代 | 居住地 | 年収 | |
|---|---|---|---|---|---|
| 0 | 001 | 男 | 20代 | 神奈川 | 350万 |
| 1 | 002 | 女 | 40代 | 東京 | 700万 |
| 2 | 003 | 女 | 10代 | 北海道 | 0万 |
| 3 | ... | ... | ... | ... |
2) ユーザプロファイル(利用者プロファイル)
ユーザの「好み」についてまとめたメタデータのことを、「ユーザプロファイル」と呼びます。ユーザ属性と同様に、ユーザIDで一意のデータです。レコメンドにおいて「ユーザについてのメタデータ」としてよく出てくるのはこちらのデータになります。言葉で説明しても分かりにくいと思いますので、以下具体例を確認してください。
| user_id | genre | tag | |
|---|---|---|---|
| 0 | 001 | Comedy | british |
| 1 | 002 | Drama | ang lee |
| 2 | 003 | Crime | based on book |
| ... | ... | ... | ... |
MovieLensになぞらえて、ユーザの好みのジャンル・タグをまとめたユーザプロファイルを作成してみました。ユーザについてのメタデータですが、中身はアイテムに関する情報(ジャンルなど)であることに注意してください。例えば、ユーザ001についてみてみると、彼はジャンルは「Comedy」で、「british」のタグが付いた映画を好むということが分かります。セクション2-1-1で提示したアイテム特徴と照らし合わせると、ユーザ001には2行目「Sense and Sensibility (1995)」をレコメンドすれば気に入ってくれそうに思われますね。
上記のようなデータは、例えばユーザが初めてそのサービスを利用する際に好きなジャンルを入力してもらうことで作成することができます。このようにユーザが直接入力する形で作成したユーザプロファイルを「直接指定型」のユーザプロファイルと呼びます。ユーザに直接指定してもらう方法は正確なデータが獲得できる一方で、ユーザに負担を強いるため獲得できるデータに制限があります。
これに対し、「間接指定型」という、行動履歴からユーザプロファイルを作成する方法もあります。例えば、行動履歴の中で最も視聴している映画のジャンルは、そのユーザの好みのジャンルと言えそうです。以下はMovieLensの行動履歴をユーザごとに集計し、最も多く登場したジャンルとタグをそのユーザの好みとして定義した、間接指定型のユーザプロファイルです。
| user_id | genre | tag | |
|---|---|---|---|
| 0 | 1 | Comedy(11) | disney(50) |
| 1 | 10 | Drama(102) | oscar (best picture)(85) |
| 2 | 11 | Action(30) | sci-fi(115) |
| 3 | 12 | Drama(26) | brad pitt(28) |
| 4 | 13 | Comedy(61) | classic(87) |
| ... | ... | ... | ... |
「genre」カラムおよび「tag」カラムにおけるかっこ内の数値は登場回数です。
なお、このデータは行動履歴を用いていますが、ユーザを軸に集計することでメタデータの区分になっていることに注意してください。
3.タスクと評価
機械学習で「パーソナライズあり」のレコメンド(つまり、個人個人に最適化されたレコメンド)を実施するとき、どのようなタスクを解き、どのような指標で評価するのかを整理したいと思います。ここでいきなり機械学習について述べると先入観が生まれてしまうかもしれませんが、「パーソナライズあり」レコメンドにおいても、「おすすめリスト」を作る方法は何も機械学習でモデルを作成するだけではありません。「アソシエーションルール」というアイテムの共起に着目する手法や、セクション4で後述する「類似度」を元にした手法などがあります。本記事は「機械学習にある程度知見がある人がレコメンドに初めて取り組む」という想定で書いている都合上、機械学習モデルから説明した方が分かりやすいと考え、この構成をとっています。なお、このセクションで触れる内容はセクション4の分類でいうと「ユーザ間型協調フィルタリング」に該当します。
3-1.タスク
機械学習と聞いて誰もが思い浮かべる基本的なタスクに、回帰と分類があると思われます。例えば、「MovieLens」において、「各ユーザがある映画に付ける評価値(rating)を予測する」というタスクなら、回帰問題で解けそうです。また、「Open Bandit Dataset」において「各ユーザにアイテム1をおすすめしたらクリックしてくれるか?」というタスクなら、二値分類問題として解けると思います。
しかしながら、本記事で扱っている「適合アイテム発見」や「適合アイテム列挙」において、最終的に得たい出力は「おすすめリスト」になります。簡単に言えば以下のようなデータを最終的な出力として求められている訳です。
| ユーザ | おすすめNo.1 | おすすめNo.2 | おすすめNo.3 | おすすめNo.4 | おすすめNo.5 |
|---|---|---|---|---|---|
| Aさん | アイテム1 | アイテム2 | アイテム3 | アイテム4 | アイテム5 |
| Bさん | アイテム3 | アイテム1 | アイテム5 | アイテム2 | アイテム4 |
| ... | ... | ... | ... | ... | ... |
各ユーザごとアイテムを5つレコメンドする場合を想定しています。システム上では、このテーブルを保持しておき、例えばAさんがログインしたら「アイテム1」、「アイテム2」、「アイテム3」、...という順に表示します。
このテーブルで重要なのは「ユーザごと」に「複数のアイテム」を「順位を付けて」保持しているという点です。この問題を仮に回帰・分類で解く場合を想定し、具体的な方法を検討してみます。
なお、以下で説明している方法は無理やり回帰・分類に当てはめたやり方であり、かつ問題設定としてもあまりよくないため、実際に以下のようなモデルを適用することは少ないと思います。しかしながら、一般的な機械学習との違いを知る上では有用な考え方であると思いますので、ここまでの説明で具体的な方法が思い浮かんでいない方は目を通してみてください。
1)回帰で解く場合
「MovieLens」のように、明示的な評価値が付与されていれば、回帰を応用して「おすすめリスト」を作成することができます。以下のテーブルは、「MovieLens」の「user_id」、「title」、「genre」、「rating」の一部を抜き出し、さらに私の方で任意に性別と年代を追加したテーブルです。
| user_id | sex | age | title | genre | rating | |
|---|---|---|---|---|---|---|
| 0 | 150 | male | 40 | Bridges of Madison County, The (1995) | ['Drama', 'Romance'] | 5.0 |
| 1 | 150 | male | 40 | Taxi Driver (1976) | ['Crime', 'Drama', 'Thriller'] | 4.0 |
| 2 | 150 | male | 40 | Sense and Sensibility (1995) | ['Comedy', 'Drama', 'Romance'] | 5.0 |
| 3 | 150 | male | 40 | Mighty Aphrodite (1995) | ['Comedy', 'Drama', 'Romance'] | 5.0 |
| 4 | 1113 | female | 30 | Billy Madison (1995) | ['Comedy'] | 4.0 |
| … | … | … | … | … |
こう見ると、「user_id」では一意ではないですが、「user_id」と「title」をキーとすれば、各レコードで一意のテーブルとみなせそうです(もちろん、1人が複数回同じ映画を評価できるシステムである場合は、この限りではありません)。
| user_id x title | sex | age | genre | rating | |
|---|---|---|---|---|---|
| 150 x Bridges of Madison County, The (1995) | male | 40 | ['Drama', 'Romance'] | 5.0 | |
| 150 x Taxi Driver (1976) | male | 40 | ['Crime', 'Drama', 'Thriller'] | 4.0 | |
| 150 x Sense and Sensibility (1995) | male | 40 | ['Comedy', 'Drama', 'Romance'] | 5.0 | |
| 150 x Mighty Aphrodite (1995) | male | 40 | ['Comedy', 'Drama', 'Romance'] | 5.0 | |
| 1113 x Billy Madison (1995) | female | 30 | ['Comedy'] | 4.0 | |
| … | … | … | … | … |
このように見ることで、「sex」、「age」、「genre」を説明変数(特徴量)、「rating」を被説明変数(正解データ)とした教師あり学習のモデルを作成することで、未知の「user_id x title」に対しても評価値を予測することができます。
学習・予測の結果、以下のような予測値を得たとします。
| user_id x title | predicted | |
|---|---|---|
| 150 x Bridges of Madison County, The (1995) | 4.98 | |
| 150 x Taxi Driver (1976) | 4.11 | |
| 150 x Sense and Sensibility (1995) | 4.72 | |
| 150 x Mighty Aphrodite (1995) | 4.11 | |
| 150 x Billy Madison (1995) | 3.99 | |
| 150 x Ballad of Narayama (Narayama Bushiko) (1958) | 3.85 | |
| 150 x Madagascar: Escape 2 Africa (2008) | 2.56 | |
| 150 x Bolt (2008) | 3.67 | |
| ... | ... |
「予測値が高い=その映画を高評価する可能性が高い」と言えるため、予測値が高い順に並べた作品リストを「おすすめリスト」とすることができます。上記のテーブルで考えると、すでに視聴済みの映画を除き「Billy Madison (1995)、Ballad of Narayama (Narayama Bushiko) (1958)、Bolt (2008)、Madagascar: Escape 2 Africa、...」としたものが、ユーザ150に対するおすすめリストとなります。
2)分類で解く場合
「Open Bandit Dataset」のように、正解となるデータが(0,1)の場合は、分類モデルを検討するのが自然かと思われます。回帰の時と同様に、ユーザID×アイテムIDで一意のテーブルとみなし、クリックしたか否かを正解データとしてモデルを学習させることができます。以下、セクション2-1と同様に「Open Bandit Dataset」を任意に改変し、任意に性別と年代を追加したテーブルになります。
| user_id x item_id | sex | age | position | click | |
|---|---|---|---|---|---|
| 001 x 24 | female | 20 | 3 | 0 | |
| 002 x 6 | female | 40 | 1 | 0 | |
| 002 x 52 | male | 10 | 2 | 0 | |
| 003 x 38 | female | 20 | 1 | 1 | |
| 003 x 1 | male | 40 | 2 | 0 | |
| 003 x 27 | male | 30 | 3 | 0 | |
| ... | ... | ... | ... | ... |
例えば、softmax関数を使った多クラス分類モデルを作成できることが分かると思います。
想定される予測結果は以下のようになります。
| user_id xitem_id | predicted | |
|---|---|---|
| 001 x 24 | 0.09 | |
| 001 x 6 | 0.10 | |
| 001 x 52 | 0.28 | |
| 001 x 38 | 0.15 | |
| 001 x 1 | 0.07 | |
| 001 x 27 | 0.14 | |
| ... | ... |
上記のテーブルの予測値は「クリックする確率」なので、回帰の時と同様に値が高い順にアイテムIDを並べればおすすめリストが出来上がります。
分類問題として解く場合には、1点注意すべき点があります。「正解が複数あるか否か」です。上記の例だとユーザ001に対して「クリックされたアイテム」が1つしかないように見えますが、数日間のログが溜まっていることを考えると、正解となる「クリックされたアイテム」が同時に複数実現する状態が自然です。この場合は「マルチラベル分類」という問題を扱う方が適切と言えます。マルチラベル分類については本記事の範囲外ですので、こちらの記事などを参照ください。
なお、純粋な回帰・分類で解くやり方は適切ではない旨は冒頭にも述べた通りですが、こと分類問題に関しては、対象となるアイテム数が莫大(1,000など)である場合にも適さないことは容易に想像できると思います(事前に別の手法でレコメンド対象アイテムを絞るなども一般的ですが、そうであっても純粋な分類問題としてレコメンドモデルを学習することは稀であると思われます)。ここでは詳細は省きますが、「ランキング学習」という方法で目的関数を調整することで、LightGBMなどの回帰・分類のモデルをレコメンドに適するように学習させる方法も確立されています。
3-2.評価
モデルを学習させるからには、そのモデルの評価を行う必要があります。一般的な機械学習においてはMSEやクロスエントロピーなどが挙げられますが、これらの評価値をレコメンドのタスクにも適用できるでしょうか?
結論から言うと可能ではありますが、より適した評価指標が存在します。前セクションの「MovieLens」を回帰問題として解いた場合を考えれば、「user_id x title」のレコードごとに予測評価と実際の評価値の差を見れば、MSEなどを算出できます。しかしながら、本記事で扱っているようなレコメンドににおいては、正確に評価値を予測することよりも「レコメンドしたアイテムをより多く受け入れてもらえる」ことの方が重視されることが多いです。
以下、セクション3-1で示したMovieLensのユーザ150に対する「おすすめリスト」をテーブル形式にまとめなおしてみます。
| user_id | order | recommended | watch or not | |
|---|---|---|---|---|
| 150 | 1 | Billy Madison (1995) | 0 | |
| 150 | 2 | Ballad of Narayama (Narayama Bushiko) (1958) | 1 | |
| 150 | 3 | Madagascar: Escape 2 Africa (2008) | 0 | |
| 150 | 4 | Bolt (2008) | 0 | |
| ... | ... | ... | ... |
「order」はおすすめ順、「recommended」はその順位でレコメンドするアイテムを表しています。「watch or not」は実際にユーザ150がその映画を見たか否かを表しており、ここで新たに追加しました。上記のテーブルに従って上位4をレコメンドしたとすると、1/4しか当てられなかったことになります。4つすべてを「True」として予測したと考えると、Precisionは0.25になります。
ここで、仮に「おすすめリスト」が以下のようだった場合を考えます。
| user_id | order | recommended | watch or not | |
|---|---|---|---|---|
| 150 | 1 | Ballad of Narayama (Narayama Bushiko) (1958) | 1 | |
| 150 | 2 | Billy Madison (1995) | 0 | |
| 150 | 3 | Madagascar: Escape 2 Africa (2008) | 0 | |
| 150 | 4 | Bolt (2008) | 0 | |
| ... | ... | ... | ... |
この「おすすめリスト」と元の「おすすめリスト」は、どちらが良い「おすすめリスト」と言えるでしょうか?Precisionで言えばどちらも0.25です。しかし、元のリストは2番目におすすめしたアイテムが実際に視聴されているのに対し、上記では1番目におすすめしたアイテムが実際に視聴されているため、上記の方が良いレコメンドと言えます。
このように、レコメンドを評価する際には、「いくつのアイテムを当てられたか」の他に「何番目のレコメンドを当てられたか」を加味します。代表的な指標として「Average Precision@K(AP@K)」というものがあり、今回の例でこれを計算すると、元の「おすすめリスト」が0.5、上記の「おすすめリスト」が1.0となり、上記の方が良いレコメンドであるという評価になります。他にも「MAP@K」や「MRR@K」、「nDCG@K」など指標がありますが、これらの詳細を説明した記事はすでに多数ありますので、気になる方は検索してみてください。
4.レコメンドに特有な手法について
セクション3の冒頭で説明した通り、レコメンドにおいて最終的に得たい出力は「おすすめリスト」であり、その作成方法は何も機械学習だけではありません。このセクションでは、レコメンドに特有な「類似度」を元にした手法について整理します。ただし、神嶌先生のテキストでも触れらていますが、これらの手法は明確に線引きできない部分もあり、本記事で紹介する内容も、あくまで一例であるということはご認識ください。
各手法については、個人的に以下の軸で理解すると整理がつくと考えております。
| アイテム間の類似度を使う | ユーザ間の類似度を使う | |
|---|---|---|
| メタデータがメイン | 内容ベースフィルタリング | - |
| 行動履歴がメイン | 協調フィルタリング(アイテム間) | 協調フィルタリング(ユーザ間) |
レコメンドの手法は「メタデータ(アイテムに関するデータ)」と「行動履歴」をのどちらをメインで利用するのかによって、「内容ベースフィルタリング」と「協調フィルタリング」に大別されます。さらに、「アイテム間の類似度」を用いるのか「ユーザ間の類似度」を用いるのかも意識的に区別しておくと、他の書籍などを読む際に整理がつくと思います。
4-1. 内容ベースフィルタリング
「ユーザプロファイルと類似するアイテム特徴を持つアイテムをレコメンドする」という手法を「内容ベースフィルタリング」と呼びます。「ユーザプロファイル」は「ユーザ好みのアイテム像」と捉えることができ、そのアイテム像と実際のアイテムの類似度を計算し、類似度が高い順にアイテムを並べることで「おすすめリスト」を作成できます。
セクション2-2で例示したような、「ユーザの好みのジャンルに合致するジャンルの作品をおすすめする」というレコメンド方法も内容ベースフィルタリングと言えます。より精緻な類似度を計算したい場合は、例えばアイテム特徴とユーザプロファイルの「genre」カラムをOne-Hot化し、ベクトルの類似度を求めるというやり方も考えられます。
<アイテム特徴>
| title | Drama | Romance | Crime | Thiller | ... | |
|---|---|---|---|---|---|---|
| 0 | Bridges of Madison County, The (1995) | 1 | 1 | 0 | 0 | ... |
| 1 | Taxi Driver (1976) | 1 | 0 | 1 | 1 | ... |
| 2 | Sense and Sensibility (1995) | 1 | 1 | 0 | 0 | ... |
| ... | ... | ... | ... | ... | ... | ... |
<ユーザプロファイル>
| user_id | Drama | Romance | Crime | Thiller | ... | |
|---|---|---|---|---|---|---|
| 0 | 001 | 0 | 0 | 0 | 0 | ... |
| 1 | 002 | 1 | 0 | 0 | 0 | ... |
| 2 | 003 | 0 | 0 | 1 | 0 | ... |
| ... | ... | ... | ... | ... | ... | ... |
内容ベースフィルタリングの主なメリットは、新規サービスのようなログ(行動履歴)が溜まっていない場合にも適用できるという点です。サービス初回利用時に自分の好みを登録してユーザプロファイルが作成されれば、あとはデータベース上のアイテム特徴との類似度計算だけでレコメンドが実現します。
ちなみに、例では「直接指定型」のユーザプロファイルを用いていますが、「間接指定型」であっても内容ベースフィルタリングに分類されます(神嶌先生のスライドによると、直接指定型のユーザプロファイルを使ったものを特に「知識ベースフィルタリング」と呼ぶ場合もあるようです)。
4-2.協調フィルタリング
「行動履歴を元にユーザ・アイテムの類似度を求める」手法を「協調フィルタリング」と呼びます。行動履歴が蓄積されないと使えないというデメリットはありますが、行動履歴の裏にあるユーザやアイテムの微妙な関係性を捉えることができると言われており、データがそろえば内容ベースフィルタリングよりも正確なレコメンドができるとされています。
この手法では、「評価値行列」という形式のデータを利用することが多いです。以下は「MovieLens」を改変して評価値行列としたテーブルになります。
| user_id/movie_id | 1 | 2 | 3 | 4 | 5 | ... |
|---|---|---|---|---|---|---|
| 1 | NaN | NaN | NaN | NaN | NaN | ... |
| 10 | NaN | NaN | NaN | 3.0 | NaN | ... |
| 11 | NaN | NaN | NaN | NaN | NaN | ... |
| 12 | NaN | NaN | NaN | NaN | 3.0 | ... |
| 13 | NaN | 3.0 | NaN | NaN | NaN | ... |
| ... | ... | ... | ... | ... | ... | ... |
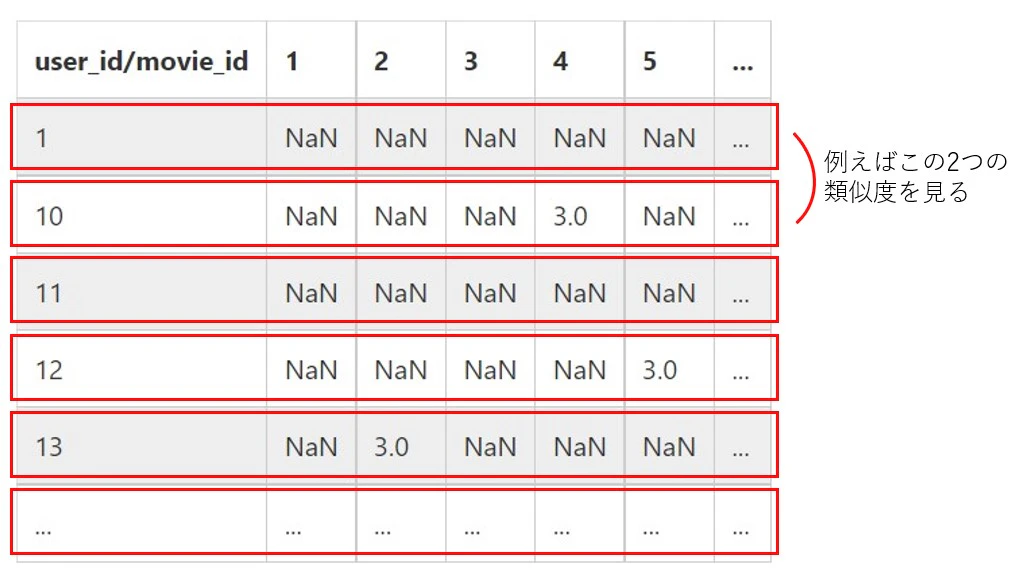
行がユーザID、列がmovie_id(これまでのtitle)です。各ユーザごとにどの作品に何点の評価を付けたかを行列形式にまとめたものになります。値がNaNのセルは、そのユーザがその作品を評価していないということを表しています。上記のテーブルを見ても分かる通り、1ユーザが評価したことのある作品は全体のわずか一部であるため、評価値行列はスパースな行列になることがほとんどです。
また、以下は「Open Bandit Dataset」を改変して評価値行列としたテーブルです。
| user_id/item_id | 0 | 1 | 2 | 8 | 9 | ... |
|---|---|---|---|---|---|---|
| 0 | NaN | NaN | NaN | NaN | 1 | ... |
| 1 | NaN | NaN | NaN | NaN | NaN | ... |
| 2 | NaN | 1 | NaN | NaN | NaN | ... |
| 3 | NaN | NaN | NaN | NaN | NaN | ... |
| 4 | NaN | NaN | NaN | 2 | NaN | ... |
| ... | ... | ... | ... | ... | ... | ... |
各セルにはクリックした回数が記録されています。もちろん、単に「クリックしたか否か」の(0,1)の値を持った評価値行列とすることも可能です。
協調フィルタリングは、上記のような評価値行列をユーザ間(行)で見るかアイテム間(列)で見るかによっても手法を分類できます。以下、それぞれ説明します。
1)ユーザ間型レコメンド
「行動履歴から類似ユーザを特定し、類似ユーザが好んでいるアイテムをおすすめする」という手法です。「他の人はこんな商品も買っています」というタイプのレコメンドはおそらくこの手法に基づいたレコメンドだと思われます。評価値行列から考えると、行列を行ベクトルごとに捉えて分析します。
具体的なレコメンド方法について考えてみます。上記の例だと見えている範囲にNaNが多すぎるので、以下にユーザが5人、アイテムが5個の場合のダミーデータを定義してみます。
| user_id/movie_id | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 1 | 0.0 | 4.0 | 4.5 | NaN | NaN |
| 2 | 3.5 | 2.0 | 5.0 | 2.5 | 5.0 |
| 3 | 2.5 | 4.0 | 0.5 | 2.5 | 4.0 |
| 4 | 1.0 | 3.5 | 2.5 | 3.5 | 2.5 |
| 5 | 4.0 | 4.5 | 0.5 | 1.5 | 3.0 |
ユーザ1は映画4と映画5を見たことがないので、どちらの映画をレコメンドすべきかを考えてみましょう。まずは、ユーザ間の類似度を計算します。全員にそろっている映画1、映画2、映画3の情報を使って各ユーザとユーザ1の相関係数をそれぞれ求めてみると、
- 1:2 = 0.101
- 1:3 = -0.183
- 1:4 = 0.873
- 1:5 = -0.488
となりました。次に、類似ユーザの映画4、映画5に対する平均評価値を求めてみます。相関係数が0より大きいユーザ2、ユーザ4を類似ユーザとし、この2人の映画4、映画5の平均評価値を求めてみると、映画4が3.00、映画5が3.25となります。つまり、類似ユーザたちがより好むのが映画5であり、ユーザ1には映画4より映画5をレコメンドするべき、という結論になります。
今回の例では1つしかレコメンドしていませんが、「おすすめリスト」を作る場合は、レコメンド対象ユーザの未評価作品について、全類似ユーザの平均評価値を算出し、平均評価値が高い順におすすめリストを作成するなどの方法が考えられます。また、評価値行列の中身が「クリックした回数」などの場合は、商品ごとに類似ユーザたちのクリック回数を集計し、回数が多い順にレコメンドするなどが考えられます。
このような手法は一般的に「メモリベース法」と呼ばれる手法に該当します。オンメモリの数値計算でレコメンドができる手法になります。これに対し、機械学習モデルを利用する手法を「モデルベース法」と呼びます。評価値行列のNaNを機械学習で予測する代表的な手法にMatrix Factorizationというものがあります。手法の詳細は別の記事しようと思っています3が、気になる方は検索してみてください。また評価値行列を使っていませんが、セクション3でやった回帰や分類もこれに該当します。明示的に類似度を計算していないにしろ、一般的な機械学習の思想も「ユーザ間の類似性を元に個人の特徴を捉える」というものなので、ユーザ間型の協調フィルタリングと言えます。
2)アイテム間型レコメンド
「行動履歴から類似アイテムを特定し、ユーザが好んでいるアイテムと類似するアイテムをおすすめする」という手法です。アイテムの類似度に基づいている点では内容ベースフィルタリングに似ていますが、内容ベースフィルタリングがアイテム特徴(つまり、アイテムの内容)の類似度を利用しているに対し、アイテム間型の協調フィルタリングでは「好まれ方」の類似度を利用します。評価値行列から考えると、行列を列ベクトルごとに捉えて分析します。
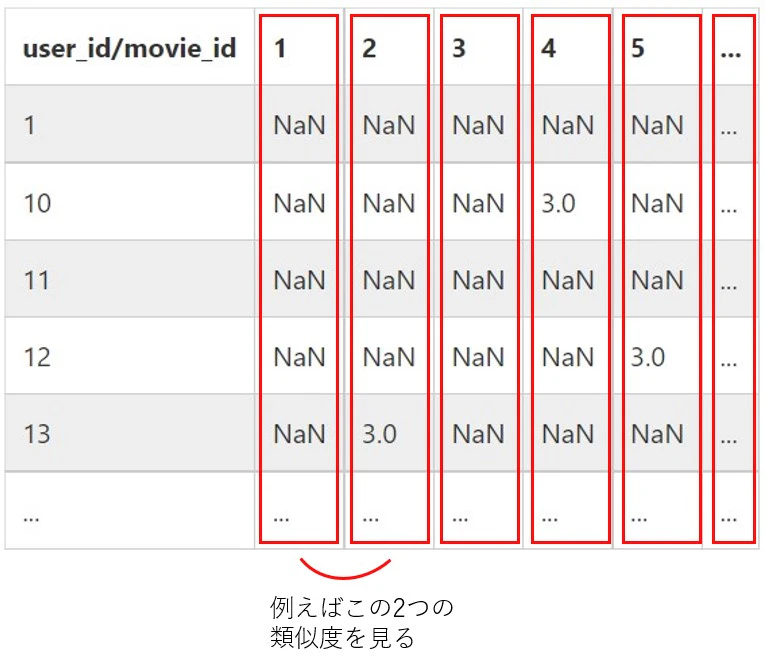
このように見ることで、「どのユーザに好まれるか」が似ているアイテムを「類似アイテム」として定義することができます。
アイテム間の類似度の計算方法は、ユーザ間型メモリベース法4の類似度計算とほぼ同じです。アイテムごとに相関係数などを算出して類似度を求めます。大きく異なる点は「レコメンドされるタイミング」です。アイテム間型の協調フィルタリングでは、多くの場合「最後に行動(視聴、クリック)した、または現在選択中のアイテムと類似するアイテムをレコメンドする」という場合に活用されます。「この商品に類似した商品一覧」などのレコメンド方法の中には、ユーザ間型の協調フィルタリングが使われている例もあると思われます。また、このようなアイテムに紐づくレコメンド方法であるため、「ユーザ個人個人に紐づいたおすすめリストを作る」というレコメンドがしづらいという点も、他の手法との違いになります。
5.終わりに
レコメンドにおける基本的な用語・概念を整理しました。かなり長い記事になってしまったので、本来は複数に分けるべきかとも思いましたが、この辺りは一貫して理解すべきだという個人的な思想もあり、1つの記事にまとめさせていただきました。この記事がこれからレコメンド関連の勉強を始める方々の一助となりましたら幸いです。
参考文献
風間正弘・飯塚洸二郎・松村裕也 (2022) 『推薦システム実践入門―――仕事で使える導入ガイド』,オライリー・ジャパン
神嶌敏夫 (2020)「推薦システム」 https://www.kamishima.net/archive/recsys.pdf (2022年12月10日最終閲覧)
――――――― (2016)「推薦システムのアルゴリズム」 https://www.kamishima.net/archive/recsysdoc.pdf (2022年12月10日最終閲覧)
Yuta Saito, Shunsuke Aihara, Megumi Matsutani, and Yusuke Narita (2020), "Large-scale Open Dataset, Pipeline, and Benchmark for Bandit Algorithms", https://arxiv.org/abs/2008.07146
-
語弊を恐れず大まかに述べると、「既存のログデータに対し別のレコメンド手法を適用したらどうなるか?」ということを検証する手法です。オンラインテストを実施したような結果をオフラインで実現できます。詳細はこちらの記事やこちらの書籍を参照してください。 ↩
-
ここでは詳細に触れませんが、画像データや音声データもアイテム特徴に含まれます。例えば、レコメンド対象アイテムが動画であればサムネイル画像を画像解析したデータをアイテム特徴として分析することができます。 ↩
-
「アイテム間型の協調フィルタリングには、モデルベース法はないのか?」という疑問が浮かぶ方もいると思います。私の調べた限りでは、どの記事・著書の説明でも「協調フィルタリングは"メモリベース"と"モデルベース"に大別でき、さらに"メモリベース"は"ユーザ間型メモリベース"と"アイテム間型メモリベース"に分類できる」となっており、モデルベースではユーザ間型とアイテム間型の区別はないように見受けられます。しかし、個人的にはモデルベース法にもユーザ間型とアイテム間型の区別があると考えています。例えば、「Matrix Factrizationを用いてアイテム因子行列を作成し、アイテム間の類似度を求めてレコメンドする」という手法は、Matrix Factorizationというモデルベースの手法でアイテム間類似度を用いたレコメンドを実施していることになると思います。この辺りの議論は素人の私では妥当性が担保できないため、脚注の形で記載させていただきました。 ↩