Java プロジェクトでのテストに、Groovy を使用するとすごく捗りますよね。
Spock まで採用していると、さらに捗りますね。
ただ、これらを使用しても捗らないものもあります。
それがテストデータの管理です。
これについては、みなさんどのようにしているのか、わたし自身も興味のあるところではありますが、ここではヒントになるかもしれない、アプローチのひとつをご紹介したいと思います。
環境
以下のとおり。
- Java 1.8.0_45
- Groovy 2.4.3
- Spock 1.0-groovy-2.4
- DBUnit 2.5.1
Spock の良さ
Spock でのテストがなぜ捗り、快適なのか。
その助けのひとつとなっているのが where: の見通しの良さではないかと感じています。
多くの方が御存知のとおり、where: では、表形式でテストパターンを記述することができます。
以下のように。
@Unroll
@Stepwise
class FizzBuzzSpec extends Specification {
def "FizzBuzz に #number をかけた場合 #result が返る"() {
expect:
def fizzBuzz = new FizzBuzz()
fizzBuzz.fizzBuzz(number) == result
where:
number || result
1 || 1
3 || 'fizz'
5 || 'buzz'
15 || 'fizzbuzz'
6 || 'fizz'
10 || 'buzz'
0 || 'fizzbuzz'
-15 || 'fizzbuzz'
}
}
class FizzBuzz {
def static void main(String[] args) {
def fizzBuzz = new FizzBuzz();
10.upto(100) {
println fizzBuzz.fizzBuzz(it)
}
}
def fizzBuzz(int number) {
return fizz(number) + buzz(number) ?: number
}
def fizz(int number) {
return number % 3 == 0 ? 'fizz' : ''
}
def buzz(int number) {
return number % 5 == 0 ? 'buzz' : ''
}
}
いい感じ。
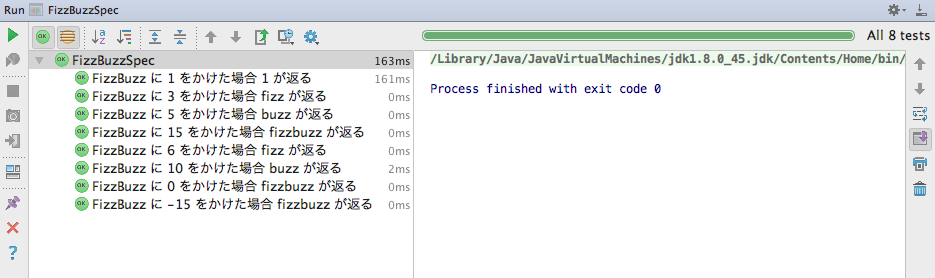
この見通しの良さに助けられて、コードレビューにかかるパワーも抑えられるところが、わたしはとても気に入っています。
テストデータの管理
いよいよ本題です。
DB アクセスを伴ったりするアプリケーションには、テストデータは不可欠です。
とくに複雑な業務プロセスを踏んだり、データパターンが必要になってくる場合には、できる限りテストデータをしっかりと用意したいところ。
ただ、これに対するソリューションは (少なくともわたしの周りでは) 選択肢がそう多くなく、テスト実装の方針を決める際には、いつも頭を悩ませるポイントでもあったりしました。
選択可能なソリューション
どんなソリューションがあったのかというと、具体的には以下のようなものたちでした。
- DB 自体に大量のテストデータを事前に蓄積しておく
- DBUnit + Excel
- DBUnit + XML
- DBUnit + CSV
- テストコード内で POJO などに起こす
どれもあまりしっくりきません。
わたしの中には、テストデータに求める要件があったのです。
ソリューションに求める要件
テストデータを作成、管理するソリューションには以下のようなものが求められました。
- テストは何度回しても必ず同じ結果を返すこと
- テストデータのレビューが可能であること
- できれば、Github などでやりたい
- できれば、同じ画面の中だけで収まるようにしたい - レビュー負荷が大きくなり過ぎないこと
- テストコードと同等、もしくはそれよりやや大きい程度までが許容範囲
- テストデータによって、テストコードが肥大化し過ぎることを避けたい
ソリューションの評価
これらを満たせるかどうかで、先に挙げたソリューションを見てみると。
- DB 自体に大量のテストデータを事前に蓄積しておく
- DB に蓄積されたデータは変化してしまうため、NG
- コードレビューには通せず、インラインコメントなど残せないので、NG
- レビューがそもそもできないので、NG
- DBUnit + Excel
- ファイルに定義されたものを流すことになり、テストデータは不変なため、OK
- コードレビューには通せず、インラインコメントなど残せないので、NG
- 表形式なのでデータは俯瞰しやすいが、別ファイルでケースと紐付かないので、あと一歩。
- DBUnit + XML
- ファイルに定義されたものを流すことになり、テストデータは不変なため、OK
- テキストファイルのため、コードレビューには通せるが別ファイルなので、あと一歩
- 別ファイルになり、また一見してどのケースと紐付いているか判断できないので、NG
- DBUnit + CSV
- ファイルに定義されたものを流すことになり、テストデータは不変なため、OK
- テキストファイルのため、コードレビューには通せるが別ファイルなので、あと一歩
- 表形式なのでデータは俯瞰しやすいが、別ファイルでケースと紐付かないので、あと一歩。
- テストコード内で POJO に起こす
- ファイルに定義されたものを流すことになり、テストデータは不変なため、OK
- テキストファイルであり、テストコードと並んで表現されるため、OK
- テストデータを起こすためのコードにテストコードが煩雑になるため、NG
まとめるとこんな感じ。
| ソリューション | 1 | 2 | 3 |
|---|---|---|---|
| DB 自体に大量のテストデータを事前に蓄積しておく | |||
| DBUnit + Excel | |||
| DBUnit + XML | |||
| DBUnit + CSV | |||
| テストコード内でデータをPOJO に起こす |
候補となったソリューションたちは全滅しました。
惜しいものもありましたが、すべての要件を満たせるものはありません。
顧客が本当に必要だったもの
さて、わたし自身がどのようなものを求めていたのか。
これをヒトコトで表現するなら、「Spock where: のようなテストデータの記述方法」です。
一度、Spock の良さを体感してしまうとやはり、どうにかこうできないのかと思いを馳せてしまうのです。
そこで考えてみました。
端的に、どのような条件を満たせれば、満足するのか。
以下のようなものに集約されるのではないでしょうか。
- データが不変であること
- データがテキストで表現されていること
- データが表形式で俯瞰できること
- データがテストコードと同一ファイル内にあり、テストコード自体を煩雑化しないこと
表形式で俯瞰できること、というのがすこし難しそうです。
ですが、Spock の利用を前提とするならば、そこには Groovy もついてきます。
Groovy がついてくるならば、演算子のオーバーロードにより、データを表のように見せかけることはできるかもしれません。
Groovy x DBUnit で実現
そこで作成してみたのが、こちらになります。
https://github.com/yo1000/dbspock
package com.yo1000.dbspock
/**
* Created by yoichi.kikuchi on 2015/07/13.
*/
class SpockLikeFlatXmlBuilder extends GroovyObjectSupport {
def cols = []
def items = []
SpockLikeFlatXmlBuilder() {
Object.metaClass.or = { x ->
if (!(delegate instanceof List)) {
return [delegate, x]
}
delegate << x
}
}
@Override
Object invokeMethod(String name, Object args) {
if (!(args instanceof Object[]) || args.size() <= 0) {
return super.invokeMethod(name, args)
}
def arg = args[0]
if (name.toLowerCase() == "_cols_") {
cols = arg
return
}
def builder = new StringBuilder(name)
for (def i = 0; i < cols.size(); i++) {
if (arg[i] == null) continue
builder.append(/ ${cols[i]}="${arg[i]}"/)
}
this.items << "<${builder.toString()}/>"
}
String build() {
def builder = new StringBuilder("<dataset>")
for (def item : this.items) {
builder.append(item)
}
builder.append("</dataset>")
return builder.toString()
}
}
dbspock を試してみる
Maven からも参照可能なように、jar を公開してあるので、これを使用して実際の使用感を確認してみます。
<dependencies>
<dependency>
<groupId>com.yo1000</groupId>
<artifactId>dbspock</artifactId>
<version>0.1.2.RELEASE</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>com.yo1000</id>
<name>yo1000 maven repository</name>
<url>http://yo1000.github.io/maven/</url>
</repository>
</repositories>
今回は以下のようなテーブルが用意されているものとします。
TABLE: SHOP
| COLUMN | TYPE | CONSTRAINT |
|---|---|---|
| SHOP_ID | VARCHAR(8) | PRIMARY KEY |
| SHOP_NAME | VARCHAR(80) | NOT NULL |
| SHOP_CREATED | DATE | NOT NULL |
| SHOP_MODIFIED | DATE | NOT NULL |
TABLE: CUSTOMER
| COLUMN | TYPE | CONSTRAINT |
|---|---|---|
| CSTM_ID | VARCHAR(8) | PRIMARY KEY |
| CSTM_NAME | VARCHAR(80) | NOT NULL |
| CSTM_SEX | CHAR(1) | NOT NULL |
| CSTM_CREATED | DATE | NOT NULL |
| CSTM_MODIFIED | DATE | NOT NULL |
これに対するテストデータの挿入コードは以下です。
class RepositorySpec extends Specification {
def "DBSpockTest"() {
setup:
def tester = new DataSourceDatabaseTester(dataSource)
def data = {
_cols_ 'SHOP_ID' | 'SHOP_NAME' | 'SHOP_CREATED' | 'SHOP_MODIFIED'
shop 'SP-1' | 'BURGER KING' | '2015-04-01' | '2015-04-01'
shop 'SP-2' | 'RANDYS DONUTS' | '2015-04-01' | '2015-04-01'
_cols_ 'CSTM_ID' | 'CSTM_NAME' | 'CSTM_SEX' | 'CSTM_CREATED' | 'CSTM_MODIFIED'
customer 'CS1X' | 'Tony Stark' | '1' | '2015-04-01' | '2015-04-01'
customer 'CS2X' | 'PEPPER Potts' | '2' | '2015-04-01' | '2015-04-01'
}
def flatxml = {
data.delegate = new SpockLikeFlatXmlBuilder()
data.call()
data.build()
}
tester.dataSet = new FlatXmlDataSet(new StringReader(flatxml.call()))
tester.onSetup()
expect:
// Something with DB access.
where:
// Setting parameters by Spock.
}
}
いかがでしょうか。
テストデータが表形式で表現されるので、DB にどのようなテストデータが挿入されるのか一目瞭然です。
また、テストコード内に一緒に記述できる一方、テストデータの作成部分が、テストコードの実施部分を汚すこともないので、レビュー負荷も大きくなりません。
テストコード内に記述されているので、指摘があれば、Github などでインラインコメントをつけることもでき、指摘されたデータは、どのテストのものなのかがすぐに把握できます。
Excel などとは異なりテキストなので、差分管理もバッチリです。
実際最近まで関わっていたプロジェクトに、試験導入してみましたが、なかなかの好評でした。
テストデータ管理にお困りの際は、ぜひ一度試してみてはいかがでしょうか。
また、もっとイケてるテストデータ管理の方法を知っているゼ!ってご意見もあれば、ぜひ聞いてみたいです。