ChatGPTは本当に便利ですね。
ChatGPTは会話形式で答えてもらうだけではなく、プログラムから呼び出して使ってもかなり高精度な答えを返してくれることがわかってきました。こうなってくると使い方無限大です。
今回は、CSVにユーザの自由入力で登録された職業の項目を産業別に分類したいと言ったユースケースを想定して検証を進めました。
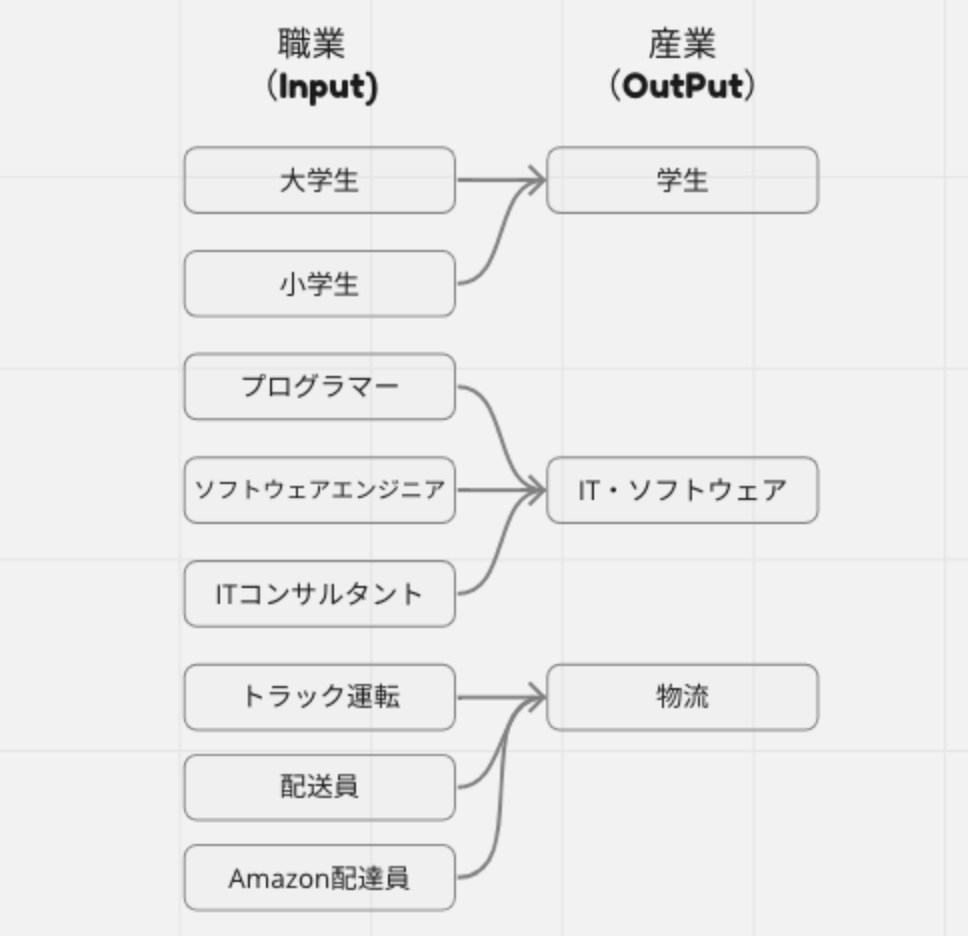
たとえば、アンケートなどで職業などを入力してもらう場合、どうしても表記のふれが出てしまいます。(たとえばSE,ソフトウェアエンジニア,プログラマーとか)
これを防止するために、ユーザ入力時に予めマスタを用意しておき、プルダウンなどで入力してもらうといったことをすればよいですが、世の中の職業は数えきれないほどあり,マスタを準備するのは大変・・・
準備できたとしても、あまり選択肢の数が多いと今度は入力者がそこから選ぶのが不可能になってきてしまいます。
とりあえず情報あればいいや…ということで、自由入力にすると、今度は集計する時に誰かが泣くことになる…
この記事は、こんな時にも誰も泣かなくて済む様なソリューションを編み出したいという想い一心で書きました。
サンプルコード(GoogleColab)
百聞は一見にしかずということで、実際に試したサンプルは以下にありますので、まずは動かしてみることをお勧めします。
このコードを上から順番に動かすと、実際にインターネット上から取得したPDFファイルに関する内容をChatGPTが回答してくれるということを確認することができます。
実際に動かすためには、3番目のダイアログにOpenAIのAPI_KEYを登録する必要があることだけご注意ください。
(以下のコードをコピーして動かせばキーが外部に漏れることはないはずです)
実現していること
中身の解説は後半でしたいと思いますが、このプログラムでは、以下の様なCSVの情報をインプットとして職業欄に入力された情報から産業別分類の項目を追加してもらっています。同時にそれがどの程度正しそうなのか?と言ったスコアも入れる様に指示をしました。
(念の為・・・この情報はChatGPTに作ってもらったダミーの情報です。住所も名前も年齢も全て架空のものです)

その結果、以下の様なアウトプットが得られました。

振り分けられた結果を見てみると、プログラマーやエンジニアは、”IT・ソフトウェア”、パン屋は”食料”に、他にも英語で書かれたfarmingは”農業”に振り分けられており、いずれも期待通りに振り分けてくれていそうです。
これをプログラムでやろうとすると、いろんな文字列の入力を想定してif文いっぱい書いてテストして…とかなり大変(というか無理)だということが、容易に想像つくかと思います。
こんな処理を、上記のプログラムではたかだか数十行の処理で実現できてしまっています・・・驚きですね。
それでは、次章では中身を見ていきたいと思います。
中身の解説
ここからは中身について解説していきます。
レスポンススキーマの作成
まずは、レスポンススキーマと呼ばれる、結果をどの様な形で返して欲しいのか、またそれぞれの項目にはどんな値を入れて欲しいのかを定義します。今回は以下の様に定義します。
response_schema = [
ResponseSchema(name="input_industory", description="これはユーザから入力してもらった産業の情報です"),
ResponseSchema(name="standarized_industry", description="これはあなたユーザから入力してもらった情報が最も近いと感じたindustoryの情報です。 "),
ResponseSchema(name="match_score", description="インプットされた情報がどのくらいindustryに近いかどうかを示す上スコアを1-100で表現する")
]
# どのようにレスポンスをパースするかを指定する
output_parser = StructuredOutputParser.from_response_schemas(response_schema)
各項目のdescription にはそれぞれどんな値を設定して欲しいのかを書きます。今回は日本語で設定していますが、トークンの節約とより正確な結果を出すという観点からも英語で指定することが望ましいです。
ここは余談となりますが、以下の一文を追加するだけで入力情報が英語で書かれていた場合はTrueそうでないならFalseを出力する列を出力結果に追加することができてしまいます。他にもdescriptionに条件を定義しさえすれば、いろんな結果を得られそうです。
ResponseSchema(name="isEnglish", description="to be true if input is written in English")
レスポンススキーマの確認
output_parserの値は以下の様になっており、先頭に"自分で設定した値の手前に英語でこのフォーマットで回答せよ"との指示文が追加されていることがわかります。
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "\`\`\`json" and "\`\`\`":
```json
{
"input_industory": string // これはユーザから入力してもらった産業の情報です
"standarized_industry": string // これはあなたユーザから入力してもらった情報が最も近いと感じたindustoryの情報です。
"match_score": string // インプットされた情報がどのくらいindustryに近いかどうかを示す上スコアを1-100で表現する
}
ChatPromptTemplateの作成
次に、ChatPromptTemplateの作成を行います。これは、ChatGPTに与える具体的な指示をtemplateに書きます。{format_instructions}には、前の手順で作成したアウトプットフォーマットの指示を入れる様に変数を置いておき、最後に設定した変数に値を設定します。
template = """
You will be given a series of industry names from a user.
Find the best corresponding match on the list of standardized names.
The closest match will be the one with the closest semantic meaning. Not just string similarity.
{format_instructions}
Wrap your final output with closed and open brackets (a list of json objects)
input_industry INPUT:
{user_industries}
STANDARDIZED INDUSTRIES:
{standardized_industries}
YOUR RESPONSE:
"""
prompt = ChatPromptTemplate(
messages=[HumanMessagePromptTemplate.from_template(template)],
input_variables=["user_industries", "standardized_industries"],
partial_variables={"format_instructions": format_instructions}
)
産業一覧(マスタ)データの読み込み
その後、統一したい産業名の一覧をファイルから読み込み・・・
# 統一したい産業名のリストを読み込む
df = pd.read_csv('./data/industries.csv')
# 日本語に統一したい場合はIndustryJp, 英語にしたい場合はIndustryEngを使う
standardized_industries = ", ".join(df['IndustryJP'].values)
インプットCSVファイルの読み込み
インプットデータを読み込んで・・・
# インプットデータを読み込み
input_df = pd.read_csv('./data/input-data.csv')
input_df.head(5)
テンプレートに値を設定
テンプレートに読み込んだ値を設定すると準備は完了です。
# テンプレートに値を設定
_input = prompt.format_prompt(user_industries=occu_list, standardized_industries=standardized_industries)
ChatGPTへの指示文の確認
ここまでで作ったテンプレートの中身を見てみると、以下の様になっていました。
ライブラリを使って色々とやっていますが、ライブラリを使ってこう言ったテキストをただ作っているだけと思えばわかりやすいかと思います。やっていることは至極単純なので、自分でこう言ったテキストを作ってChatGPTに渡せば同じ結果は得られるはずですが、先頭に加えられている英語での指示とか、実際に期待通りの結果を返してくれるのかどうかを検証した結果だと思うので、こう言った指示を考えなくてもすむだけでも、このライブラリを利用する価値はあると思います。
You will be given a series of industry names from a user.
Find the best corresponding match on the list of standardized names.
The closest match will be the one with the closest semantic meaning. Not just string similarity.
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "\`\`\`json" and "\`\`\`":
``json
{
"input_industory": string // これはユーザから入力してもらった産業の情報です
"standarized_industry": string // これはあなたユーザから入力してもらった情報が最も近いと感じたindustoryの情報です。
"match_score": string // インプットされた情報がどのくらいindustryに近いかどうかを示す上スコアを1-100で表現する
}
``
Wrap your final output with closed and open brackets (a list of json objects)
input_industry INPUT:
['エンジニア', 'お医者さん', '学生', 'farming', 'twitter media agency', 'ライター', '教師', '弁護士', 'パン屋', 'プログラマー', '大学生', '医者', '果物屋', '農協', 'aviation', 'タイヤ製造', 'マネージャー', 'データサイエンティスト🕶️', ' 医師', ' デザイナー', ' 弁護士', ' 公務員', ' 大学生', ' 看護師', ' 会社員', ' Webデザイナー', ' 学生', ' 美容師', ' システムアーキテクト', ' 大学生', ' 教師', ' フリーランス', ' 銀行員', ' システムエンジニア', ' 経営者', ' 営業職']
STANDARDIZED INDUSTRIES:
コーポレートサービス, 旅行 , 法務, 健康, エンターテインメント, デザイン, アート, マニュファクチャリング, 金融, エネルギー, 航空, 農業, IT・ソフトウェア, 食料, 建設, 広告, 士業, 不動産, 小売, 公務員, 教員, 学生, その他
YOUR RESPONSE:
ChatGPTへのリクエスト送信
ここで、これまでに作った指示をChatGPTに渡して結果を受け取ります。
(データの量などにもよると思いますが、完了までに1分48秒かかりました)
output = chat_model(_input.to_messages())
受信データの成形
ここからはPython側の処理データ成形処理となります。
得られた結果からJSONを取り出し、データフレーム化して、それをinputの表にくっつけます。
# AIからの返答に```が含まれている場合は、それを削除します
if "```json" in output.content:
json_string = output.content.split("```json")[1].strip()
else:
json_string = output.content
# 後ろの```を削除
json_string =json_string.replace('```', '')
# jsonをパースして、pythonのDataflame型に変換します
ai_answer = json.loads(json_string)
ai_answer_df = pd.DataFrame(ai_answer)
# インプットのdfをコピーして得られた結果を追加する
final_df = input_df.copy()
final_df.insert(3,"産業(振り分け結果)", ai_answer_df["standarized_industry"].to_list(),allow_duplicates=True)
final_df.insert(4,"match_score", ai_answer_df["match_score"].to_list(),allow_duplicates=True)
# 結果を確認
pd.DataFrame(final_df)
そして、この様な結果を得ることができました!
制約等
今回は全部で35件のデータを使って処理を行いましたが、これが50件くらいになるとトークンサイズを超えてしまうため、うまく処理ができなくなってしまいます。gpt4になると、最大トークンが4000トークンが8,000または32,000トークンまで拡大するため、もっと多くのデータを処理することができますし、また、今回の処理に少し手を加えて処理できる件数分ずつをループで回すと言ったこともできるかと思いますので、工夫次第で大量のデータの処理もできそうです。
まとめ
今回は職業を産業に分類すると言う例で試して見ましたが、この方法を応用すれば、表記フレのある会社名を統一化したり、コメントを分類したり、いくつかのパラメータからお買い得スコアを作ったり、いろんな応用ができそうです。
今回行った検証はライブラリー(langchain)を使用しなくても同様の結果を得ることはできますが、ライブラリを使いこなすことで楽ができ、より適切な結果を得ることができるとも感じました。
今回紹介した例以外にも活用例はいろいろ考えられそうなので、検証した結果をまとめていきたいと思います。
いかがでしたでしょうか?まだまだChatGPTの活用例はありそうなので、色々まとめていきたいと思います。
先日、独自データを使ってChatGPTに回答してもらう方法についての記事も書きました、興味がある方はこちらもどうぞ!