
某勉強会で発表した資料ですが、公開します。
Creative Common 4.0 by-sa
1. Pachydermとは?
Pachyderm - Scalable, Reproducible Data Science
https://www.pachyderm.io/
データ処理のための
- データ(トレーニングデータ、モデルデータ含む)のバージョン管理
- データ操作パイプライン
を構築できるフレームワークです。
※有償のEnterprise Edition があります。
Enterprise Editionはダッシュボード機能やアクセスコントロール、ジョブ実行やデータに
ついての詳細統計が取得できます。
今回は、OSSでのPachydermについてご紹介します
2. Pachydermを作った人が困っていたこと
Spark、Hadoopを使っていたが、それらには問題があった
- どういうデータが元々あったか?変更途中のデータの履歴がない
- どういう風にデータを修正したかという操作履歴がない
- 元データに変更があった場合に同じような操作をなんども手動で実施する必要がある
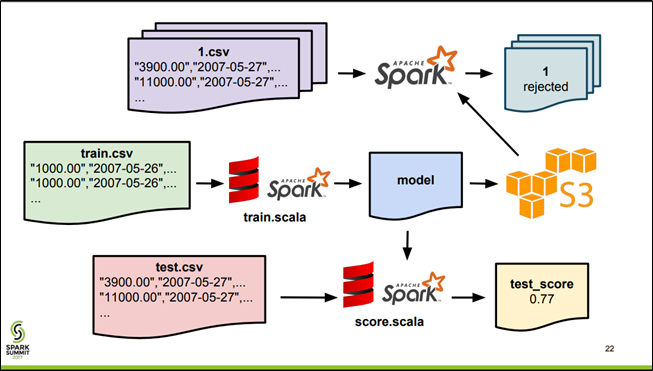
Fully-Reproducible ML Deployment with Spark, Pachyderm, and MLeap - Databricks
https://databricks.com/session/fully-reproducible-ml-deployment-with-spark-pachyderm-and-mleap
3. Pachydermと他のソリューションとの比較(当時)
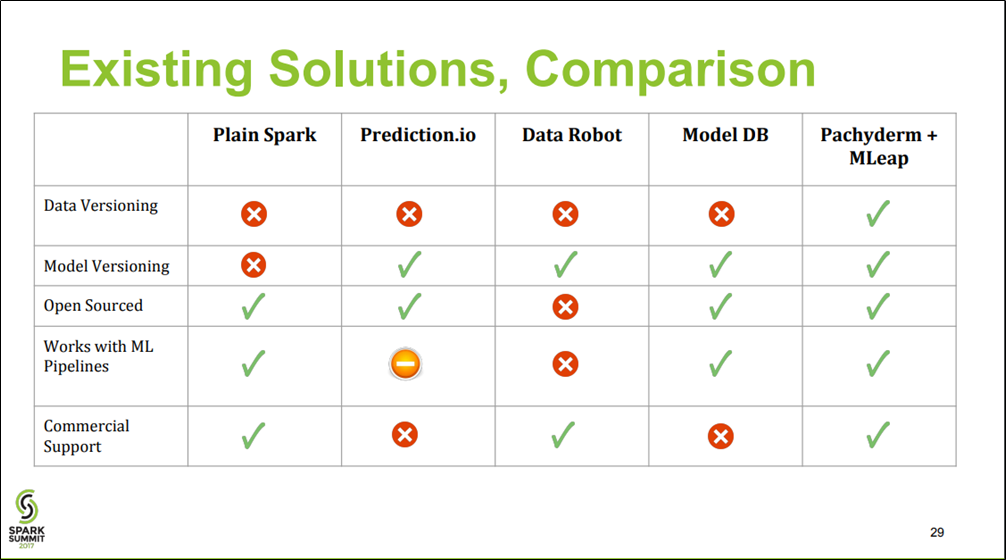
Fully-Reproducible ML Deployment with Spark, Pachyderm, and MLeap - Databricks
https://databricks.com/session/fully-reproducible-ml-deployment-with-spark-pachyderm-and-mleap
4. データがバージョニングされるツールがなかった(当時)
データをバージョニングして、データ操作をパイプライン化するというツールはなかったので、Pachydermの開発者は開発を開始した。
5. Kubeflowとのインテグレーション
Kubeflowプロジェクトに採用予定
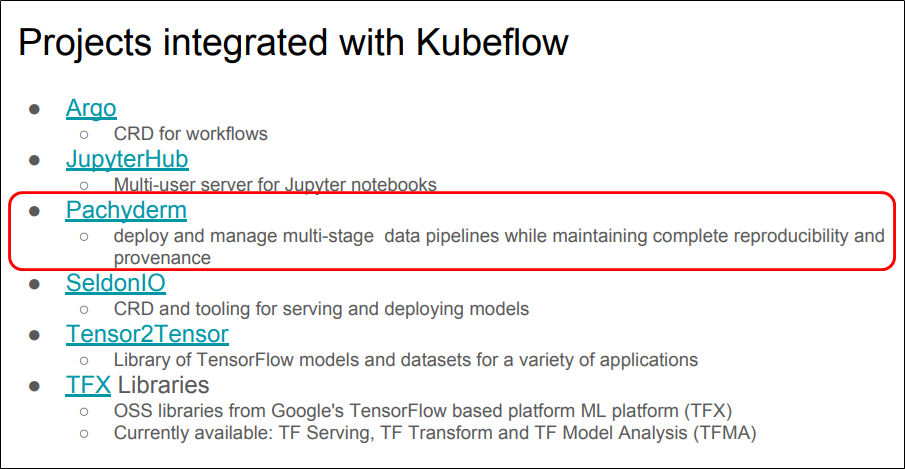
Ref: Kubeflow Project: Deep Dive
https://kccnceu18.sched.com/event/Drnd/kubeflow-deep-dive-david-aronchick-jeremy-lewi-google-intermediate-skill-level
6. Pachydermではどういうことができるか?
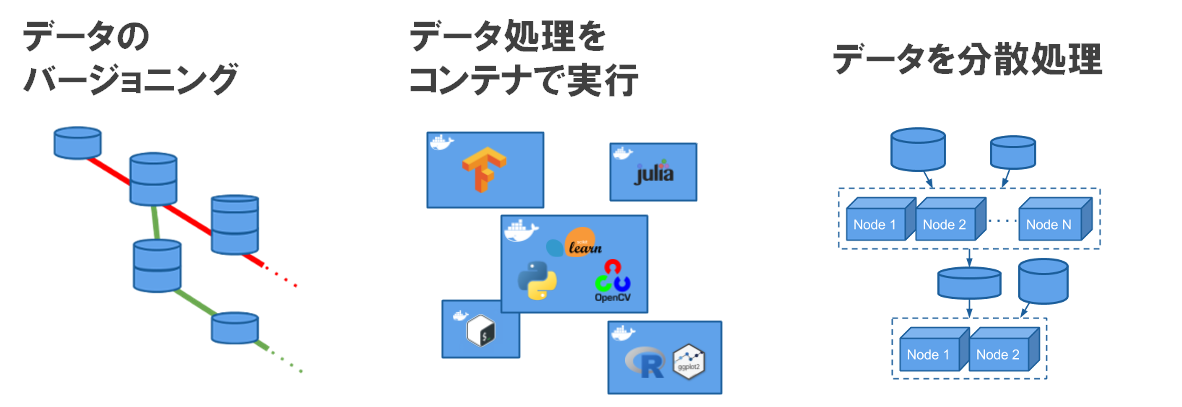
- データのバージョニング
- データ処理をコンテナで実行
- データを分散処理
Pachyderm - Scalable, Reproducible Data Science
https://pachyderm.io/open_source.html
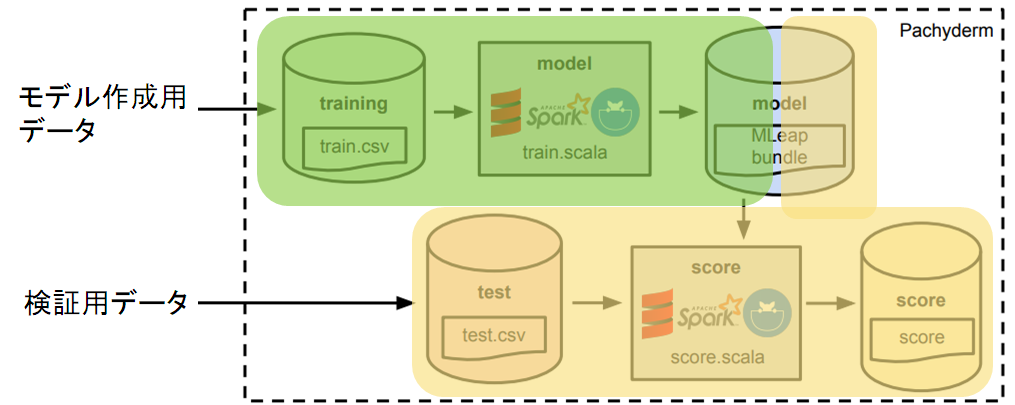
7. 動作例
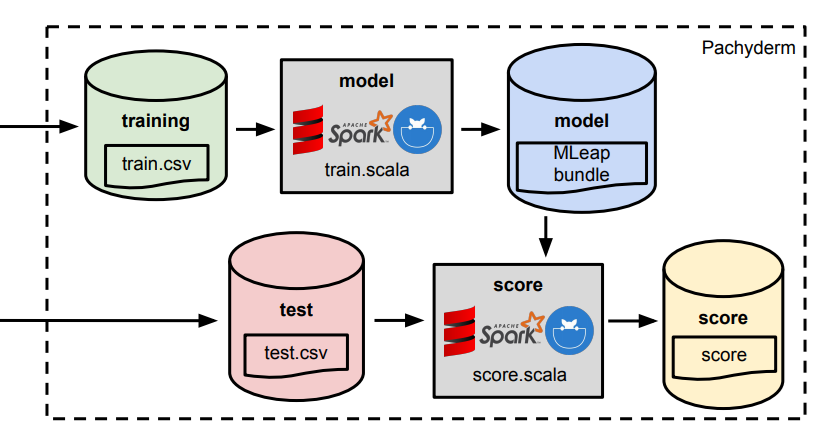
7-1. 全体像
このようなデータ処理があったとします。
7-2. リポジトリ(データストア)
データが保存されている場所=リポジトリがあります
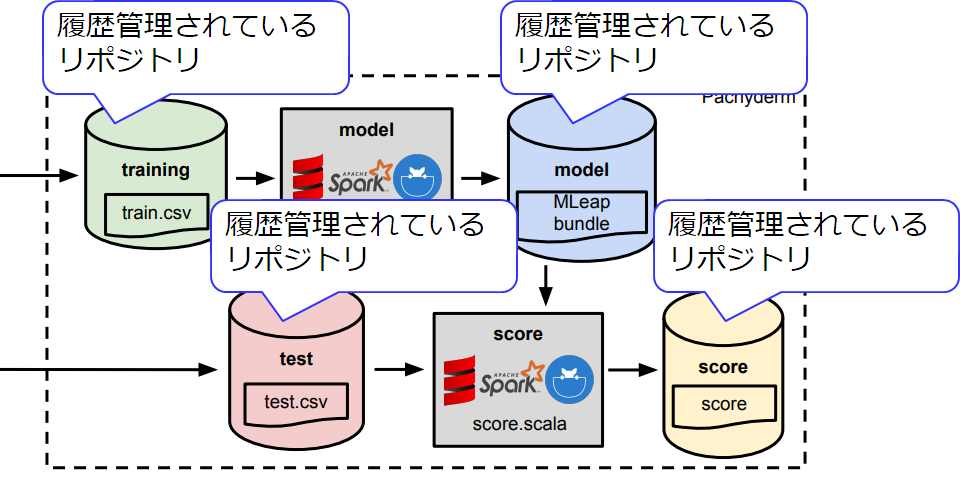
7-3. パイプライン
データを処理する=パイプラインがあります
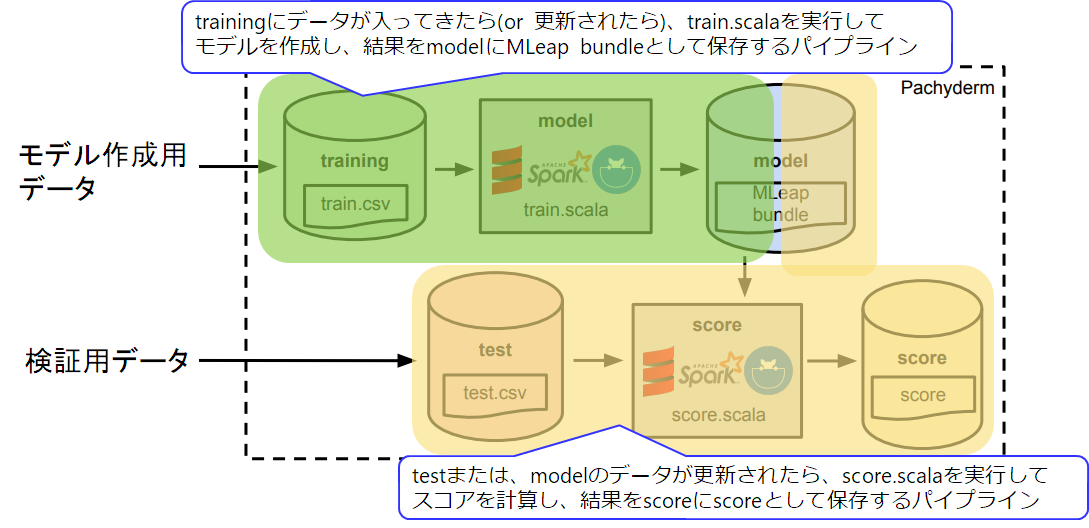
7-4. 実行
- trainingにデータを入れたら自動的にバージョニングされて、train.scalaが動いて、modelにバージョニングしてデータを保存
- testにデータを入れるか、またはmodelにデータが入ったら、score.scalaが動いて、scoreにバージョニングしてデータを保存
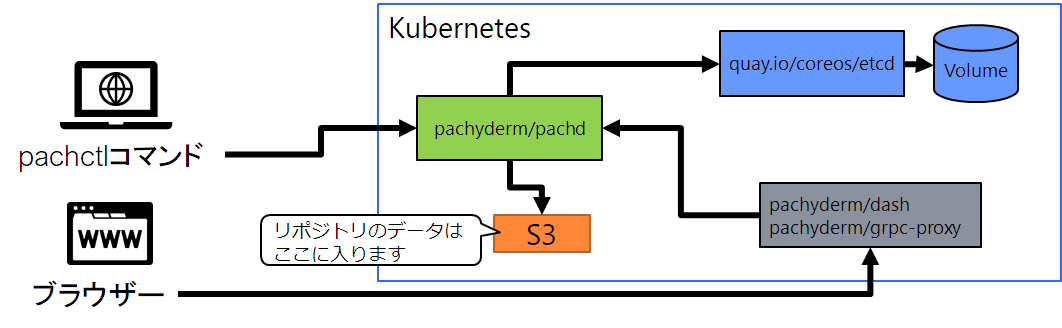
8. Pachyderm について
-
Pachyderm動作要件
- Kubernetes
- Pachyderm
- S3 compatible storage(option)
-
Pachyderm システム構成要素
- pachd(Pachydermジョブコントローラー)
- etcd(ジョブデータ保管)
- dash(Pachydermダッシュボード)
9. Pachyderm インストール
-
Kubernetesに接続できる環境で
- Pachydermコマンド(pachctl)をインストール
- PachydermをKubernetesクラスターにpachctl deploy localでデプロイ
-
Pachyderm構成イメージ
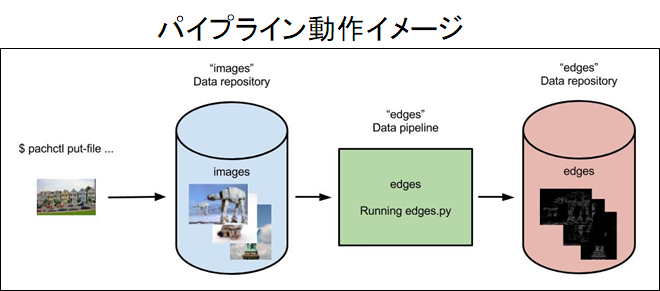
10. Pachydermの使い方(例)
- Pachydermを使う
- データを入れるリポジトリを作る(pachctl create-repo hogehoge)
- ファイルをレポジトリーにputする
- パイプラインファイルをjsonファイルで作成する
- パイプラインファイルを取り込む
- 自動的に実行
パイプラインサンプル
{
"pipeline": {
"name": "wordcount"
},
"transform": {
"image": "wordcount-image",
"cmd": ["/binary", "/pfs/data", "/pfs/out"]
},
"input": {
"atom": {
"repo": "data",
"glob": "/*"
}
}
}
11. Pachydermのデータ保存
- Pachydermをデプロイするときにデータ保存先を指定する
データは、トレーニングデータ、モデルデータを保存できる
保存先は、S3 互換のオブジェクトストレージも使える - ジョブ実行履歴は、etcdのKVSに入る
移行や別の場所での確認時には、pachctl extract で明示的にエクスポート、pachctl restoreでインポートする必要がある - 実行ジョブのソースコードはコンテナーイメージに入れておくか、コンテナー実行時にソースコードを読み込む必要がある
(ソースコード修正時のトリガーは別途用意する必要がある) - コンテナーイメージ実行時にPachydermのリポジトリデータは、以下のマウントパスで参照できる
/pfs/<リポジトリ名>
データ出力ディレクトリは以下のマウントパスにする必要がある
/pfs/output
12. Pachydermのパイプラインについて
- パイプライン実行タイミングは、リポジトリが更新された時
- Pachydermのパイプラインは複数のデータリポジトリを参照できる
- 実行する処理は、コンテナーイメージを指定
- 実行する処理はオプションも指定可能
- パイプラインの並列分散実行も可能
- sparkやhadoopも呼び出せる
- cron定期実行も可能
- リポジトリの更新された新しいファイルのみ処理も可能
13. Pachyderm 情報リンク
まだ日本語での情報は少ない。
- Pachyderm - Scalable, Reproducible Data Science
https://pachyderm.io/ - Fully Reproducible ML Deployment with Spark, Pachyderm, and MLeap - YouTube
https://www.youtube.com/watch?v=TmTYenyOU0s - Pachyderm Developer Documentation — Pachyderm 1.8.2 documentation
https://pachyderm.readthedocs.io/en/latest/index.html - Pachydermによるデータ管理とパイプライン | Research Blog
https://adtech.cyberagent.io/research/archives/890
- Modern Linux Pipeline Programmingを補助してくれるツールたち - Qiita
https://qiita.com/mumoshu/items/fc6f6a3149e82f7b375f#pachyderm - 3 go/debian での機械学習環境構築について
https://tokyodebian-team.pages.debian.net/pdf2018/debianmeetingresume201803.pdf
- CoreOSとDockerの上でビッグデータ分析の敷居をフロントエンドプログラマ向けに低くするPachyderm | TechCrunch Japan
https://jp.techcrunch.com/2015/01/24/20150123pachyderm/