初めに
この記事は、上記記事で紹介したポートフォリオで使用した技術を切り出した記事になります。もし宜しかったらこちらもご覧ください。
イメージ図
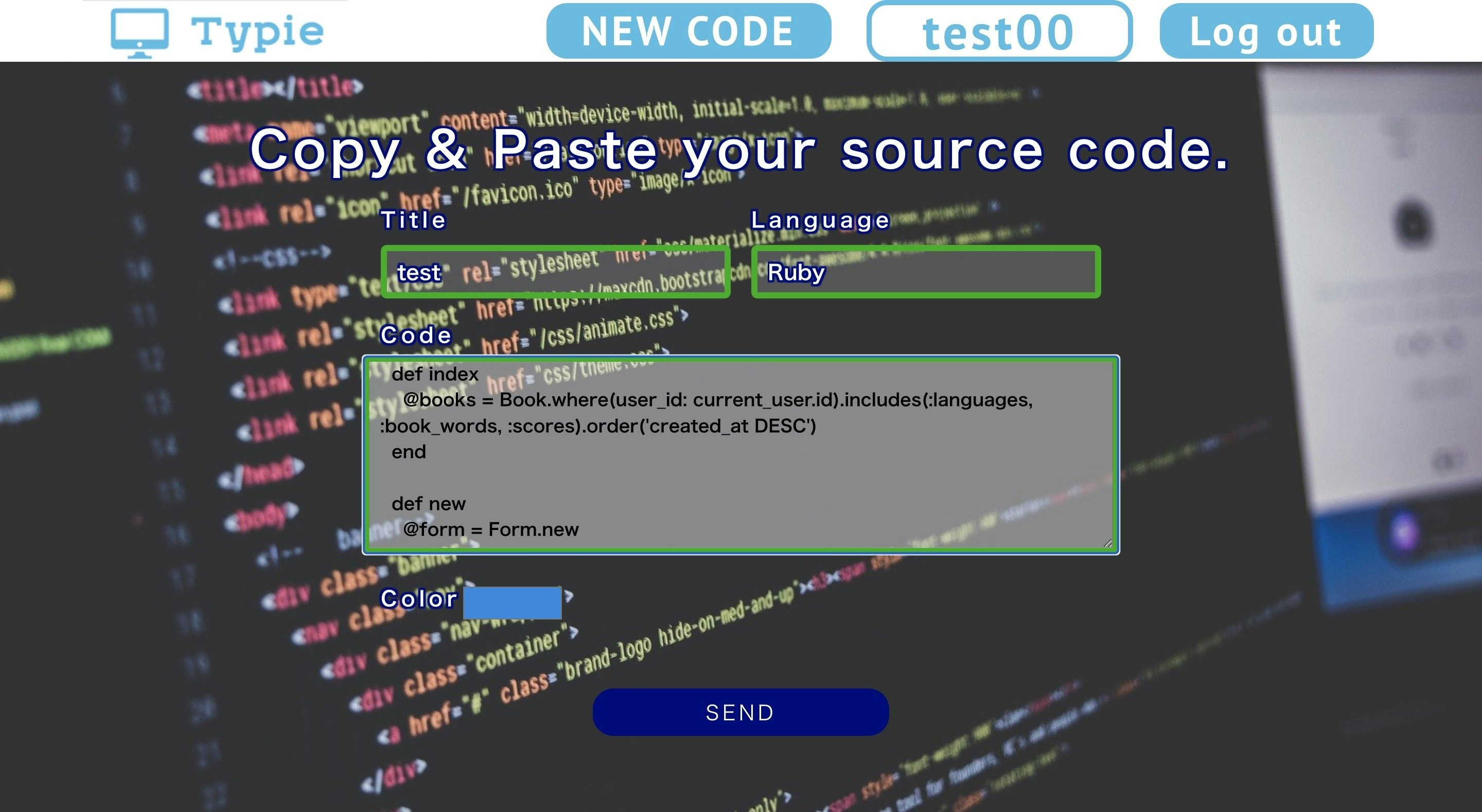
上記画像のように、コピペしたソースコードから英単語を抽出し、初出の英単語のみ保存するプログラムを組んでみました。ポートフォリオのタイピングアプリにおいて必須になる機能です。
開発環境
- Ruby 2.6.5
- Rails 6.0.3
実際に組んだプログラム
def save
ActiveRecord::Base.transaction do
book = Book.create(title: title, color: color, user_id: user_id)
strings = code.split(/[\W|\d|\s]+/).uniq.select { |str| str.length != 1 }
strings.each do |string|
word = Word.where(word: string).first_or_create
BookWord.create(book_id: book.id, word_id: word.id)
end
language = Language.where(name: name).first_or_create
BookLanguage.create(book_id: book.id, language_id: language.id)
score = Score.new
score.typing_score = '0'
score.typing_time = '0'
score.book_id = book.id
score.save
end
end
上記ソースコードが実際に英単語問題の作成を行うソースコードです。フォームオブジェクトパターンで組んでいるので他のモデルの記述も入っていますが、実際に英単語の抽出を行っているのは、
strings = code.split(/[\W|\d|\s]+/).uniq.select { |str| str.length != 1 }
strings.each do |string|
word = Word.where(word: string).first_or_create
BookWord.create(book_id: book.id, word_id: word.id)
end
この部分になります。中間テーブルの記述が混じってますが…
解説
順を追って説明していきます。
strings = code.split(/[\W|\d|\s]+/).uniq.select { |str| str.length != 1 }
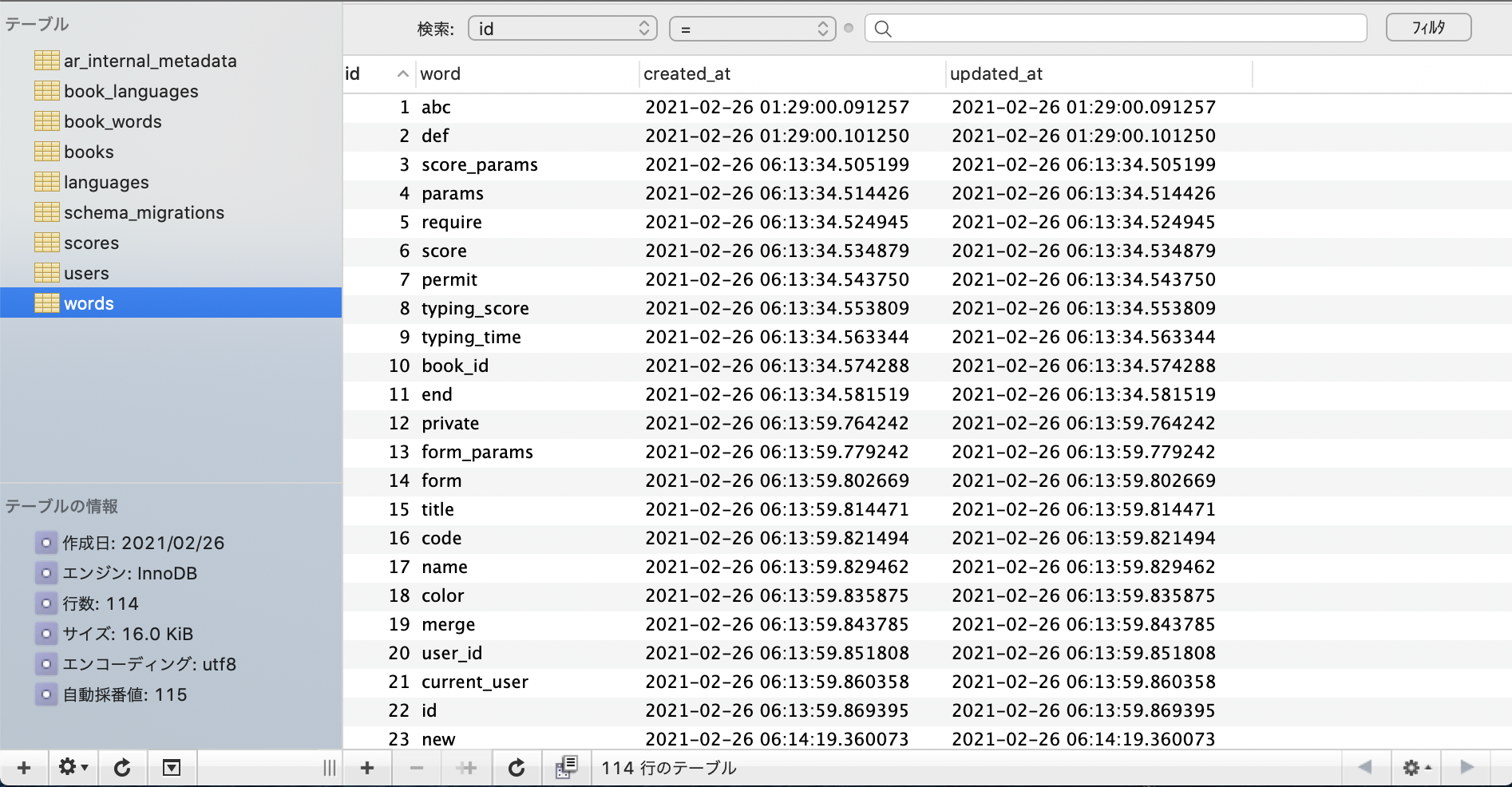
まず、このフォームオブジェクトではコピペしたソースコードの内容を変数codeに格納しています。サーバーのログを見てみると、

上記画像の赤い印をつけた部分のようにデータが飛んできていることが分かります。それでは、ここから半角英単語のみ抽出していきましょう。この場合はstringクラスのsplitメソッドがとても便利です。
stringクラスのsplitメソッド
splitメソッドは、簡単に説明すると**「stringクラスのオブジェクトを、引数に指定した方法を用いて分割し、それらを配列に格納する」メソッドになります。具体的に見ていきましょう。
code.split(/[\W|\d|\s]+/)の部分において、変数codeにはコピペしたソースコードが格納されていますが、半角英語だけでなく数値や全角文字、記号や空白文字・改行文字など、今回は不要なオブジェクトが満載です。splitメソッドが行う処理のイメージは、正規表現などを用いて引数に指定したオブジェクトを「区切り」として、対象から取り除きながら、区切られた文字列を配列に格納するという感じです。今回の記述でいうと、\W 非単語構成文字 [^a-zA-Z0-9_]と\d 10進数字 [0-9]と\s 空白文字 [ \t\r\n\f\v]が1回以上使われている**のを検知した場合、その文字を「区切り」として分割した文字列の集合を配列に格納しています。
つまりこんな処理を行っています。
string = "hoge1huga.ho@ga ho ge"
array = string.split(/[\W|\d|\s]+/)
上記のような記述の場合、string ="hoge[区切]huga[区切]ho[区切]ga[区切]ho[区切]ge"のように、記号や数値・空白文字を[区切]に変換して文字列が格納された変数stringを分割します。その結果、
p array
=> ["hoge", "huga", "ho", "ga", "ho", "ge"]
のように配列に格納されていきます。
arrayクラスのuniqメソッド
さて、stringクラスのsplitメソッドによって、対象となるオブジェクトのクラスがstringクラスからarrayクラスに変わりましたので、ここからは配列を処理するメソッドを使用していきます。
まだ半角英語のみ配列に格納した状態なので、何度も登場する単語が重複してしまっている状態です。この配列から、重複した要素を取り除いた新しい配列を作成するのがarrayクラスのuniqメソッドです。
arrayクラスのselectメソッド
まだ完成ではありません。今のままでは1文字だけの英単語(eachメソッドを使用した際のブロック変数"i"とか)が残ってしまいますので、今回はarrayクラスのselectメソッドを採用しました。(本当はstringクラスのsplitメソッドの正規表現で処理したかったのですが、上手くして指定することが出来ませんでした…。)
strings = array.select { |str| str.length != 1 }
現状、イメージとしては上記のように英単語が格納された配列がある状態です。これに対してarrayクラスのselectメソッドはどのような処理を行うのでしょうか。後ろに波括弧が付いてますね、中身を確認してみましょう。
{ |str| str.length != 1 }一見複雑そうに見えますが、やっていることはとても単純です。arrayクラスのselectメソッドが行う処理は、配列内の要素1つ1つに対して条件式を適用し、返り値がtrueになった要素だけ抽出して新しい配列を作成するというものです。つまり、波括弧内の|str|はarrayクラスのeachメソッドにも登場するブロック変数であり、配列に格納されている英単語1つ1つに対して条件式str.length != 1を実行しているだけのメソッドになります。今回の場合は、「文字数が1文字ではない英単語」のみ抽出して新しい配列に格納しています。
これにて、目当ての英単語のみ格納された配列が完成しました。
初出の単語のみ保存する
ゴールまであと一歩です。最後に、初出の単語のみ保存する処理を記述していきます。これを記述しなければ同じ単語が何度も保存されてしまうためデータベースを圧迫してしまいます。英単語は文字列のため数値などと比べて容量が大きいので、既に保存されている単語が送信されてきた際は登録されている単語のレコードだけ返す処理の方が効率的です。これを可能にするのがfirst_or_createメソッドもしくはfirst_or_initializeメソッドとsaveメソッドになります。
strings.each do |string|
word = Word.where(word: string).first_or_create
BookWord.create(book_id: book.id, word_id: word.id)
end
first_or_createはとても便利なActiveRecordメソッドで、上記のようにwhere句と組み合わせて使用することで、「特定のカラムに特定のバリューは存在するか」を検索した後、存在しないなら新しくレコードを作成し、レコードの情報を変数に格納することができ、存在するならそのレコードを変数に格納することが出来ます。
もしレコードを参照するタイミングと保存するタイミングを分けたいならばfirst_or_initializeメソッドとsaveメソッドを使いましょう。
まとめ
データを思うように成形するには「それは何クラスのオブジェクトか」というのをまず考えるようにしたことで、目当てのメソッドを見つけるまでの時間が格段に短くなっていきました。まだまだ使い方を知らないメソッドだらけですが、1つ1つ着実に習得していきたいです。