#はじめに
みなさま、ゴールデンウィークはいかがお過ごしでしょうか。コロナの影響で外出もしづらい状態になっています。GW中に以下の本を買って読んでいて、フロントエンド開発で手を動かしたくなったので「音声認識チャットアプリ」を作ってみたいと思います。フロントエンド の苦手克服がテーマです。
https://qiita.com/official-events/b9ad63394fa2635dfca9
成果物のイメージはこちらです。
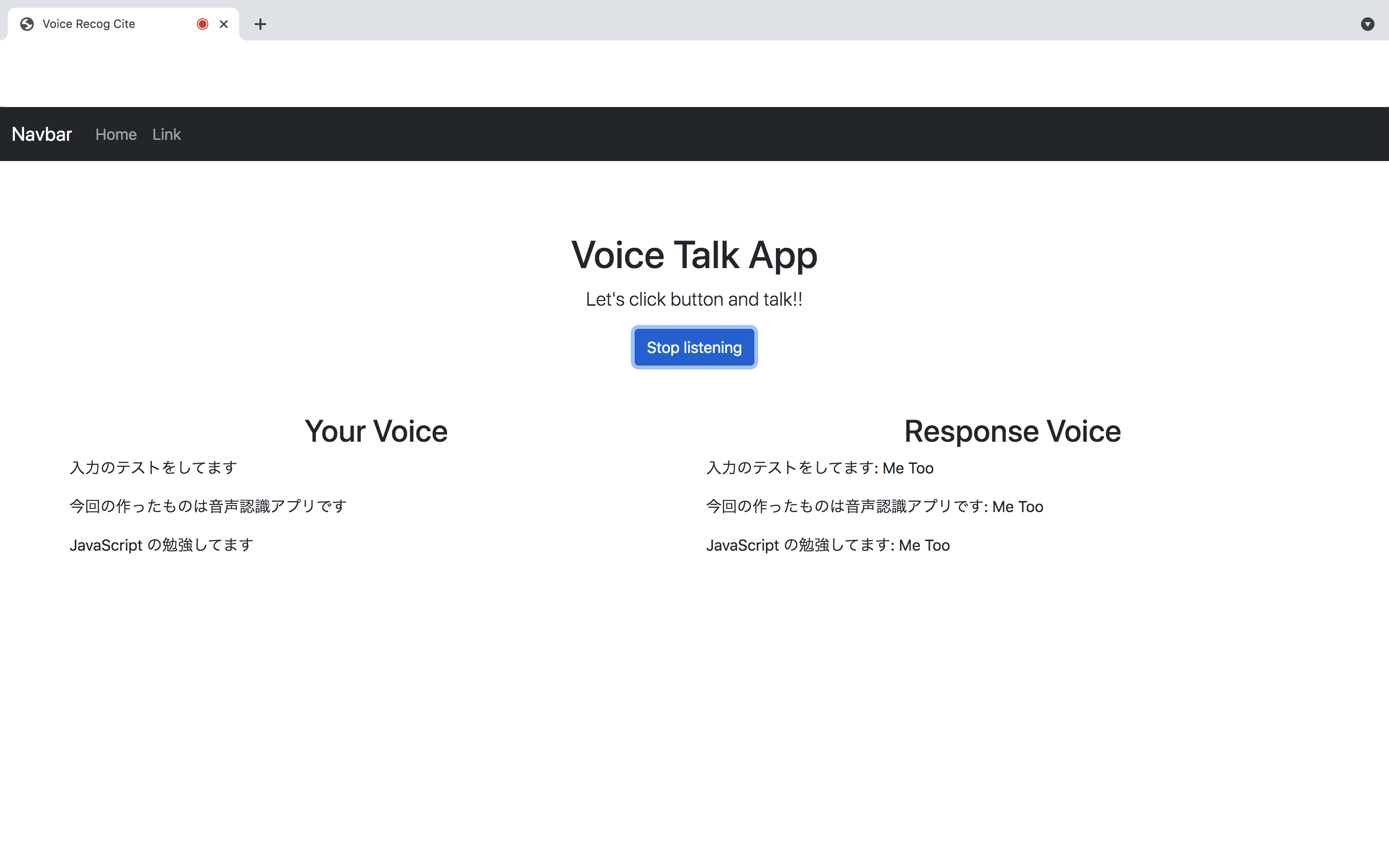
成果物は以下のGithub(qiita0502ブランチ)にあげてあります。
機能説明について、【Button】をクリックすることにより, 音声認識を開始します。音声はリアルタイムで書き込み、そのまま出力します。また、その音声認識結果に対して、応答文章を生成し、右側に表示します。
本記事は、以下の順を追って解説していきたいと思います。
- システム設計 (本記事)
- Javascript の環境構築 (本記事)
- フロントエンドの実装 (本記事)
- バックエンドの実装
開発環境について、私はMac Book Pro (MacOS) を使用しました。基本的にMacユーザであれば不自由なく実装できるかと思います。
#システム設計
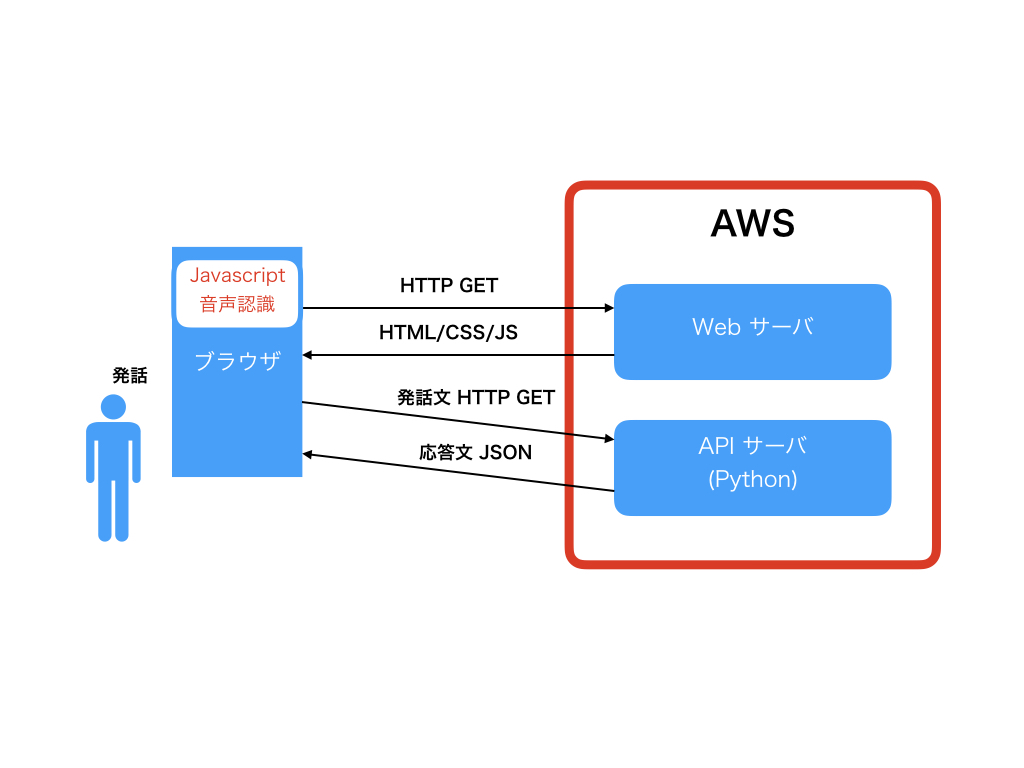
まずはじめにシステムの全体像を確認します。端末はブラウザが動作するPCおよびWebサーバです。処理の流れは以下になります。
- フロントエンド(ブラウザサイド)で発話した言葉の音声認識を行い、文章単位にわけます
- 文章単位でバックエンドのサーバに送ります
- バックエンドAPIサーバでは、受け取った文章を元に応答文を考え、それをフロントエンドに返します
- フロントエンドは応答文を受け取り、表示します。
目標としてJavascriptの習熟があるので、フロントエンドはJavascriptで書き上げます。
バックエンドはPythonによりAPIサーバを実装します。フロントエンドとの通信は非同期のHTTP通信によって実現します。
#環境構築
実装環境を構築します。今回は今後の拡張とモダンJavascriptを踏まえ、WebPackを使用します。
実装を始める前に以下を行い、環境を構築します。
-
Nodejsを導入
-
yarnの導入
-
WebPackを導入
-
Babelを導入
##Nodejsを導入
以下のサイトにアクセスし、Macのインストーラーをダウンロードして、インストールを行います。
同時にNPM(Nodeのパッケージマネージャー)もインストールされます。執筆時点での私の環境に入った各ソフトのバージョンは以下でした。
Node → v14.16.1
npm → 6.14.12
ちなみにパッケージマネージャーとは第三者の作ったライブラリなどを導入する際に、各ライブラリのバージョンを管理できるソフトウェアです。NPMはノード用のパッケージマネージャーになります。例えばRubyであれば、gemが該当します。
##Yarnの導入
前述したではなく今回はyarnを利用します。モチベーションは以下です。
- npmよりインストールが速い
- npmより厳密にモジュールのバージョンを固定できる
- npmと同じのpackage.jsonが使えるため、同一プロジェクトでnpm or yarnで固定しなくて良い。
以下のコマンドでnpmによりyarnを導入します。
sudo npm install -g yarn
yarn → 1.22.10
##WebPackの導入
以下の記事が非常に参考になります(ほぼこれ通り)。
WebPackは複数のJavascript等アセットファイルを一つのファイルに合成することができます。例えば複数のJavascriptファイルを一つのファイル(例えばbundle.js)に合成し、そのファイルのみをHTMLファイルから読み込むことでフロントサイド側での複数jsファイルの読み込み記述の省略することができます。
Webpackは箱みたいなもので、ユーザの利便性に合わせ自由に機能をして開発を行うことができます。例えば有名なBabelなどのローダー(機能だと思ってもらって結構です)を追加することで、**ECMAScript2015 (ES2015)**などの新標準のJavascriptの文法を従来仕様のJavascript文法に変換(トランスコンパイラー)してブラウザ間の対応/非対応に適応したコードにすることができます。
mkdir voice_test
// 1. テストディレクトリを作成
yarn init
// 2. 初期化。色々聞かれるので入力していく。終えるとpackage.jsonが作成される
yarn add webpack webpack-cli --dev
// 3. webpackの導入(CLI操作も可能にする)
//node_modules
//package.json
//yarn.lock
//が生成される
WebPackの処理の設定についてはwebpack.config.jsというファイルを作成し、記述するルールとなっている。
const path = require('path');
module.exports = {
//ファイル更新の監視。合成元ファイルが更新された場合、すぐさま再合成をかける。
watch: true,
mode: 'development',
//合成する元のファイル(複数可)の指定
entry: [
'./src/js/hello.js'
],
output: {
//合成したファイルの出力先指定。HTMLからはbundle.jsのみ読み込めば良い
filename: 'bundle.js',
path: path.join(__dirname, 'public/js')
}
};
##作業様ディレクトリの用意
ここまででwebpackは無事動いているはずなので、実際にコードを書く準備をします。以下のようなレイアウトにしてみました。
.
├── node_modules
├── package.json
├── public
│ ├── css //実際にCSSを書くディレクトリ
│ ├── index.html //実際にHTMLを書くファイル
│ └── js
├── src
│ └── js //実際にJavascriptを書くディレクトリ
├── webpack.config.js
└── yarn.lock
src
└── js
└── hello.js //コーディングするJavascriptファイル
public
├── css
│ └── template.css //コーディングするCSSファイル
├── index.html //コーディングするHTMLファイル
└── js
└── bundle.js//Webpackにより合成されたJavascript
##Webpack実行
ここまで終えたら以下のコマンドを実行して動くかテストしましょう。
yarn run webpack
パッケージマネージャーの威力を見るために、今回の実装にjqueryを導入してみたいと思います(おまけ)。
yarn add jquery
すると以下のようにdependenciesにjqueryが追加されます。これで先ほどのhello.jsからjqueryをimport等して使用することができます。
{
"name": "qiita_demo",
"version": "1.0.0",
"main": "index.js",
"license": "MIT",
"devDependencies": {
"webpack": "^5.36.2",
"webpack-cli": "^4.6.0"
},
"dependencies": {
"jquery": "^3.6.0"
}
}
#フロントエンドの開発
##フロントエンド用ファイルの準備
GitHubのホームページから**git clone(qiita0502ブランチ)**し、必要ファイルをダウンロードしてみてください。
また、上記の階層に、所定のファイルをコピーしてみてください。
index.html/template.css/hello.js あたりが必要になると思います。
使用した基本的なテンプレート→HTML, CSS
レイアウト等の話なので、今回は割愛します。これでファイルが所定の位置に置かれたと思いますので、以下のコマンドを実行し、jsファイルを合成してください。
yarn run webpack
index.htmlをダブルクリックなどでブラウザから開くと成果物のアプリの画面が見れるはずです。これでひとまず、成果物の動作環境は構築できました。
##フロントエンドの実装内容
今回の実装の大部分は、以下のブログで解説されているコードを元に開発しました。音声認識の部分です。こちらのブログで解説されていた内容では、ブラウザに向かって読み上げた音声を認識し、文字としてHTMLファイル中の 段落id="result"の箇所に追加するというものです。
今回、追加機能として必要なのが以下です。
- ボイスの切れ目で一旦文章として区切る
- 文章として区切った文字列をサーバに対して送る
- サーバーから応答文章をもらい、表示する
##ボイスの切れ目で文章として区切る
発話中はonResultイベント関数が実行されています。発話の切れ目になるとクラス名に"final"が追加されたpタグが生成されます。
本アプリでは、トークスタート時のボタンクリックアクションをユーザが行なった際、別軸でタイマー関数を発火させ、get_talkを呼び出します。
get_talkは1500msecに一度、クラス名が"final"であるものの最新をチェックし、直前に保存したものと異なる場合には新しいユーザの発話とみなし、APIサーバへ送信します(実装中のrequest_callback)。
また、その結果をDOMツリーに追加します(add_response)。
##文字列をAPIサーバに送る → 応答文をもらい、表示する
先にフロントエンドの開発を進めたいので、フロントエンド側に指定文字列をサーバに送る関数request_callbackを実装しました。本記事の段階では、実際にAPIサーバには送っていません。本記事の実装では、request_callback内部で応答文章作成の関数echoを呼びます。
echo関数は元の文章に"Me Too"を足した文字列を生成する関数です。(繰り返しますが、本来は応答文章はバックエンドAPIサーバ側で生成します。この部分の実装は次の記事に回します。)
##実際のJSコード
以下に、実際のコードを掲載します。(githubのコードと同じです。)
/*応答文章の生成. 本来はAPIサーバー側の実装. */
const echo = (text) => {
return text + ": Me Too";
};
/*文章をAPIサーバーに送り, 応答文章を取得する. */
const request_callback = (text) => {
let callback = echo(text);
return callback;
};
/*ボタンを押されている間, タイマーにより定期的に呼ばれる関数. 最新のfinalクラスのコンテンツを取得し、直前のものと比較する. 異なる場合には新しい発話が文章として見なされたとみなし、APIサーバーに送信する. */
const get_talk = () => {
const $final_talk = document.getElementsByClassName("final");
if ($final_talk.length !== 0) {
if(last_talk !== $final_talk[$final_talk.length - 1].textContent){
last_talk = $final_talk[$final_talk.length - 1].textContent;
add_response(request_callback(last_talk));
}
}
};
/*応答文章のDOMツリーへの反映*/
const add_response = (text) => {
const $response = document.getElementById("response");
const text_node = document.createTextNode(text);
const $p = document.createElement("p");
$p.classList.add("fin_response");
$p.appendChild(text_node);
$response.appendChild($p);
};
/*応答文章の削除*/
const remove_all_response = () => {
const $response = document.getElementById("response");
while ($response.firstChild) {
$response.removeChild($response.firstChild);
}
};
let speechRecognition = new webkitSpeechRecognition();
speechRecognition.onresult = console.log;
speechRecognition.start();
let intervalId;
window.addEventListener("DOMContentLoaded", () => {
const $button1 = document.getElementById("button1");
const $result = document.getElementById("result");
const $main = document.getElementById("main");
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition
if (typeof SpeechRecognition === "undefined") {
$button1.remove();
const message = document.getElementById("message");
message.removeAttribute("hidden");
message.setAttribute("aria-hidden", "false");
} else {
// good stuff to come here
let listening = false;
const recognition = new SpeechRecognition();
const start = () => {
recognition.start();
$button1.textContent = "Stop listening";
$main.classList.add("speaking");
remove_all_response();
intervalId = setInterval(get_talk, 1500);
};
const stop = () => {
recognition.stop();
$button1.textContent = "Start listening";
$main.classList.remove("speaking");
clearInterval(intervalId);
last_talk = "";
};
const onResult = event => {
$result.innerHTML = "";
for (const res of event.results) {
const text = document.createTextNode(res[0].transcript);
const p = document.createElement("p");
if (res.isFinal) {
p.classList.add("final");
}
p.appendChild(text);
$result.appendChild(p);
}
};
recognition.continuous = true;
recognition.interimResults = true;
recognition.addEventListener("result", onResult);
$button1.addEventListener("click", () => {
listening ? stop() : start();
listening = !listening;
});
}
});
/* talk words*/
let last_talk = "";
#おわりに
今回の記事では、Javascriptの開発環境をWebpackをベースに構築し、githubのコードを動かして見ました。また、フロントエンドの実装を解説しました。次回はAPIサーバとの連携について書き、チャットの会話っぽく進化させます。
フロントエンド強化月間にも参加中!
(次の記事, 目標GW中!!)