Python で金融データを収集し分析するにあたり、テクニカル分析における代表的な指標を算出するにあたってはライブラリとして TA-Lib があります。以前に書いたように pandas で株式の日足データ (= 日ごとの始値、高値など) を分析する場合、代表的なさまざまな指標を算出するにはすべて自前で実装するよりライブラリを使ったほうが便利ですし安心です。
TA-Lib
http://ta-lib.org/
TA-Lib を使えるようにする
この TA-Lib を Python で利用するには Python 用のバインディングが用意されています。
インストール方法
http://mrjbq7.github.io/ta-lib/install.html
インストール方法は簡単でソースの tar ボールをダウンロードして make install すれば良いです。上のリンク先では --prefix=/usr としていますが FHS を考慮すると --prefix=/usr/local したほうが良いでしょう。
VERSION=0.4.0
FILENAME=ta-lib-$VERSION-src.tar.gz
curl -L http://prdownloads.sourceforge.net/ta-lib/$FILENAME -O
tar xzvf $FILENAME
cd ta-lib
./configure --prefix=/usr/local
make
sudo make install
Python バインディングは執筆時点では easy_install で入れることができます。
easy_install TA-Lib
eazy_install が成功したら IPython から import talib as ta して ta. ではじまる関数群が使えることを確認しておきましょう。
TA-Lib を使う
機能の一覧や使い方は上記 GitHub のサイトを見れば良いのですが、簡単に説明すると
import talib as ta
ta.get_function_groups
とすれば各機能と機能ごとのグループを見ることができます。
以前に書いた通り Yahoo! ファイナンスから株価データをスクレイピングすれば TA-Lib を利用して自由自在に計算をおこなうことができます。ただしスクレイピングである以上あまりにたくさんのデータを処理しようとすると問題になることがあります。有料ですが Yahoo! ファイナンス VIP 倶楽部 から時系列データをダウンロードするといったこともできますので、必要に応じてデータを購入するのも手です。
データを用意したら IPython を利用してハンドリングしてみましょう。
filename = 'stock_N225.csv' # 日経平均株価データ
df = pd.read_csv(filename,
index_col=0, parse_dates=True)
closed = df.asfreq('B')['Adj Close'].dropna() # 調整後終値を抽出
prices = np.array(stock, dtype='f8') # 浮動小数点数による NumPy 配列にしておく
# 5 日単純移動平均を求める
sma5 = ta.SMA(prices, timeperiod=5)
# RSI (14 日) を求める
rsi14 = ta.RSI(prices, timeperiod=14)
# MACD (先行 12 日移動平均、遅行 26 日移動平均、 9 日シグナル線) を求める
macd, macdsignal, macdhist = ta.MACD(prices,
fastperiod=12, slowperiod=26, signalperiod=9)
とまあこのように TA-Lib に実装されているテクニカル指標なら一通り計算することができます。
プロットする
数値だけだとイメージしづらいのでいくつかプロッティングしてみましょう。おなじみの pandas + matplotlib と talib のコンビネーションでいわゆる株式ソフトと同様にチャートをプロットすることができます。
まずは最近 180 日の日経平均株価から、日足チャート、 EWMA (指数加重移動平均) 、ボリンジャーバンドをプロッティングしてみます。
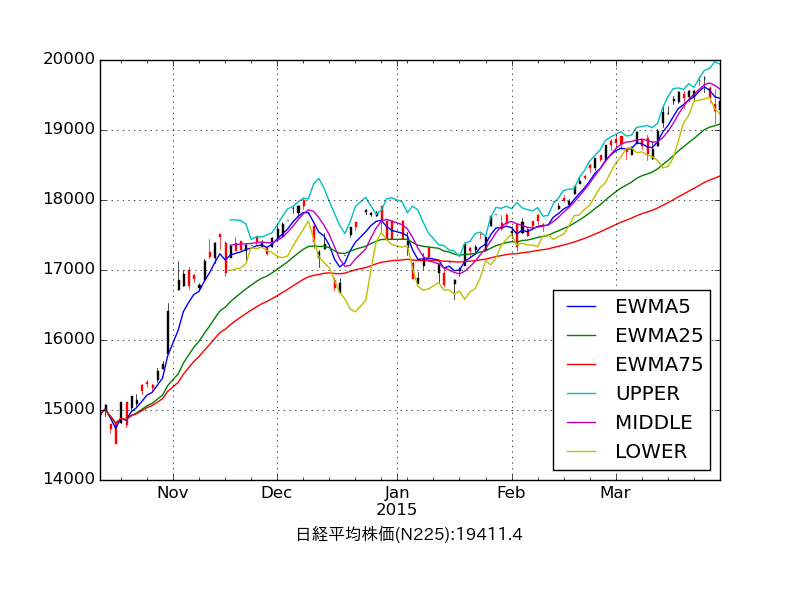
見ての通り 25 日移動平均からの乖離がそれなりにあって下支えになり、また標準偏差 +2σ の線が上値となっていることがわかります。
次に任天堂と提携したことで二日連続ストップ高となり話題を集めた DeNA 社を見てみましょう。今度は直近 90 日間のプロットです。
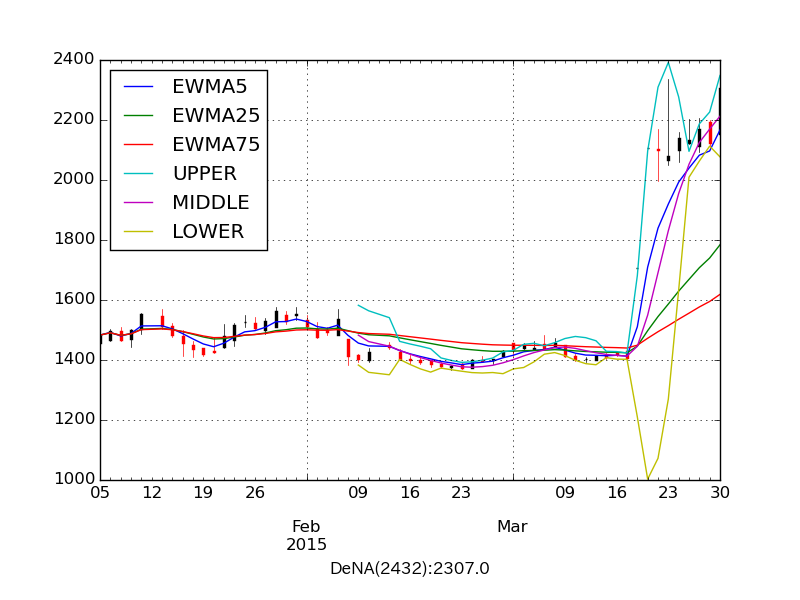
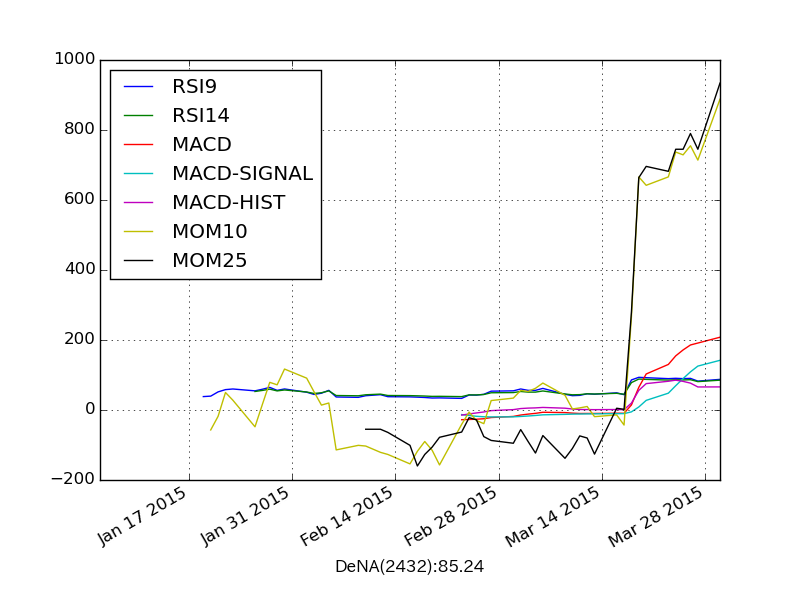
オシレーター系指標を見ると驚異的な強気相場となっていることがわかります。
なお、このようにチャートの話となるとさまざまな株の専門家が出てきて色々と大変なのですが、筆者は株の専門家ではなくあくまで IT と統計・機械学習によるデータ分析という観点からデータを見ています。
統計的観点でのアプローチをするならば、データの変化を数値化し、過去のデータからどのように変化するか予測するなどといったアプローチをしていくのが正統と言えるでしょう。
人間の認知にはゆがみがあります。きっと上がるだろうと思って買い、きっと下がるだろうと思って売るのですから、どうしてもバイアスのかかった判断をしがちです。
テクニカル分析はもちろん万能ではありませんが、このようなバイアスを排除し、機械的な判断をするために役に立つでしょう。
機械学習による循環物色をおこなう
さて、いくつかの銘柄が上昇したとき、これらのテクニカル指標をもとに、東証の全銘柄から似た相場の他の銘柄を物色し買いたいことがあります。このように上昇相場において他の業種に投資対象をめぐらせながら次の上昇株を探すことを循環物色と言います。つまり、利益確保した銘柄はもう十分に高値なわけですから、今度は別の銘柄が上がるのではないかと次のターゲットを探すというわけですね。
現在ホールドしている株式を売却して、このように他の材料株に資金を新しく投入したいとき、市場をいちいち人力で調べていたのでは膨大な時間がかかりますし大変な労力です。毎度毎度そんなことをするのは暇人としか言えないでしょう。そこで、せっかく計算機が発達し誰もが手軽に IT や数学を駆使できるのですから、機械学習によって循環物色を試みてみることにします。
まずは教師データとして、すでに利益確定した業種の銘柄を数点ピックアップし、データフレームを生成します。ここでどのような観点で素性を作るのかにもよるのですが、今回はあくまで例として時系列データのモメンタムを単純にピックアップしてみます。
import os
import pandas as pd
import numpy as np
from sklearn import svm
def read_from_csv(stock, filename):
if os.path.exists(filename):
return pd.read_csv(filename,
index_col=0, parse_dates=True)
def read_txt(filename):
stocks = pd.read_csv(filename, header=None)
data = pd.DataFrame([])
for s in stocks.values:
stock = str(s[0])
csvfile = "".join(['ti_', stock, '.csv'])
df = read_from_csv(stock, csvfile).asfreq('B')[-30:]
data[stock] = df.ix[:,'mom25']
print(data.T.tail(10))
return data.T
data = read_txt('stocks.txt')
これで銘柄コードとその日ごとのモメンタムによるデータフレームができあがります。これをあらかじめ銘柄コードごとの時系列のモメンタムによる多重リストに変換しておきましょう。このへんは泥くさいので省略します。
機械学習の話としては、以前に生徒の成績を班ごとに分類し、それをもとに学年全体の生徒を分類するという例を書きました。これを応用して、上の教師データを学習したサポートベクトルマシン分類器で東証一部上場企業全銘柄の過去データを分類します。
from sklearn.cluster import KMeans
from sklearn import svm
kmeans_model = KMeans(n_clusters=100, random_state=100).fit(train_X)
labels = kmeans_model.labels_
clf = svm.SVC(kernel='rbf', C=1) # RBF カーネルによるサポートベクトルマシンを分類器とする
clf.fit(train_X, labels) # 学習
results = clf.predict(test_X) # 分類
これで似たようなモメンタムを示す銘柄を機械的に抽出することができるようになりました。
まとめ
IT と数学を駆使すれば誰でもクオンツのごとく金融データ分析をおこない、実際に投資して利益を上げることもできるでしょう。データ分析は目的が無ければ何の意味もなくむなしいものですが、たとえば投資に役立てるという明確な目的があった場合、その計算は取り組みがいのあるものになるのではないかと思います。なおこの記事は読者に投資をすすめるものではありません。
株式データの分析についてはここまでとし、今回の後半で登場した機械学習について、次回以降より詳しく書いていきたいと思います。