ABEJA Platform AdventCalendar 2018 16日目の記事です.
今回は百度(バイドゥ)が発表した顔検出器である PyramidBox を ABEJA Platform にデプロイして検証してみたの回です.
モチベーション
突然ですが,僕はソフトテニスが好きです.趣味として実際にプレーするだけでなく,自分や他人のプレーを見ながらどこに違いがあるのか,本質的な部分はどこか,なぜ人間はこうもダイナミックな動きを実現できるのかなど色々解析して遊んでいたりします.
以下は試合のワンシーンを抜き取ったものです.僕は画面左上にいるプレイヤーですが,特に正面を向いた姿を解析しようと思った時,サイズが小さく比較的難しいタスクであることが分かります.

以前,後段のタスクに利用するため,顔検出を行ったことがあるのですが,デファクトとなっているような顔検出器では中々に検出が難しく,ワイルドなケースでも顔検出が上手くできる論文を漁っていました.そこで出会ったのが,百度(バイドゥ)が発表した顔検出器である PyramidBox です.
今回はその検証も兼ねて ABEJA Platform にデプロイしてみようと思います.
実装
PyramidBox は github にコードが公開されているので,それをベースに ABEJA Platform にデプロイする handler の実装をしました.
main.py
widerface_eval.py の実装を参考にしながら main.py を実装しました.
import os
import numpy as np
import reader
import paddle.fluid as fluid
from PIL import Image
from pyramidbox import PyramidBox
# The following functions are copied from widerface_eval.py
def detect_face(image, shrink):
(省略)
def bbox_vote(det):
(省略)
def flip_test(image, shrink):
(省略)
def multi_scale_test(image, max_shrink):
(省略)
def multi_scale_test_pyramid(image, max_shrink):
(省略)
def get_shrink(height, width):
(省略)
# The followings are custom code to deploy ABEJA Platform.
# Setup and load model.
place = fluid.CPUPlace()
exe = fluid.Executor(place)
main_program = fluid.Program()
startup_program = fluid.Program()
image_shape = [3, 1024, 1024]
with fluid.program_guard(main_program, startup_program):
network = PyramidBox(
data_shape=image_shape,
sub_network=True,
is_infer=True)
infer_program, nmsed_out = network.infer(main_program)
fetches = [nmsed_out]
fluid.io.load_persistables(exe, 'model', main_program=infer_program)
threshold_conf = float(os.environ.get('THRESHOLD_CONF', 0.15))
def infer(image):
# Detect faces in multiple settings.
shrink, max_shrink = get_shrink(image.size[1], image.size[0])
det0 = detect_face(image, shrink)
det1 = flip_test(image, shrink)
# [det2, det3] = multi_scale_test(image, max_shrink) # Not using multi scale test because the image is already enough large and there is a memory limitation.
# det4 = multi_scale_test_pyramid(image, max_shrink)
# Vote faces.
# det = np.row_stack((det0, det1, det2, det3, det4))
det = np.row_stack((det0, det1))
dets = bbox_vote(det)
# Remove bounding boxes whose confidence is under threshold.
keep_index = np.where(dets[:, 4] >= threshold_conf)[0]
dets = dets[keep_index, :]
return dets[:, 0:4]
def handler(input_iter, context):
for image in input_iter:
bboxes = infer(Image.fromarray(image))
yield bboxes
if __name__ == '__main__':
image = np.asarray(Image.open('test.png'))
bboxes = next(handler([image], None))
print(bboxes)
detect_face の実装などは widerface_eval.py の実装をまるっとコピーしています.本当は import したかったのですが,元々の実装が global な変数を使っていたりとやや取り回しが面倒だったため,今回はこういう方法を取りました.また,本来の精度を求めるのであれば, multi_scale 系の処理は行った方がよいのですが,今回は以下の理由から実行しないことにしました.
- インプットとなる画像が 1280x720 ですでに画像サイズが大きい.
-
multi_scale系の処理を入れると ABEJA Platform がタイムアウトしてしまう.
if __name__ == '__main__': 以下では handler を呼び出して簡単に挙動を確認するための実装を入れています.これを行うことでデプロイする前にある程度正しく動作しているかを確認できるのでオススメです.ちなみに,インプットの画像サイズが大きいとローカルマシンではメモリ不足で動きませんでした...
なお,モデルファイルは同じレポジトリの模型发布から入手できるので,model として置いておきました.
requirements.txt
ABEJA Platform が提供する all-cpu には様々な Deep Learning Framework がプレインストールされていますが, PyramidBox は PaddlePaddle を用いて実装されているため,以下を足す必要があります.
paddlepaddle==1.2.0
デプロイ
以下のような設定で上記のコードから ABEJA Platform 上でモデルを作成しました.
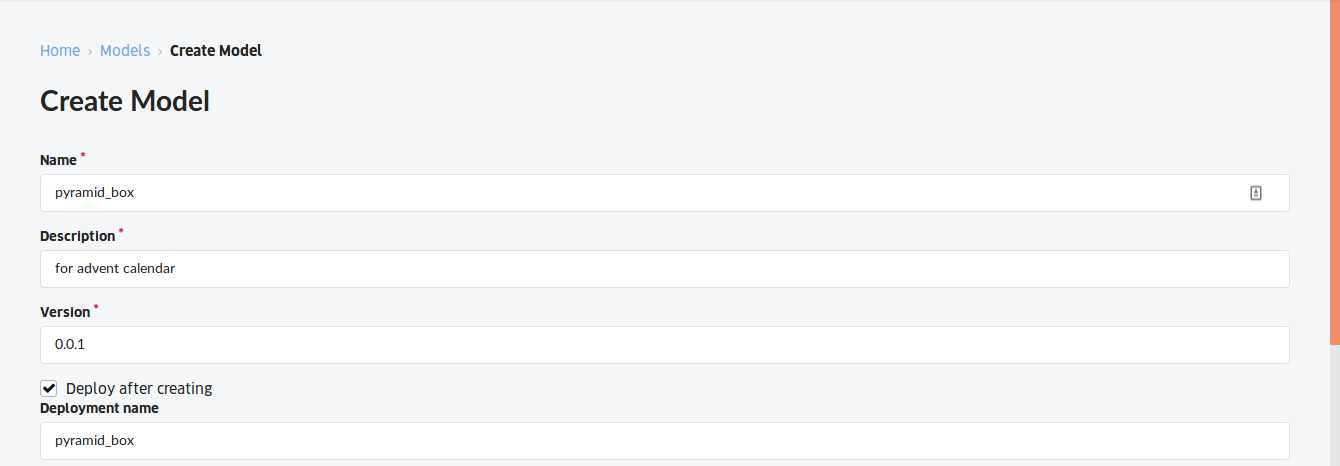
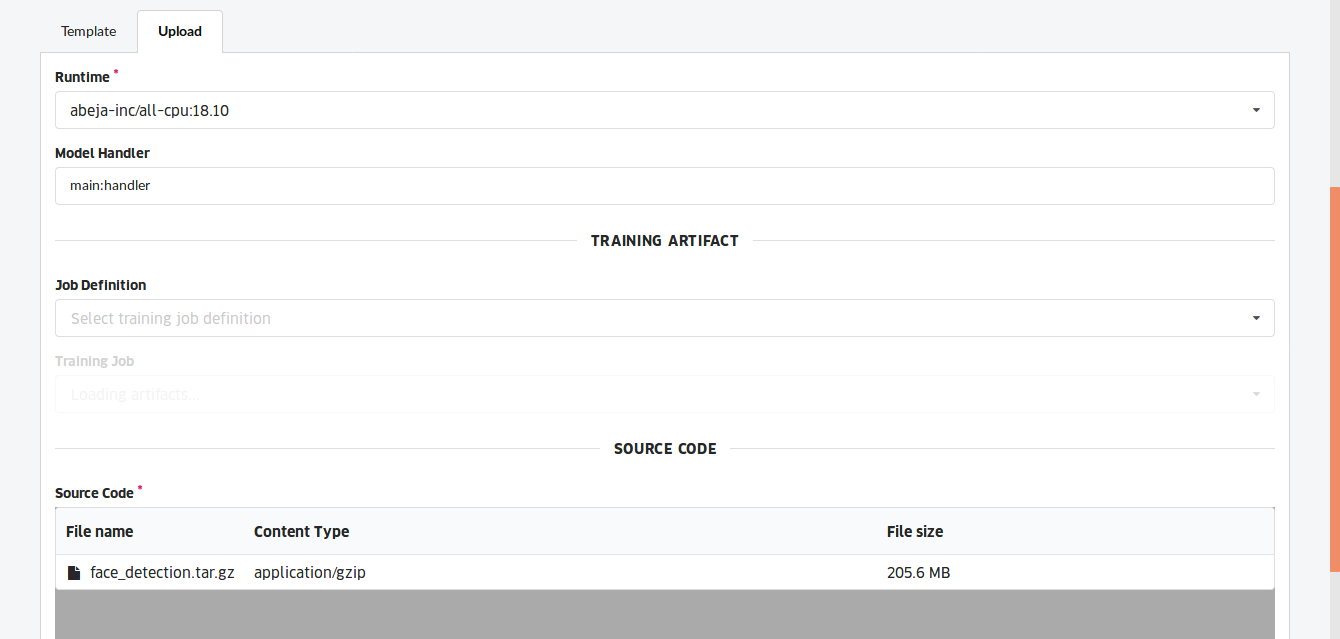
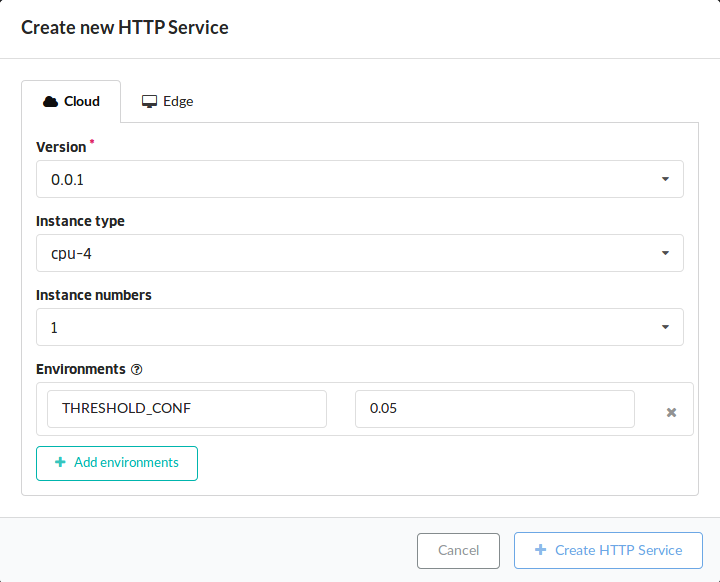
デプロイは以下の設定で行いました.PyramidBox のネットワークは大きくメモリ使用量も多いため cpu-4 を選択しました.また, PyramidBox のデフォルトでの顔検出の閾値は 0.15 でしたが,ソフトテニス画像ではさらにワイルドな状況でも検出したいという思いから 0.05 に変更しました.
検証
以下のようなクライアントプログラムを作成し,先ほどの画像で正しく顔が検出されるかを検証してみました.
import sys
import os
from io import BytesIO
import numpy as np
import requests
from PIL import Image, ImageDraw
if __name__ == '__main__':
# Load and encode image.
filename = sys.argv[1]
image = Image.open(filename)
buf = BytesIO()
image.save(buf, format='PNG')
# Send image to ABEJA Platform endpoint to detect faces.
ret = requests.post(
os.environ['ENDPOINT'],
auth=(os.environ['USER'], os.environ['ACCESS_TOKEN']),
headers={
'Content-Type': 'image/png'
},
data=buf.getvalue()
)
bboxes = np.array(ret.json())
# Draw result bounding boxes.
draw = ImageDraw.Draw(image)
for bbox in bboxes:
if (bbox[0:2] > [0, 0]).all() and (bbox[2:4] < image.size).all():
draw.rectangle(bbox[0:4].tolist(), outline=(255, 0, 0))
output = 'output/' + os.path.basename(filename)
image.save(output)
画像に赤枠で描画されているのが検出された顔です.少なくとも僕の顔は正しく顔を検出することができているようです.この難しい状況下でも正しく検出できているのは驚きでした.

さらに他のシーンでも検証してみました.いい感じの結果です.


一方で,やはり失敗するシーンもありました.人間がやればもっとたくさんの顔を検出できるあたり,人間って流石だなぁと思います.

まとめ
既存の github のコードを数時間程度で ABEJA Platform にデプロイし,その精度を検証することができました.簡単な検証をするだけなら,確かにローカルマシンでも十分かも分かりませんが,今回のようにネットワークが大きいとローカルマシンではそもそもメモリ不足で動かなかったり,複数枚の画像を投げた時に Auto Scale してくれるので,検証が早く済んだりと ABEJA Platform にデプロイしておくメリットを感じました.
実際のビジネスの現場でも,いち早くビジネス効果検証をするために,既存モデルを使うことを往々にしてあると思います.そういった場合には,APIとしてデプロイしておくことで他システムとのインテグがラクになるメリットがあるので,ぜひとも使ってほしいなと考えています.
顔検出に関して言えば,PyramidBox でもソフトテニスの試合を正しく検証するにはまだまだ精度が低い部分もあるので,引き続き論文を漁りつつ,検証したりカスタマイズしたりして,より正しくソフトテニスを知る術を研究していきたいなと思います.