はじめに
最近,最近傍探索にハマっているのですが,マネージドで最近傍探索できるデータベースがあったら楽だなぁと思って調べてみたところ「Image Recognition at the Speed of Memory Bandwidth 」と見事に合致するサービスを見つけてしまいました.2017年にはすでにマネージドサービスが存在していたことに驚愕と若干の後悔をしつつ,コロナの影響で不要不急の外出ができず暇を持て余しているので検証してみることにします.
環境構築
マネージドサービスではありますが,機能を検証するためにローカルに環境を構築することにしました.具体的には docker で環境を構築できる方法 がドキュメントにあったのでそれに従い環境を構築しました.docker が無事に起動すると,localhost:8080 から MemSQL Studio という管理 UI が見えるようです.
テーブル作成
上記の記事 に従い,特徴量とその ID をカラムに持つテーブルを作成します.ここでの注意点は2017年時点では特徴量は BINARY 型だったようですが,2020/4/19現在では BLOG 型を使わないとエラーになりました.なお,検証したのは 512 次元の特徴量だったため,次元が比較的小さい場合には BINARY 型でも動作するかも分かりません.
memsql> CREATE DATABASE test;
Query OK, 1 row affected (3.49 sec)
memsql> use test;
Database changed
memsql> CREATE TABLE features (id BIGINT PRIMARY KEY AUTO_INCREMENT, feature BLOB);
Query OK, 0 rows affected (0.18 sec)
正しくテーブルが作成されると,管理 UI からテーブル定義を確認することができるようです.

動作確認
まずは簡単な例でちゃんと動くかを検証します.問題設定としては,すでに単位円周上に3点 $(1, 0)$, $(0, 1)$, $(\cos\frac{\pi}{4}, \sin\frac{\pi}{4})$ があった時にクエリ $(\cos\frac{\pi}{6}, \sin\frac{\pi}{6})$ の最近傍2点を探す問題を考えます.
MemSQL には python クライアント memsql/memsql-python があるようなので,それを使うことにしました.また,公式ドキュメント によると The vector is then converted to a binary string representation. Finally, the resulting vector is hex encoded: と直接は INSERT できないようなので hex(x) という関数を定義することにしました.
以上まとめると動作確認用のコードは,
import struct
import numpy as np
from memsql.common import database
def hex(x):
return b''.join([struct.pack('f', e) for e in x]).hex()
# Prepare data points.
xb = [
np.array([1, 0]),
np.array([0, 1]),
np.array([np.cos(np.pi / 4), np.sin(np.pi / 4)])
]
xq = np.array([np.cos(np.pi / 6), np.sin(np.pi / 6)])
# Connect to MemSQL.
conn = database.connect(host='127.0.0.1', port=3306, user='root', password='', database='test')
# Insert data points.
for x in xb:
res = conn.query(f'INSERT features (feature) VALUES (UNHEX("{hex(x)}"))')
print('inserted rows:', res)
# Search top 2 similar vectors.
res = conn.query(f'SELECT id FROM features ORDER BY DOT_PRODUCT(feature, UNHEX("{hex(xq)}")) DESC LIMIT 2')
print('search results:', res)
実行すると以下のように $(\cos\frac{\pi}{6}, \sin\frac{\pi}{6})$ に一番近いのが $(\cos\frac{\pi}{4}, \sin\frac{\pi}{4})$ で,次に近いのが $(1, 0)$ と正しい結果を得られているようです.
inserted rows: 1
inserted rows: 1
inserted rows: 1
search results: [Row({'id': 3}), Row({'id': 1})]
性能検証
動作確認の結果から最近傍探索が SQL のように書けることが分かりました.そこで性能についてはどうなのかという観点を確かめるため,データ点数を $10^4$ から $10^5$ へ増やしていった際の search の性能を以下のようなコードを用いて測定しました.なお,動作確認時には1行ずつ insertしていましたが,今回は bulk insert をしてみています.
import logging
import struct
import sys
import time
import numpy as np
from memsql.common import database
from pythonjsonlogger import jsonlogger
def generate_random_vector(d, N=1):
x = 1 - 2 * np.random.rand(N, d).astype(np.float32)
x = x / np.linalg.norm(x, axis=1)[:, np.newaxis]
return x
def hex(x):
return b''.join([struct.pack('f', e) for e in x]).hex()
if __name__ == '__main__':
# Setup logging.
logger = logging.getLogger(__name__)
formatter = jsonlogger.JsonFormatter('(levelname) (asctime) (pathname) (lineno) (message)')
handler = logging.StreamHandler(sys.stdout)
handler.setFormatter(formatter)
logger.addHandler(handler)
logger.setLevel(logging.INFO)
# Prepare constance variables.
d = 512
Nb = int(1e5)
k = 5
xb = generate_random_vector(d, Nb)
# Connect MemSQL.
conn = database.connect(host='127.0.0.1', port=3306, user='root', password='', database='test')
# Gradually increase index features.
total = 0
for xb_i in np.split(xb, 10):
bulk = ', '.join([f'(UNHEX("{hex(x)}"))' for x in xb_i])
total += conn.query(f'INSERT features (feature) VALUES {bulk}')
# Search similar vectors.
for i in range(1000):
xq = generate_random_vector(d)
start = time.time()
conn.query(f'SELECT id FROM features ORDER BY DOT_PRODUCT(feature, UNHEX("{hex(xq[0])}")) DESC LIMIT {k}')
elapsed = time.time() - start
# Log performance.
logger.info('finish one iteration.', extra={
'Nb': total,
'try:': i,
'elapsed': elapsed
})
どうせ性能をプロットするなら比較対象があった方がよいだろうと,個人的にデファクトな faiss での性能との比較を各1,000回ずつの施行を平均化してプロットしました.なお,アルゴリズムによる差異をなくすため faiss でも厳密探索をしています.
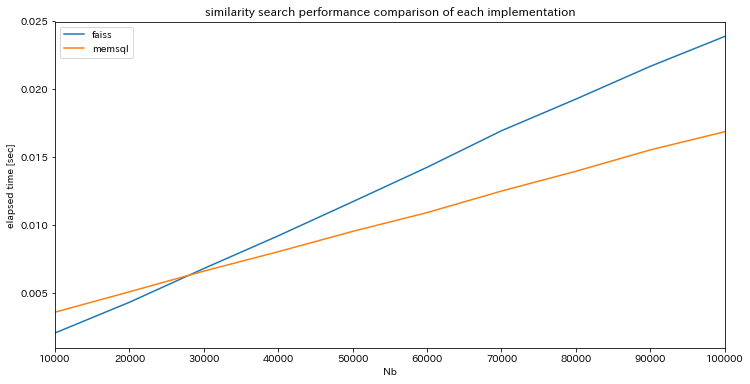
今まで圧倒的1強状態だった faiss を凌ぐ性能をマークしました.今回は docker を用いた簡易な検証でしたが,それでも faiss を凌ぐ結果を得たことには驚きです.マネージド版をちゃんと使った時に性能がどうなるかは楽しみです.
まとめ
SQL で最近傍探索ができる MemSQL の docker 版を検証してみました.SQL Like に最近傍探索を書けるのは純粋に驚きでした.これなら他のクエリと合わせて非常に高度な検索もできそうで夢が広がります.また,性能に関しても faiss と同等をマークしたことは驚愕です.
ただ,当然と言えば当然かも分かりませんがサポートしているトランザクション分離レベルが READ COMMITED (cf. https://docs.memsql.com/v7.0/introduction/faqs/memsql-faq/#what-isolation-levels-does-memsql-provide) だけなのは残念でした.アプリケーション側である程度整合性は担保してやらないといけなそうです.
とはいえ,非常によくできたサービスだなぁと思いました.もっと早くに出会いたかったです.まぁちょっと高いので実際に使うかは微妙ですが笑