目標
全く更地の状態、しかもfluentdもESもなんとなくしかわかってない状態から、どうにかKibanaでリソース監視Dashboardを作るまでこぎつける。
同じことをやっている記事はいっぱいあるので、fluentdとESをよくわかってない状態で始めようとして躓いたポイントを中心に手続き的に。
太字になってるところがわかりづらい点・注意を要する点・推奨する内容。
参考
- 公式:
- http://blog.nomadscafe.jp/2014/03/dstat-fluentd-elasticsearch-kibana.html
- http://nsrzakki.hateblo.jp/entry/2015/08/02/031315
- ほかにもいっぱい
![]() Tips! fluentdとESに関しては、困ったらまず公式Doc! これ鉄則だと思う。
Tips! fluentdとESに関しては、困ったらまず公式Doc! これ鉄則だと思う。
Disclaimer
- 「リアルタイム」というのは嘘。ごぬんね
- 触ってみるとわかるけどポーリング間隔は5秒が最小
- 毎秒とかやりたければパッチするのかな
用意するもの
-
dstatが使えるLinux(筆者はUbuntu) -
dstat-
apt-getなりyumなりで
-
-
td-agentv0.12.20- 上に同じ
-
elasticsearchv2.2.0- 上に同じ
-
kibanav4.4.0- バイナリDLしてきて解凍……でもいいが、
- 筆者は気づかずに進めてしまったのだが、
apt/yumレポジトリもある- こちら参照
ESとKibanaはバージョンの互換性に注意が必要。Kibana4.4はES2.2以降を要求する。
dstatってなんだ
こういうもの
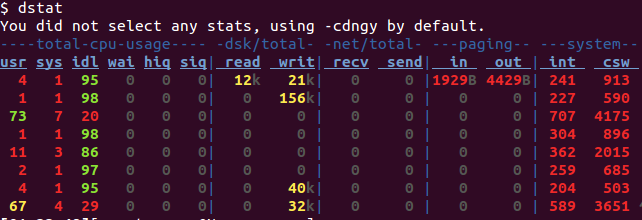
リソースの状況をひたすら吐き出してくれる。ひたすら便利。
便利だし、これをfluentdに流し込むpluginが公開されている。
fluent-plugin-dstat
ということで入れる。td-agentでプラグインを入れるときはtd-agent-gemコマンド。
$ sudo td-agent-gem install fluent-plugin-dstat
Successfully installed fluent-plugin-dstat-0.3.1
1 gem installed
sudo apt-get経由でtd-agentを入れた場合、何もしないとその後もsudoが必要になる。
td-agentそれ自体はtd-agentユーザで実行されるので、rootではない。
fluent-plugin-elasticsearch
ついでにelasticsearchにデータを流しこむためのプラグインもいれておく。
$ sudo td-agent-gem install fluent-plugin-elasticsearch
fluentd(td-agent)の設定
そもそもfluentdって何するの?
=> sourceつまりデータ発生源から、決めた方法で決めた行き先にデータを流し続けるよ。
起動するだけなら$ sudo service td-agent startで一発だが、当然設定しないと意味がない。
/etc/td-agent/td-agent.confをroot権限で開く。
source
<source>
type dstat
tag dstat.__HOSTNAME__
option -cmdgn
delay 3
</source>
まずはsource。
さっきdstatプラグイン入れたので、dstatがtypeに使える。
typeは入力の種類。
こう書くと、td-agentが「dstatにoptionを渡して実行した結果」を入力としてくれる。
-
typeにはほかにtailとかforwardとかがある-
tailはそのまんま、既存のファイルの尻から吸い出す。当然ファイル指定が必要 -
forwardはポートを開いてそこで外部からのPOSTを受け取る。よってポート指定が必要
-
tagが非常に重要。
要はsourceから吸ったデータに意味のある識別子を与える。
上ではdstat.hostnameという形になる。__HOSTNAME__というプレースホルダでホスト名を代入できるのはrewrite-tag-filterプラグインの機能で、td-agentにセットでついてくる。
dstatのオプションについては色々試してみよう。delayは3秒毎に出力の意。
match
ここからがややこしくなる。
分かりやすかった参考記事はこちら
matchディレクティブは入力をどう扱うか決める要の設定。
こんな感じになる。
<match dstat.**>
type copy
<store>
type elasticsearch
host localhost
port 9200
logstash_format true
logstash_prefix logstash
type_name dstat
flush_interval 20
</store>
<store>
type file
path /tmp/fluent.dstat.log
</store>
</match>
<match pattern>この書式で、patternの部分に対象としたいsourceのtagパターンを入れる。
だからここで的確に取捨選択できるよう、tagを設計する必要がある。とりあえず最初は適当でもいいけど。
パターンにはワイルドカード*や**が使える。詳細はDocで。
-
matchは上から順に評価して、最初にマッチした設定を使う -
同じパターンの
matchを複数書いても、あとの設定は到達不可能- だから
copyが必要になる
- だから
こっちにもtypeがあり、データの扱い方を決める。
デフォルトでfileやforwardがあるほか、td-agentのおまけで色々ついてくる。
copyはその一つで、複数出力先に分岐できる。出力先はstoreディレクティブで指定。
storeディレクティブの中身は、copyを使わないで書く場合にmatch直下に来る内容がそのまま入る。
さて、type elasticsearch。これもプラグインを入れたので使える。
詳しく見る前に先にESを起動しておこう。
Elasticsearch(ES)
ESは全文検索システムというやつだ。中で全文検索エンジンLuceneが動いている。
検索というとgrepがあるが、こいつは(多分)シーケンシャル。
つまり基本的には対象ファイルをズァーっと順になめてマッチをかける。
全文検索システムは違う。事前にインデックスを作る。**転置インデックス**というやつだ。
「検索される語がどのファイルに含まれているのか」という情報を予め調べあげておいて記録しておく。
だからいざ検索された時、即座に「はいこれとこれとこれね」と返せる。
こちらはAPI経由で設定からデータ入力から検索から全て行うことになるので、とりあえず起動すればいい。
$ sudo service elasticsearch start
デフォルトポートは9200、そのままでOK。
設定は後回しにする。
ふたたびtd-agent.conf
<match dstat.**>
type copy
<store>
type elasticsearch
host localhost
port 9200
logstash_format true
logstash_prefix logstash
type_name dstat
flush_interval 20
</store>
<store>
type file
path /tmp/fluent.dstat.log
</store>
</match>
戻ってきた。typeからportまでは自明だ。
もう一つのstoreのfileの方も自明だ。
pathで指定したファイルにもデータを流し込んでいるということ。
とりあえず動いていることを確認するには最適だ。
が、まだ動かさないほうがいい。
とりあえず動かしてみたいなら、
<match dstat.**>
type copy
<store>
type file
path /tmp/fluent.dstat.log
</store>
</match>
これで。つまりES部分は「待った」。
ES設定に戻り、logstash_formatの部分。
Logstashというのはfluentdとはまた違うデータ転送エージェントで、ここではフォーマットをそちらに合わせるということ。
ESとKibana、Logstashは今Elastic社というESやLuceneを開発していたメンバが集まって作った会社が強力にバックアップしており、親和性が高い。
logstash_prefixもデフォルトのlogstashを使うのが早い。
type_nameを理解するにはESにおけるIndexとTypeを理解すればよい。おすすめの参考記事はこちら。
Typeは要はIndexの中のグループみたいなもの。Databaseに対するTableみたいなものと思っておけばいい。ここではそれにdstatと名前をつけた。
index_nameも指定できるのだが、Logstashではlogstash-YYYY.MM.DDという名前で1日1インデックスが自動で作成されるので、ここでは意味が無い。
実はLogstash形式にはサポートが同じ会社という以外にもう一つ利点があるので後述する。
flush_intervalはデータ転送が実際に行われる間隔(秒単位)。デフォルトは60なので、起動後1分待たないと最初のデータがESに入らない。あまり早くし過ぎるとそのためにリソースが食われてしまうが、遅すぎてもリアルタイムっぽくなくて寂しい。
製品環境で使うならチューニングが必要なところだろう。ローカルなら5秒でも余裕。実務上はそこまで細かい必要ないので、30とか60とかか。
これでデータを流し込む側の準備ができた。
上記「とりあえず試す場合」をやってみるとわかるが、td-agentが実際に吐き出すデータはこうなっている。
2016-02-21T02:57:39+09:00 dstat.Naxxramas {"hostname":"Naxxramas","dstat":{"total_cpu_usage":{"usr":"51.186","sys":"1.017","idl":"47.797","wai":"0.0","hiq":"0.0","siq":"0.0"},"memory_usage":{"used":"3023953920.0","buff":"76234752.0","cach":"467513344.0","free":"576991232.0"},"dsk/total":{"read":"0.0","writ":"15018.667"},"paging":{"in":"0.0","out":"0.0"},"net/total":{"recv":"0.0","send":"0.0"}}}
2016-02-21T02:57:42+09:00 dstat.Naxxramas {"hostname":"Naxxramas","dstat":{"total_cpu_usage":{"usr":"27.027","sys":"4.730","idl":"68.243","wai":"0.0","hiq":"0.0","siq":"0.0"},"memory_usage":{"used":"2998079488.0","buff":"76251136.0","cach":"472776704.0","free":"597585920.0"},"dsk/total":{"read":"0.0","writ":"76458.667"},"paging":{"in":"0.0","out":"0.0"},"net/total":{"recv":"0.0","send":"0.0"}}}
2016-02-21T02:57:45+09:00 dstat.Naxxramas {"hostname":"Naxxramas","dstat":{"total_cpu_usage":{"usr":"3.072","sys":"1.365","idl":"95.563","wai":"0.0","hiq":"0.0","siq":"0.0"},"memory_usage":{"used":"2996457472.0","buff":"76251136.0","cach":"467537920.0","free":"604446720.0"},"dsk/total":{"read":"0.0","writ":"0.0"},"paging":{"in":"0.0","out":"0.0"},"net/total":{"recv":"0.0","send":"0.0"}}}
<timestamp> <tag> <record JSON> これがゴールデンルール。
タイムスタンプとタグはそのまんまなのでいいとして、recordの中身が重要だ。
全てJSONで、ESに吐き出されるLogstash形式には@timestampやhostnameも自動で挿入される。
データを視るための準備: Kibana
Kibanaのインストール経路がどうであれ、ローカルに落としてきたkibanaバイナリを実行すれば少なくとも起動するはずだ。
自動起動したい場合はinitスクリプトの用意が必要。(筆者はまだやってない)
デフォルトでは5601ポートで待ち受ける。
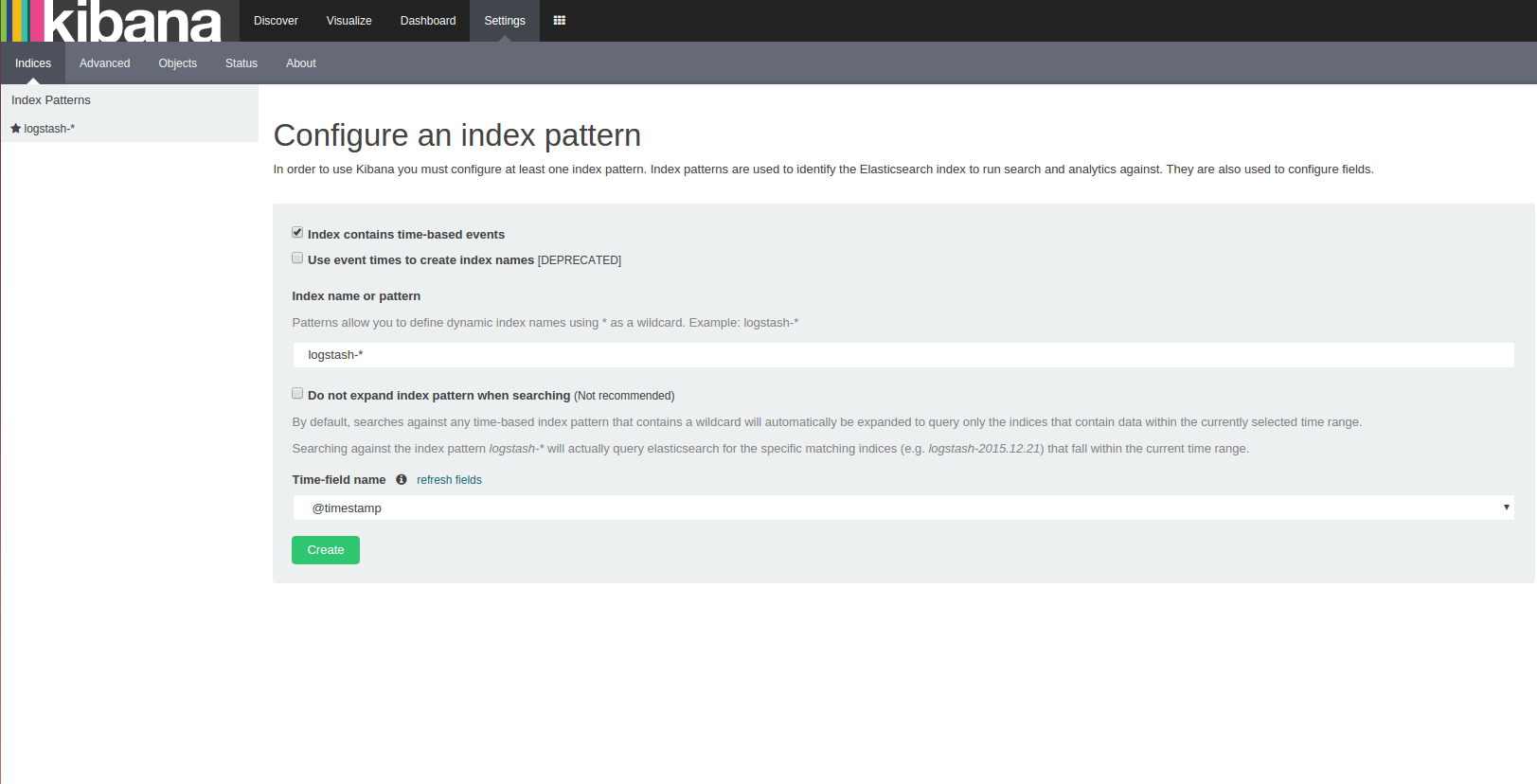
Elasticsearchが動いていれば接続され、上のような画面が出るはず。
この画面が言っているのは、「まだIndexが一つも指定されていなくて何を見たらいいかわからないから教えろ」ということ。
最初からlogstash-*というインデックスパターンがデフォルト値として待ち受けていて、我々としては好都合。
一瞬立ち止まって: Sense/ElasticHQ
Senseという、これもまたElasticの提供しているKibana用のプラグインがある。
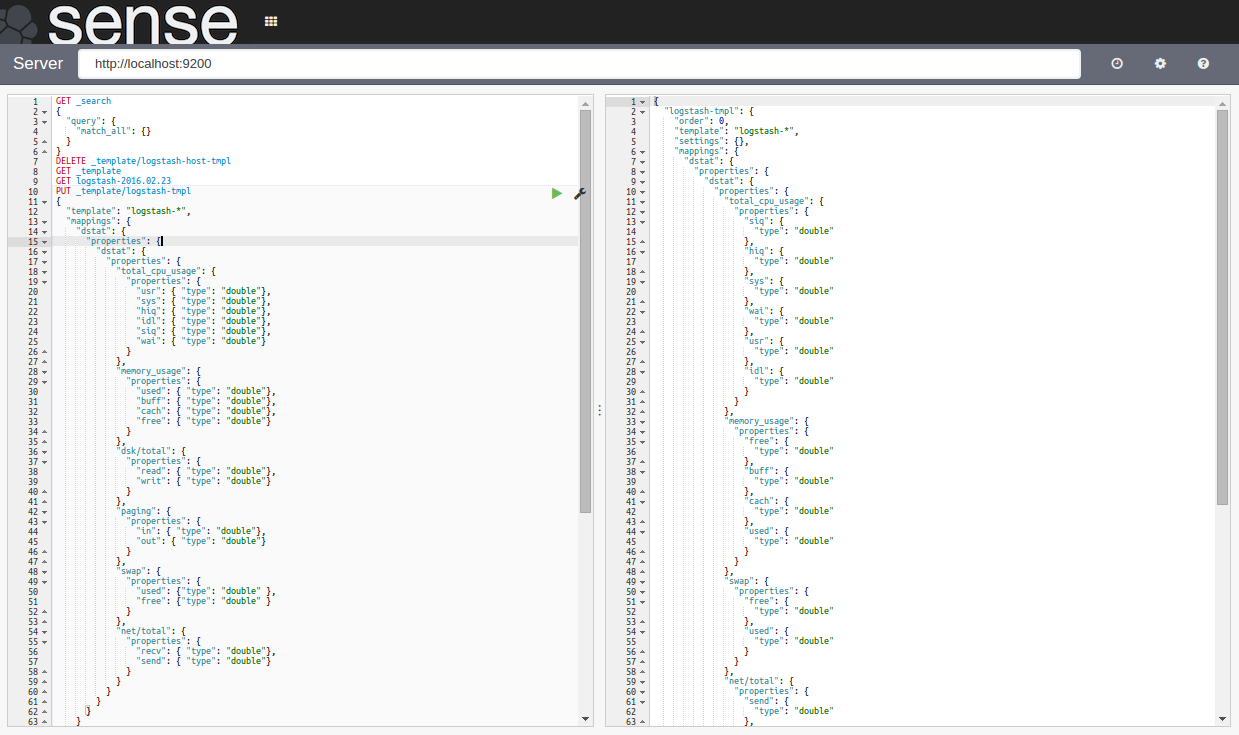
左半分で補完やコマンドヒストリーの恩恵を受けながらAPIコールし、右半分で結果をブラウズできるという、いわばElasticsearch用WebConsoleだ。
ぜひ入れよう。絶対入れよう。
ElasticsearchにはUIがない。全てはAPIコールだ。
つまりこういった補助具がなければ複雑な設定までcurlに頼ることになる。1
Senseは単純なUIではあるが存外洗練されており、
- 入出力JSONは自動整形されるし、
- シンタックス(?)ハイライトもあるし、
- Enter改行、Ctrl(Cmd)+Enterでリクエスト送信と直感操作可能、
と行き届いている。普通に他業務でもcurlの代わりに欲しいくらいだ(ほかにありそうだけど)。
よりGUI的にESを管理したいなら、ElasticHQというのもある。
こちらはElasticsearchのプラグインで、エンドポイントも<es_hostname>:9200/_plugin/hq/。
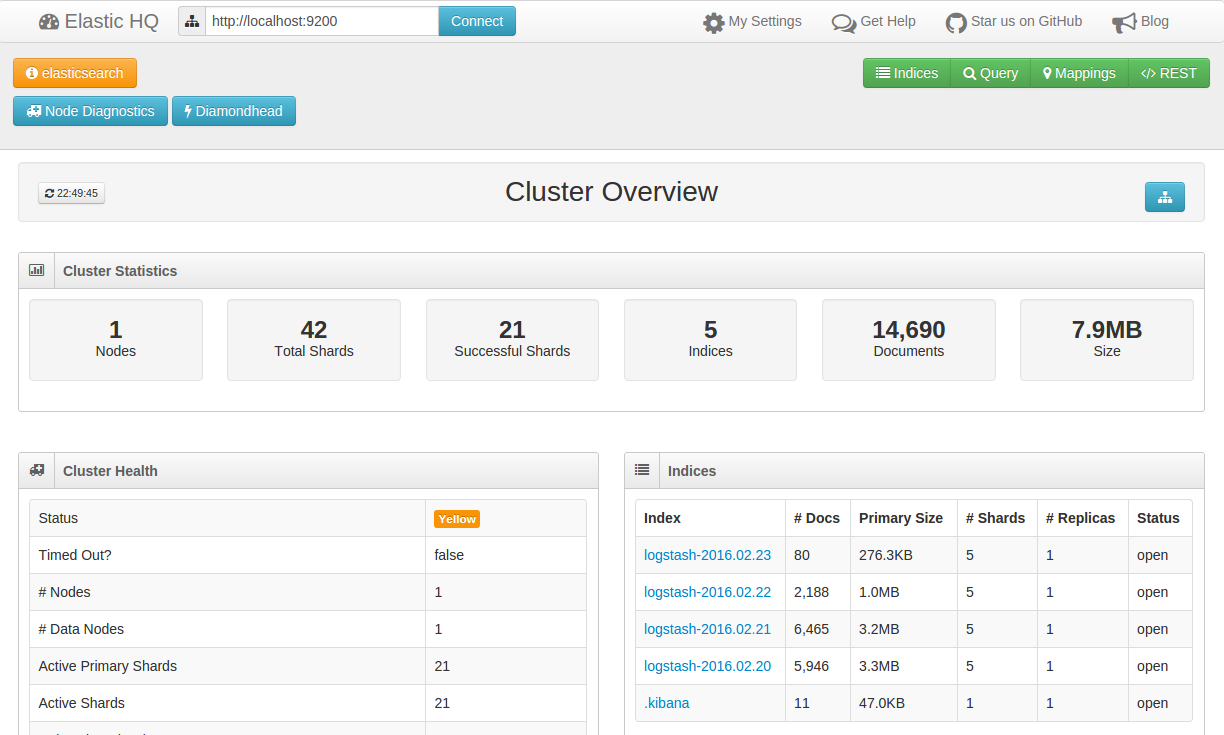
クラスタの状態監視等に重きをおくならこちらがいいかもしれない。
ヘルスチェックやリソースモニタがあるし、
実用性は疑問だが、クラスタ可視化機能もある。

こちらにもコンソール的なものがあるのだが、残念ながらSenseと違ってフリーインプットのコンソールではなく、対応したコマンドを送ることしかできない。
今のところ使い分けが必要。
ほかにelasticsearch-headというのもあったが、見たところUIがちょっと野暮ったいのでスルー。機能的にはHQ寄りのようだった。
Index Template
お待ちかね、インデックスの時間だ。
といったものの、fluentd_plugin_elasticsearchがLogstash形式のインデックスを勝手に作ってくれる。
ここまで設定が終わった状態でsudo service td-agent startすると、もうそれだけでESにデータが流れ始める。
が、特にMappingの設定を与えてないので、全ての値がAnalyzed Stringとしてマップされてしまう。
これが一旦起動を待ったほうがいい理由。まあ作ってしまったら削除すればいいのだが。
ちなみに、Mappingは要はスキーマだと思えばいい。JSONフィールドの値の型を指定し、StringであればAnalyzed(分かち書きあり)かNon-Analyzed(なし)かも選択できる。
dstatのデータはほとんど浮動小数点数なのでStringは不都合。ということでMappingを指定して制御したい。
ESでは_mapping/APIでこれを通常制御するのだが、Logstash形式では毎日新しいインデックスが作られる。
毎日Mappingを繰り返すのは現実的じゃないので、特定パターンの名前を持つインデックスに共通のMappingを適用するIndex Templateという機能を使う。
- Index Templateに対象IndexのMappingを指定して登録
-
td-agentを稼働させるとLogstash形式のインデックスが作成され、データが流れこむ。テンプレートに指定したマッピングがここで適用される - 深夜00:00に日が変わると、やはりテンプレートを元に翌日のインデックスが作成される
ここで、日ごとにインデックスが変わるというLogstashの利点が発揮される。
テンプレートを更新すれば、次の日のインデックスから自動で適用されるということ。
ESは膨大な入力データからせっせせっせと転置インデックスを作り続ける。
元となるインデックスの型情報が変更されると、それに合わせて転置インデックスは全て作り直しになる。
よって、既存インデックスの直接的なマッピング変更は認められていない(フィールドの追加は可能、更新は不可)。2
Index TemplateとLogstash形式を使っておけば、特別な設定なしに、1日未満のギャップで新規マッピングを適用できる。古いインデックスに対する適用は、必要ならバックグラウンドでやればいいし、必要なければ無視してしまえる。
ということで、さっと始めるにはLogstash形式はまあ適当かと。3
ここまで把握すればあとは見るのが早い。
PUT _template/logstash-tmpl
{
"template": "logstash-*",
"mappings": {
"dstat": {
"properties": {
"dstat": {
"properties": {
"total_cpu_usage": {
"properties": {
"usr": { "type": "double" },
"sys": { "type": "double" },
"hiq": { "type": "double" },
"idl": { "type": "double" },
"siq": { "type": "double" },
"wai": { "type": "double" }
}
},
"memory_usage": {
"properties": {
"used": { "type": "double" },
"buff": { "type": "double" },
"cach": { "type": "double" },
"free": { "type": "double" }
}
},
"dsk/total": {
"properties": {
"read": { "type": "double" },
"writ": { "type": "double" }
}
},
"paging": {
"properties": {
"in": { "type": "double" },
"out": { "type": "double" }
}
},
"swap": {
"properties": {
"used": { "type": "double" },
"free": { "type": "double" }
}
},
"net/total": {
"properties": {
"recv": { "type": "double" },
"send": { "type": "double" }
}
}
}
}
}
}
}
}
見ての通り、td-agentが出力するJSONの階層に合わせてpropertiesキーを挟んでネストしていき、末端のキーにたどり着いたところでtypeを指定するだけ。
mappingsキーの直下に来るのはType名で、それ以降がJSONrecordのキーであることに注意。わかりにくければtd-agent.confでtype_nameを別のにする。
キーの名前はfluentd-plugin-dstatの出力そのまま。
templateフィールドで対象インデックス名のパターンを指定したら完成。Senseコンソールから送信する。
{ "acknowledged": true }が帰ってくれば準備は完了。td-agentを起動する。
Kibana Visualization
flush_intervalで指定した秒数以上待てば、ESにデータが入るはず。
ここまでで既に起動してしまっていた場合、例のanalyzed stringでマップされた状態になってしまっているので、グラフ表示等が使えない。
まだデータが少ないので、一旦td-agentをstopして、インデックスを削除してやり直すのが早い。
DELETE logstash-YYYY.MM.DD
これをSenseから送信する(YYYY.MM.DDはやった日付を代入)。それからまたtd-agentを再起動。
正しくデータが入り始めると、Kibanaで認識できるようになる。
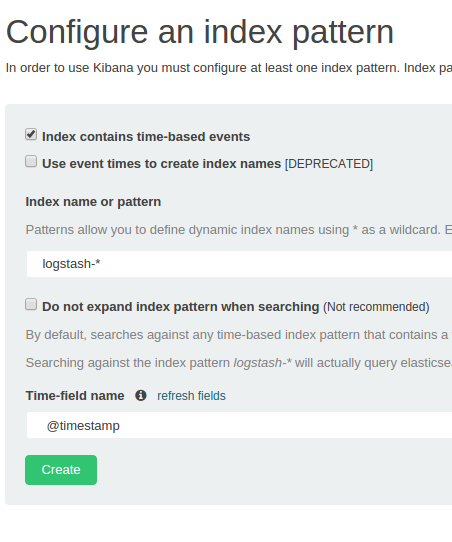
Index name or patternを指定した際に、Time-field nameに@timestampが読み込まれていればLogstash形式のインデックスが認識されているとわかる。この状態でCreateを押す。
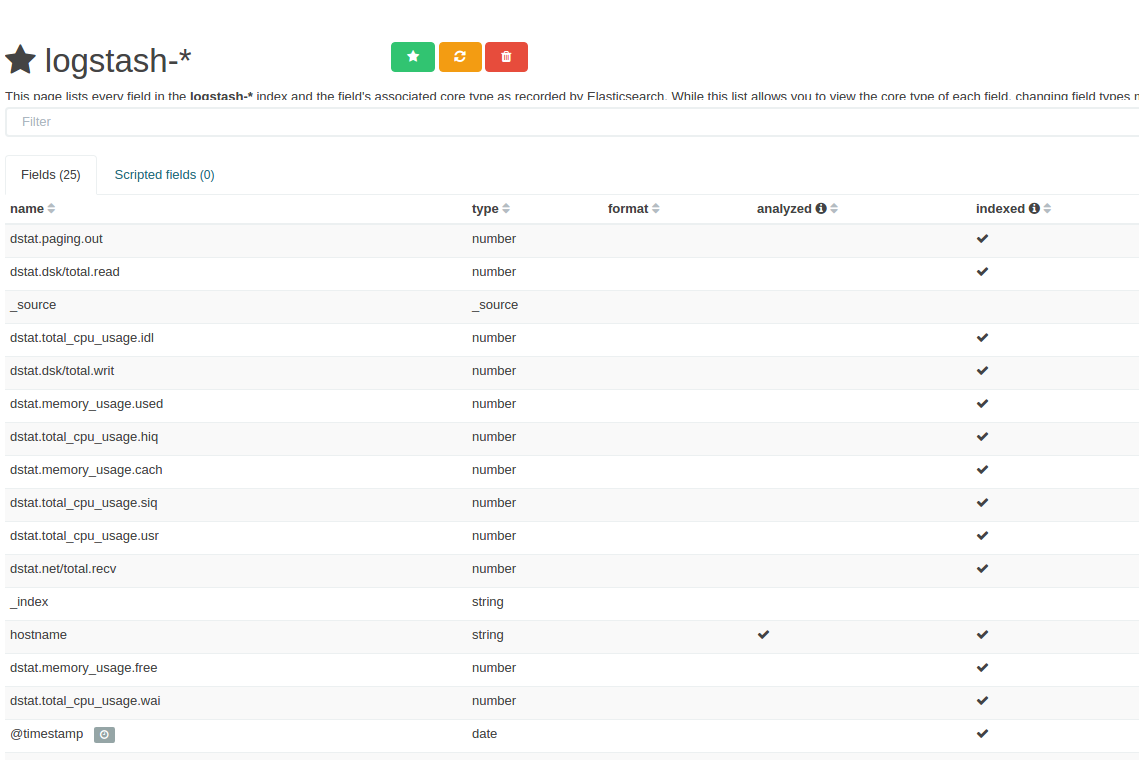
Typeが正しく認識されて、Indexが検索可能になった。
あとの操作は結構直感的なので、大して説明も必要ないと思う。
- Visualizeタブに行き、適当なグラフを選ぶ
- "From new search"でエディタを開く
- Y-axis/X-axisを適当に設定。例えば以下
- Y-axisのAggregationを"Average"にして、適当なフィールドを指定
- X-axisのAggregationを"Date Histogram"にして、フィールドは
@timestampでIntervalはauto
- 緑三角のボタンを押す
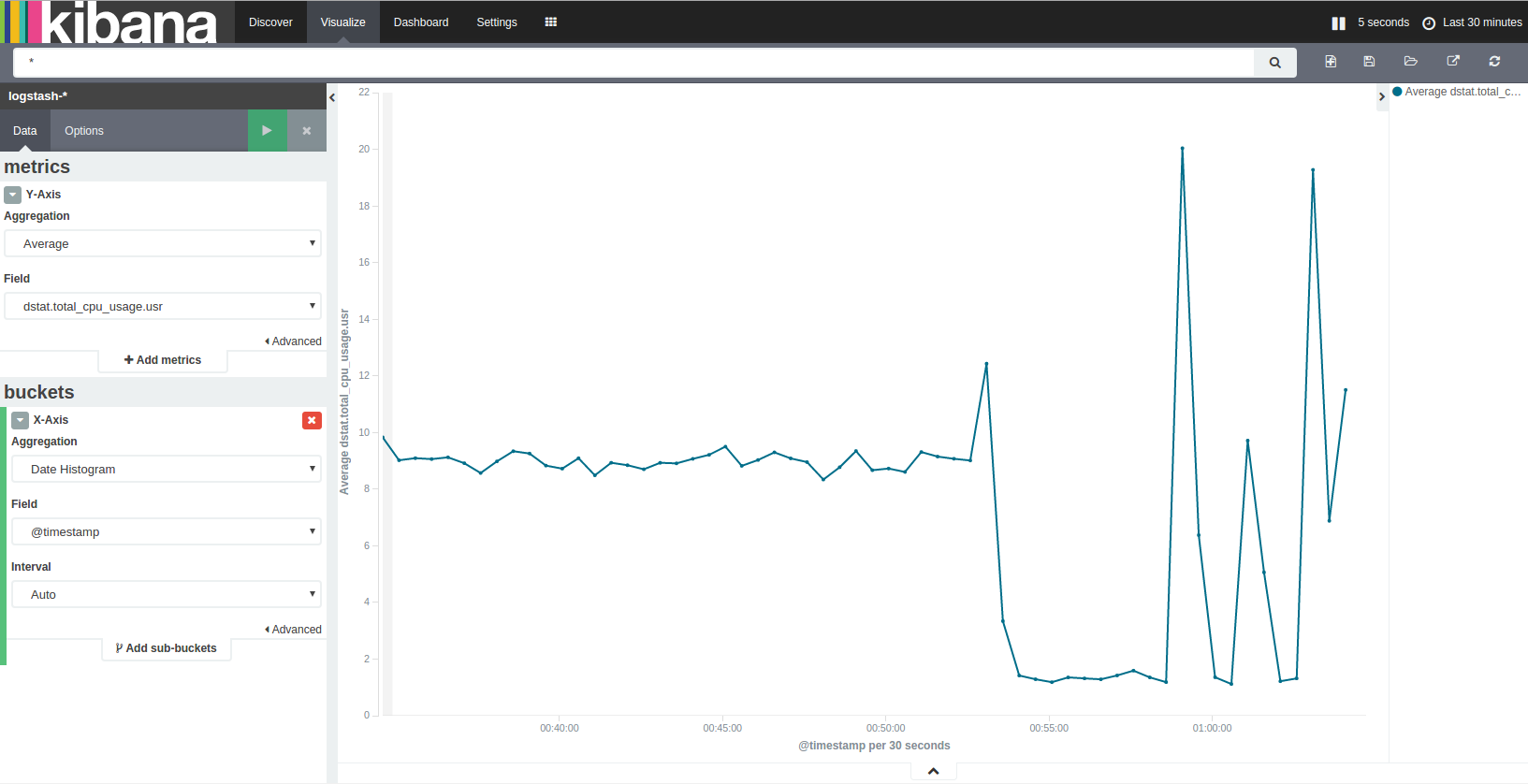
- 喜びを噛みしめる。やったね!
X-axisの"Date histogram"は時系列による区間頻度で、Intervalは区間の幅。
Y-axisのAggr.をAverageにしているので、表示されているグラフは「該当データの指定時間単位の平均値の推移」となる。
作ったグラフは右上のパレットで保存できる。
保存したグラフはDashboardに表示させることもできる。色々集めて可視化しよう。
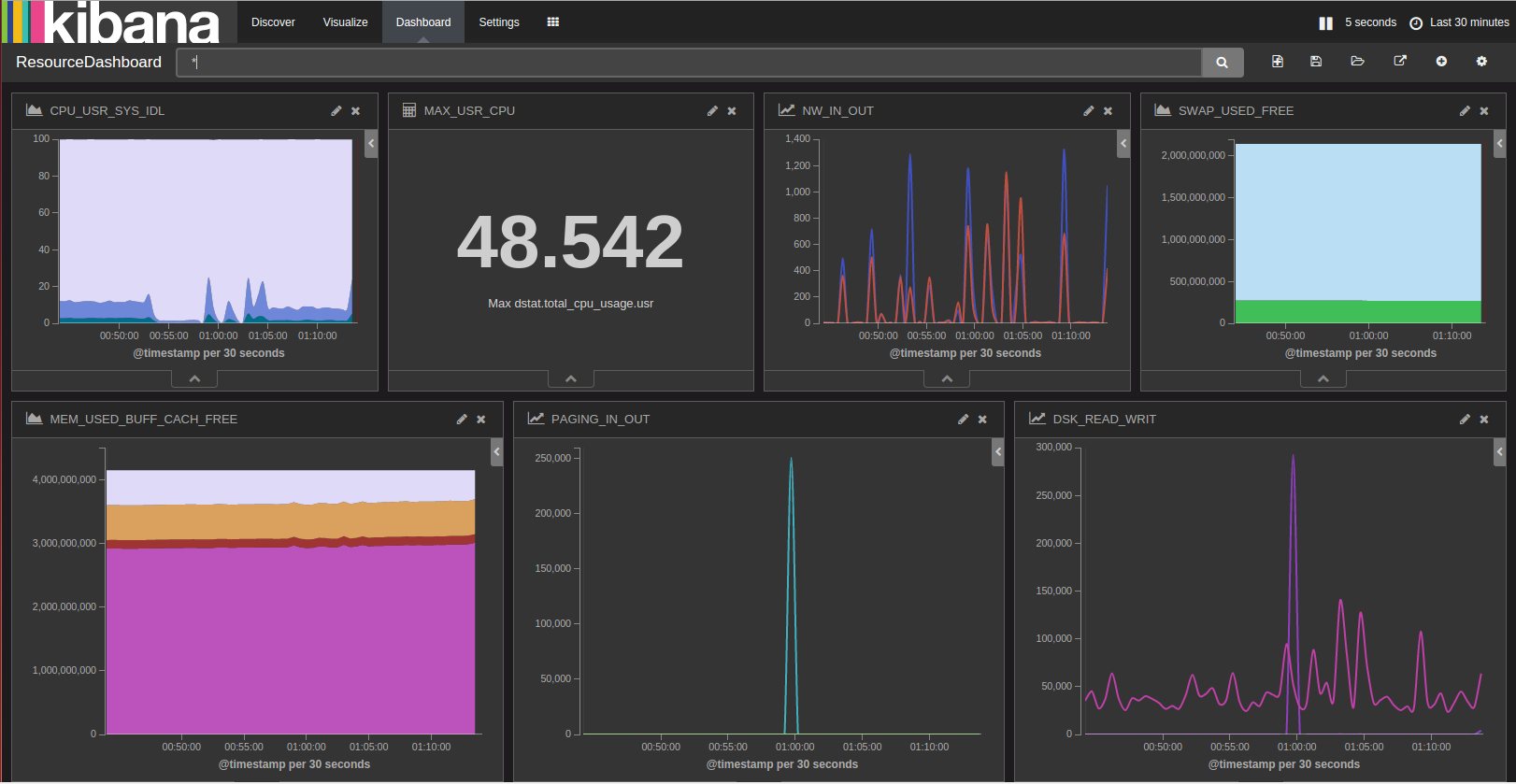
楽しくなってきた。
といったところでお開き。
いくつか補足:
- KibanaにもESにもアクセス制御機能はないので、置く場所は考える必要がある
- アラート機能もデフォルトではない
- ElasticのWatcherがあるが、やはり商用。elastalertというオープンソースはある
- 複数ホストを監視するなら、Visualizeの際にHostnameで検索をかければ良さそう
- 画面右上の時計アイコンからポーリングの設定ができる
- ずっと開きっぱにしているとブラウザのメモリがパンパンになっていくのは注意
Next Step
dstatをソースにリソース可視化までこぎつけることはできた。
あとは細かな体制整理とマルチホスト対応をすれば、チーム内で使うための監視ダッシュボードとしては使えそうだ。
次なるステップはアプリケーションログをパースしてリクエストパターンの可視化といきたいところ。
GeoLocationを使った地図上での可視化なんかも面白そう。
プラス、自前クラスタの管理運用あるいはAWS ElasticSearch Serviceの評価とか。
Elasticsearchを中心としてできること、身につく知識は幅広い。夢を見ていこう。