当エントリは2019年アドベントカレンダー『Looker Advent Calendar 2019』の6日目のエントリとなります。
今回は、**サンキーダイアグラム**というデータの流量を可視化するグラフをLookerで作る手順の紹介になります。
まず、データを準備
ECサイトなどで、**サイトのTOPページから商品購入に至るまでの顧客の行動順序をランダムに並べた感じのデータを用意しました。**オープンデータがあったら楽だったのですが、見つからなかったので、完全手作りです(スプレッドシートで頑張った)
行動の種類は、
1:TOPページ
2:商品説明参照
3:商品レビュー参照
4:類似商品参照
5:商品PV動画参照
6:商品購入
の6つを設定。
↓データはこんな感じで500件ぐらいランダムに生成
ID,step1,step2,step3,step4,step5,step6
157757,TOPページ,商品説明参照,商品レビュー参照,類似商品参照,商品購入,
212008,TOPページ,商品PV動画参照,商品レビュー参照,商品説明参照,商品購入,
318372,TOPページ,商品レビュー参照,商品説明参照,商品PV動画参照,類似商品参照,商品購入
699591,TOPページ,類似商品参照,商品購入,,,
945998,TOPページ,商品説明参照,商品PV動画参照,類似商品参照,商品レビュー参照,商品購入
265208,TOPページ,商品PV動画参照,商品レビュー参照,商品説明参照,商品購入,
772768,TOPページ,類似商品参照,商品購入,,,
311931,TOPページ,商品レビュー参照,商品説明参照,商品PV動画参照,類似商品参照,商品購入
477380,TOPページ,類似商品参照,商品説明参照,商品PV動画参照,商品レビュー参照,商品購入
〜 省略
項目定義は以下
・ID: 顧客のID情報
・step1: TOPページへのアクセス情報
・step2: TOPページから実行された情報
・step3: step2の次に実行された情報
・step4: step3の次に実行された情報
・step5: step4の次に実行された情報
・step6: step5の次に実行された情報
## IDはスプレッドシートのランダム関数を活用
=rounddown(rand()*1000000,0)
bigqueryにCSVでアップロード
CSVデータのアップロード手順はこちらを参考に
 ・`sankey_sample_looker`というテーブル名でbigqueryに取込み。
・`sankey_sample_looker`というテーブル名でbigqueryに取込み。
ProjectへViewを作成しLookMLを生成
LookerではテーブルをView形式に変換して可視化を行う為、必ずこの作業が必要。
 ・DevelopからDevelopmentモードにしてからProjectを選択
・DevelopからDevelopmentモードにしてからProjectを選択
 ・ProjectからCreate View From Tableを選択
・ProjectからCreate View From Tableを選択
 ・Create View From Tableで**Refresh**を押下し、`sankey_sample_looker` を選択しViewを作成。
→**現時点では、[Refreshを押下しないと追加テーブルが表示されない](https://qiita.com/ymto/items/f51ef1df04aace83ca18)ので注意**
・Create View From Tableで**Refresh**を押下し、`sankey_sample_looker` を選択しViewを作成。
→**現時点では、[Refreshを押下しないと追加テーブルが表示されない](https://qiita.com/ymto/items/f51ef1df04aace83ca18)ので注意**
↓これで以下のLookMLが自動生成される
view: sankey_sample_looker {
sql_table_name: {データベース名}.sankey_sample_looker ;;
drill_fields: [id]
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.ID ;;
}
dimension: step1 {
type: string
sql: ${TABLE}.step1 ;;
}
dimension: step2 {
type: string
sql: ${TABLE}.step2 ;;
}
dimension: step3 {
type: string
sql: ${TABLE}.step3 ;;
}
dimension: step4 {
type: string
sql: ${TABLE}.step4 ;;
}
dimension: step5 {
type: string
sql: ${TABLE}.step5 ;;
}
dimension: step6 {
type: string
sql: ${TABLE}.step6 ;;
}
measure: count {
type: count
approximate_threshold: 100000
drill_fields: [id]
}
}
ModelのExploreにViewを追加
 ・上記で作成した`sankey_sample_looker`のコードをModelに追加して保存する。
・上記で作成した`sankey_sample_looker`のコードをModelに追加して保存する。
# 追加コードは以下
explore: sankey_sample_looker {
}
これで、事前準備は完了!
サンキーダイアグラムの可視化
 ・Exploreから`sankey_sample_looker` を選択すると、編集画面へ遷移
・Exploreから`sankey_sample_looker` を選択すると、編集画面へ遷移
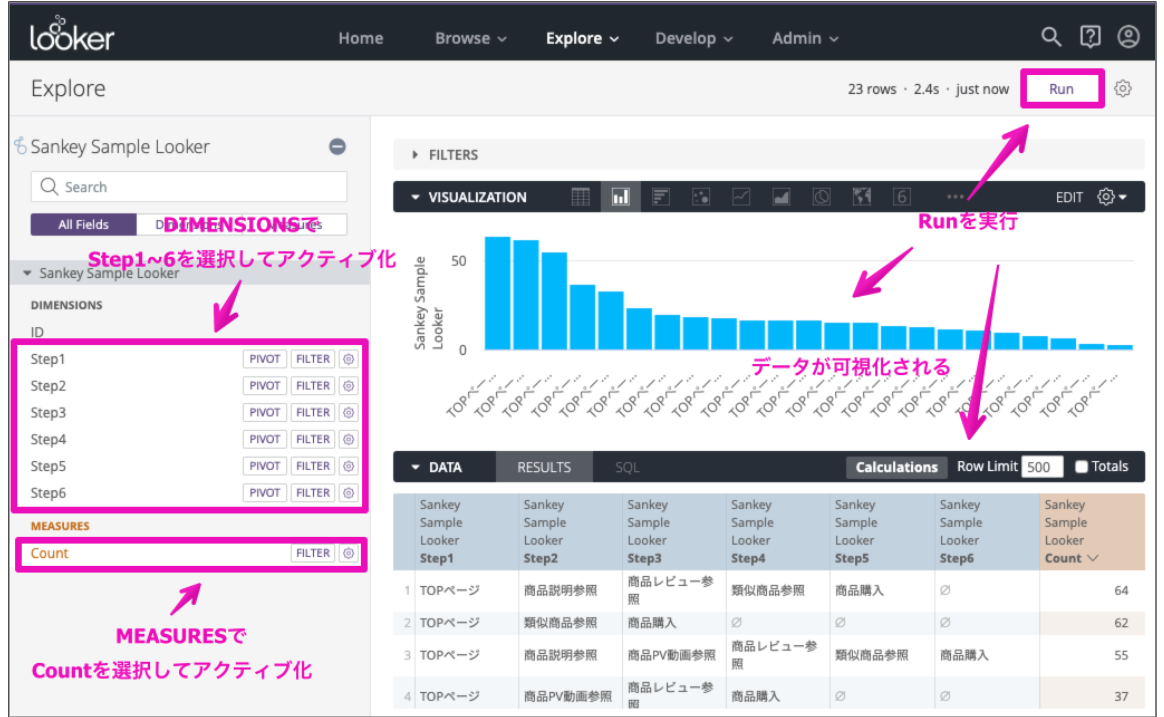
・DEMENSIONSからStep1~6を選択
・MEASURESからCountを選択
・Runを実行してVISUALIZATIONとDATAを可視化
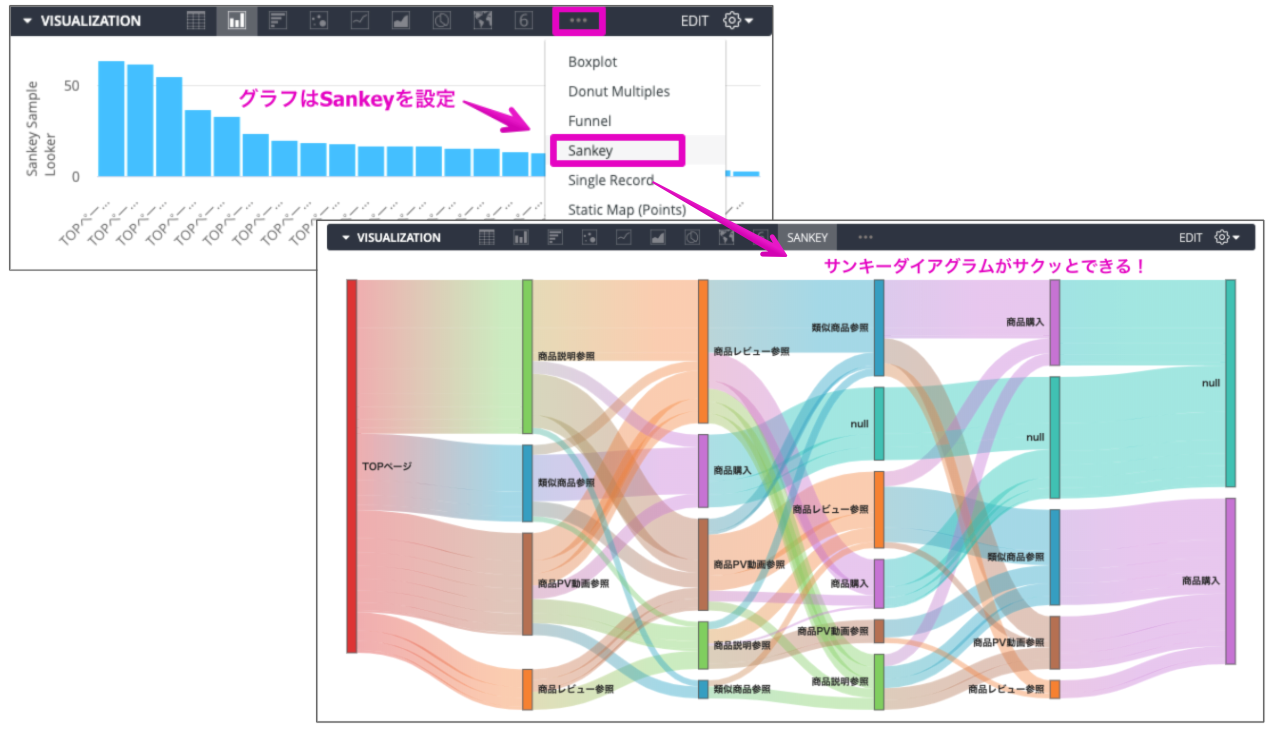 ・VISUALIZATIONのグラフ設定からSankeyを選択して完成!
・VISUALIZATIONのグラフ設定からSankeyを選択して完成!
補足1:グラフ設定にSankeyがない!?という方はこちらを参照
https://docs.looker.com/admin-options/platform/visualizations
・admin権限を持った管理者が追加可能です。
補足2:サンキーダイアグラムの設定オプション
EDITで以下のように、グラフ上に数値を出したり、Nullを除外したりできます。
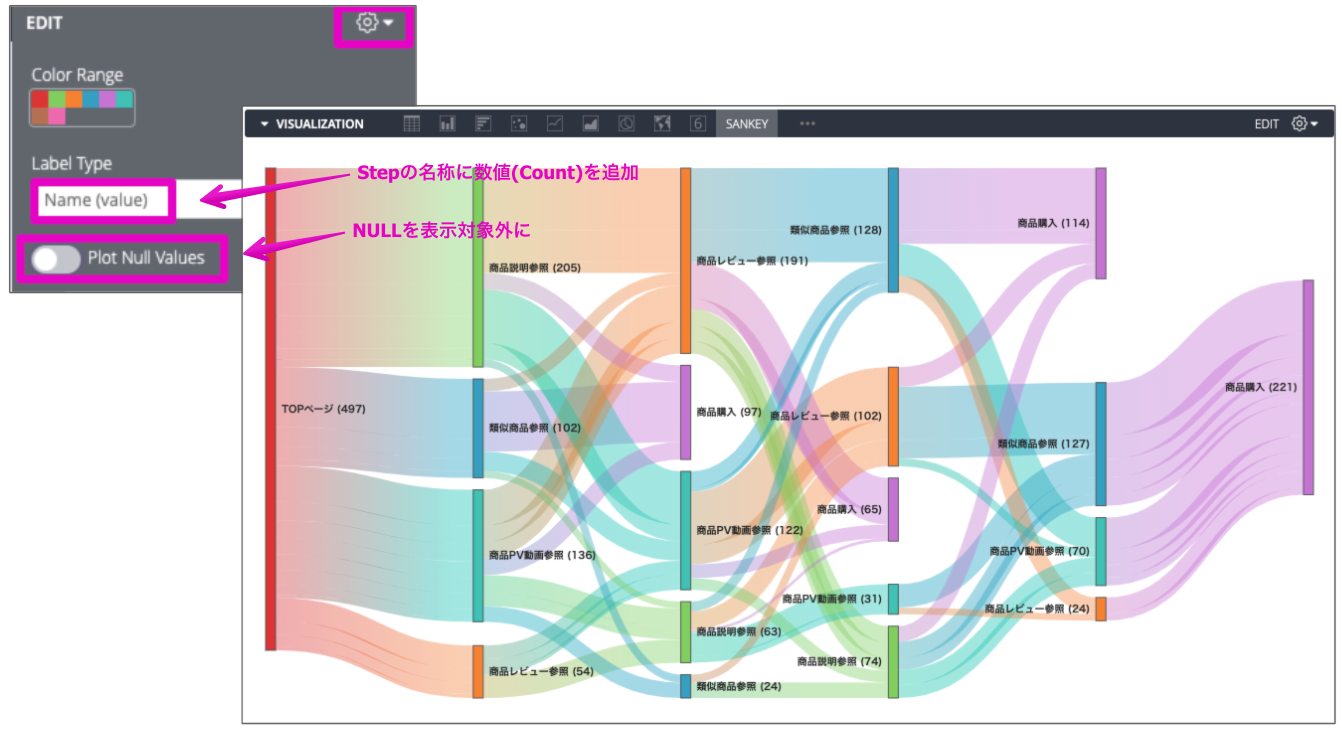
・Label Type: Name(value)→項目の名称の後ろに数値情報を表示
・Plot Null Valuesを選択解除→NULL表示を対象外にする
Lookerで可視化手順をまとめてみて
ブログに書いてみるとわかりますが、やはり可視化前の準備であるViewとModel、Exploreの設定など手順が多いところがLookerの大きな特徴だなと改めて感じました。この設定のおかげで、データガバナンスなどの管理面は業界でも最強に便利!!というのは大きなメリットと思います。
その一方で、この手間がより簡易に対処できるようになるともっとありがたい!!!とも感じられました。
徐々に、Lookerの利用企業が増えてきており、利用ユーザー数も伸びつつあると思いますが、そうなってくると機能の優秀さと同じぐらい、簡易性、利便性なども重視されてくるのではないかな?と