この記事は近畿大学Advent Calendar 2019の2日目の記事です.
研究室のサーバ障害対応を行った時に,原因の究明・対応を記録するための備忘録的記事を載せます.右往左往していたため,非常にお見苦しい点があるかもしれませんがご了承ください.
※この話はフィクションです.実在する人物・組織・設備等とは関係がありません.
TL;DR
- サーバの処理が止まったり止まらなかったりした
- いろいろ仮説を立てて対処してみた
- 結論: 直った
環境
- DeepLearningBox(Quadro GP100x4) 通称「ヤマト」
- NAS(QNap)
- DNS/NISサーバ
- YAMAHA RTX810
- Buffaloルータ:AP
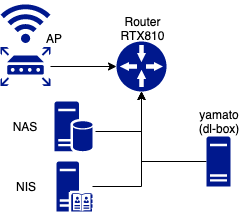
研究室の各サーバはNIS(Network Information Service)とNAS(Network Attached Storage)によって管理されていて,どのマシンにログインしても同じアカウント,同じファイルを操作することができるようになっている.
ディープラーニングの分野は様々なライブラリが存在し,バージョンの組み合わせ問題がある.その全てに対応できるようにするため,CUDA10.1, Nvidia-Docker2をインストールしている.対応するDockerイメージを用意すれば,どのマシンでも(マシンスペックが許せば)学習・検証が行える環境に整備している.
雰囲気で障害対応してみた
この章の対応の順番は実際に障害対応を行った時の順番です.
振り返るとガバが多分に入っていてだいぶヤバイんですが,正しい(と言われる)順序に戻すと記録にならないのであえてそのままにします.本来はもう少し丁寧に対応するべきです.
プロセス負荷を疑う
後輩A 「すみません,sshがヤマトに繋がらないんです...」
ぼく 「ほんまか??誰かが動かしてるプログラムが負荷かけててsshdが動いてないんじゃね」
後輩A「Grafanaで見るとヤマトのCPU100%, GPU99%になってますね...」
ぼく 「なんかsshdが落ちてるんやな, 学習が終わったら治るんちゃうか(無責任)」
後輩A 「わかりました!」
ぼく 「ほな学会行ってくるわ!!また来週!!」
この時は誰かのプログラムが重すぎて動かないだけだと思っていました.ネットワーク・サーバ管理を行う場合,どのレベルから対処を行うのか定め,アラートを設定し,モニタリングを行う必要があります.
今回はPrometheus+Grafanaで可視化していたので適当にやっていますが,「uptime」や「top」コマンドで確認しましょう.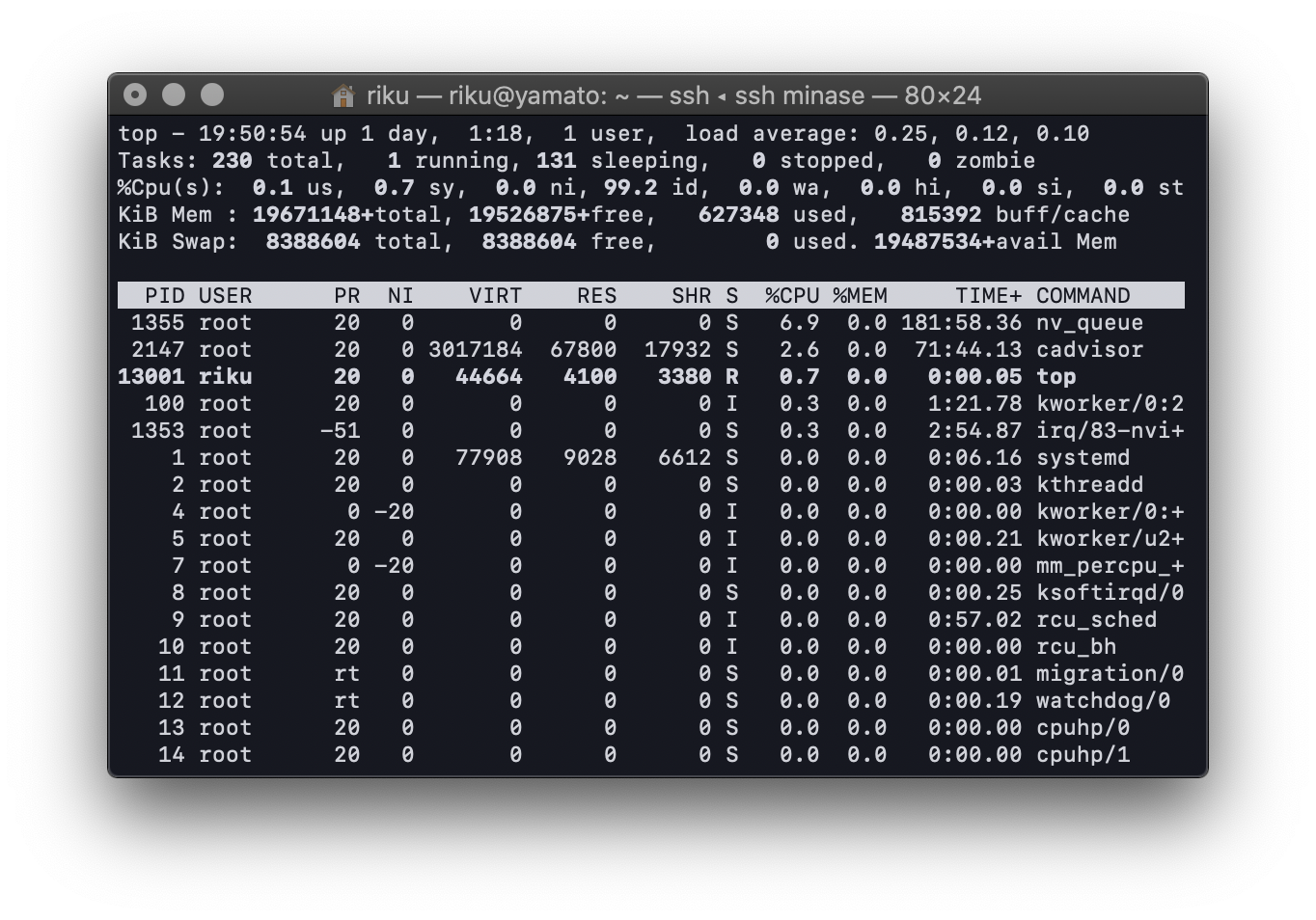
1行目の右側, load averageを見て数値が高かったらプロセスのせいだと思ったら良いと思います.低い場合は他に原因があります.
sshdを疑う
後輩A 「プログラム止めたんですけど,なんかsshが繋がったり繋がらなかったりするんですよ」
ぼく 「ほんまか??ディスプレイ繋いでローカルでsshdのサービスステータスみてみ??」
後輩A 「なんかActiveになってます!」
ぼく 「じゃあ大丈夫や!(適当)」
systemdのステータスを見て安心してしまいました.アプリケーションレイヤーでは問題なく表示されているかもしれませんが,他のレイヤーの問題がそのまま影響するわけではありません.問題と現状の認識が大切です.
$ service [サービス名] status

OSを疑ってクリーンインストールする
先輩「なんか壊れてるから直してや」
ぼく 「はい」
教授「大変らしいな,頑張ってや」
ぼく 「はい」
後輩B 「ローカルでコマンド叩いてるんですけど,フリーズして返事が帰ってこないんですよ」
ぼく 「ほんまか??うわっ!lsすら帰ってくるの時間かかるやん!壊れてるやんこれ...こわ」
ぼく 「なんか変な処理挟んでるんか?,とりあえずクリーンインストールするか(おい)」
ぼく 「サーバは全部Dockerで整備してあるからクリーンインストールも余裕やで(イキリ)」
...
ぼく 「コマンド実行クソ遅いな!再起動に30分て昭和のPCかよ!(平成生まれ)」
ぼく 「なおってないやん!!ナンデ!!」
ログを見るのがだるかったので,クリーンインストールを実行しています.慣れると設定に10分もかかりませんが,全くよくありません.問題を切り分けてから考えましょう.
ソフトウェアの問題の時,コンフィグを書き換えたかどうか,ある時点まで安定していたかどうかが手がかりになります.ヒアリングを行いましょう.
(というか,この段階でのクリーンインストールは早すぎます.最後にしましょう)
DiskIOを疑う
ぼく 「lsが帰ってこないのは,DiskIOが悪いのに違いない,SSDを換装しよう」
ぼく 「俺たちは雰囲気でサーバ管理をやっている」
...
ぼく 「なおらんやん,これやばいやん,サーバって学費4年分くらいやん」
uptimeコマンドやtop, htopコマンドでどの分野が問題かを知る手がかりを掴むことができます.
サーバの処理が遅くなる要因は様々ですが,物理的な要因だと大きく分けてDiskIO, RAM, Networkなどがあります. 実際にDiskIOを調べるには,vmstatコマンドを用います.
$ vmstat -d

メモリを疑う
ぼく 「このサーバ192GBもRAMがあるから障害の再現まで時間がかかる説があるんじゃないか!」
ぼく 「つまりメモリテストすればええんやな」
ぼく 「後輩よ...MemTest86でググってメモリテストや,頼んだで(移譲)」
後輩 「はい」
ぼく 「じゃ,TA行ってくるわ」
後輩 「はい」
Memtest86(https://www.memtest86.com/) は古来からあるメモリチェックツールです.USBメモリに書き込み,ブートすることで実行できます.RAMに特定のメモリパターンを書き込み,正しいかどうか読み込むという動作を全てのアドレス番地で行うため,RAMの不良を見つけることができます.パソコン自作勢はメモリの購入後Memtestを2〜3周かけ,初期不良がないかどうかを調べる人が多いようです.
NICを疑う
ぼく 「MemTest86は問題なく通ってしまった...メモリではない...」
ぼく 「じゃあNICやな(適当)」
ぼく 「その辺に落ちてるアダプタさして設定するで!!」
...
ぼく 「変わらんやんけ!!」
NICも電気信号が流れる立派な部品です.LANケーブルをシールドしてると良いらしいです(伝聞),たまに壊れたりすることがあります.「ping」コマンドで疎通確認できたらだいたい問題ないです(ガバ).
ネットワーク障害を疑う
ぼく 「研究室のサーバが多すぎて,ネットワークが定期的にパンクしてる説!」
ぼく 「(なんで他のサーバは健康に動いてるかは知らん)」
ぼく 「とりあえず,SNMPを読み取るprometheusのエクスポーターを自前で書いてセッティングや!」
ぼく 「YAMAHAルータならSNMP吐けるしネットワーク見れるやろ!!」
...
ぼく 「出来たけど通信は余裕ありそうやな...(DCと比べるな)」
ぼく 「結局なんもわからん」

問題解決を行うために試行錯誤するのはエンジニアとして正しい姿勢だと思いますが,
今回はすごい道を踏み外しているので絶対に真似をしてはいけません.
問題を切り分けるためなら,小さいネットワークを構築してテストするのが一番だと思います.
問題発見
ぼく 「結局なんもわからん」
ぼく 「arpテーブルでも眺めるか...ん..??」
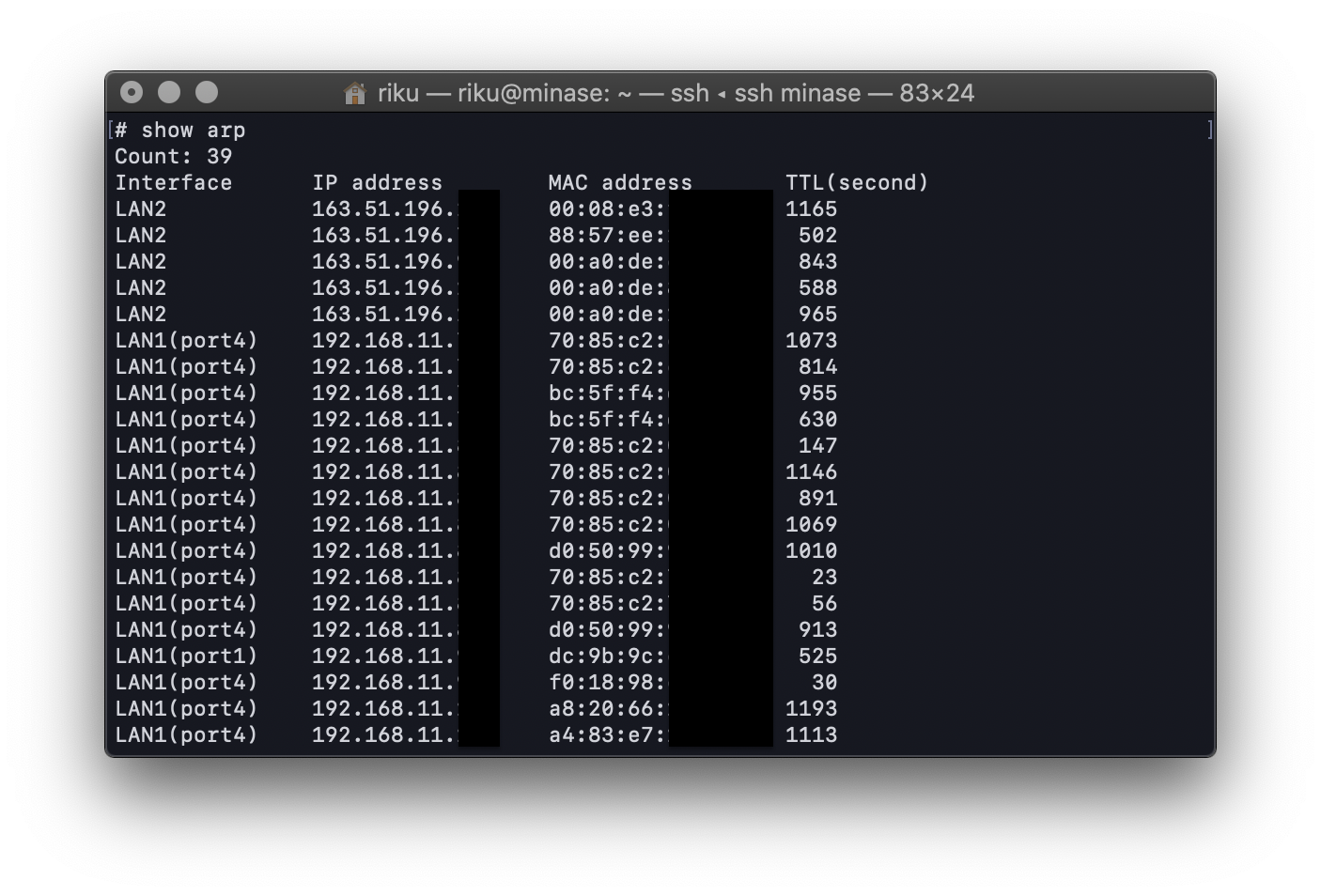
ぼく 「このレコード,IPアドレスはヤマトのIPなのに, MacアドレスはAppleのベンダーコードじゃない??おれ研究室に落ちてたAppleのEthernetアダプタ刺したよな??」
ぼく 「だれやこいつ!!」
MacアドレスはNIC毎に設定される一意なアドレスです.arpテーブルとは,IPアドレスに対応するMacアドレスを保存している場所で,パケット送信に使われます.今回,サーバのヤマトは「dc:9b:9c:XX:XX:XX」というMacアドレスのアダプタを指していたはずなのに,ルータのarpテーブルに記載されていたMacアドレスは別のアドレスでした.
ちなみに,Ubuntuでも「$ arp」コマンドでarpテーブルを見ることができます.
問題とはなんだったのか
- 先々週, ルータをAPモードに変更した
- APモードのコンフィグがRTモードとは別に保存されていた
- APモードではルータ本体のIPアドレスがヤマトと同じに...(誰だ昔設定した奴)
- IPアドレスの重複が発生!!
IPアドレスの取り合いになって通信が不安定になっていたことがわかりました.
(もっと早く疑え)
解決!!
ぼく 「研究室のみんな!IPアドレスの重複が原因やったで!!(あとSSD」
ぼく 「対策しといたからもう大丈夫や!」
ぼく 「(知らんうちに自分でIPアドレス被せてたということは黙っておこう...)」
どうすれば良かったのか
以下のフローは一般的に周知されている障害対応フローです.
- 障害を処理するための方針の決定
- 障害の原因を特定する(原因の切り分け)
- 適切な連絡先に連絡をする
- 障害が直ったことを確認する
- 障害が直ったことを関係者に通知する
- 何が問題なのか原因を専門家に相談して突き止める
- ドキュメント改定と再発防止策の検討を行う
しかし,そもそもの問題として,サーバの運用方針がなければ障害対応はうまく実行できません.
普段から運用・保守を考え,組織に合わせてガイドラインを策定することが重要になると思います(やるとは言ってない)
障害対応している最中はいろいろな物を疑っているので疑心暗鬼になり,非常にヤバイ精神状態になります.
これを職業としてやっている人は相当な精神力の持ち主か,サイコパスだと(ry
一方,問題が解決できたときの喜びはとても嬉しいものです(いや,自分のガバ設計ガバ運用が引き起こしたんやで)