はじめに
langchainのyoutubeに以下が投稿されました。
本記事はその要約記事になります。
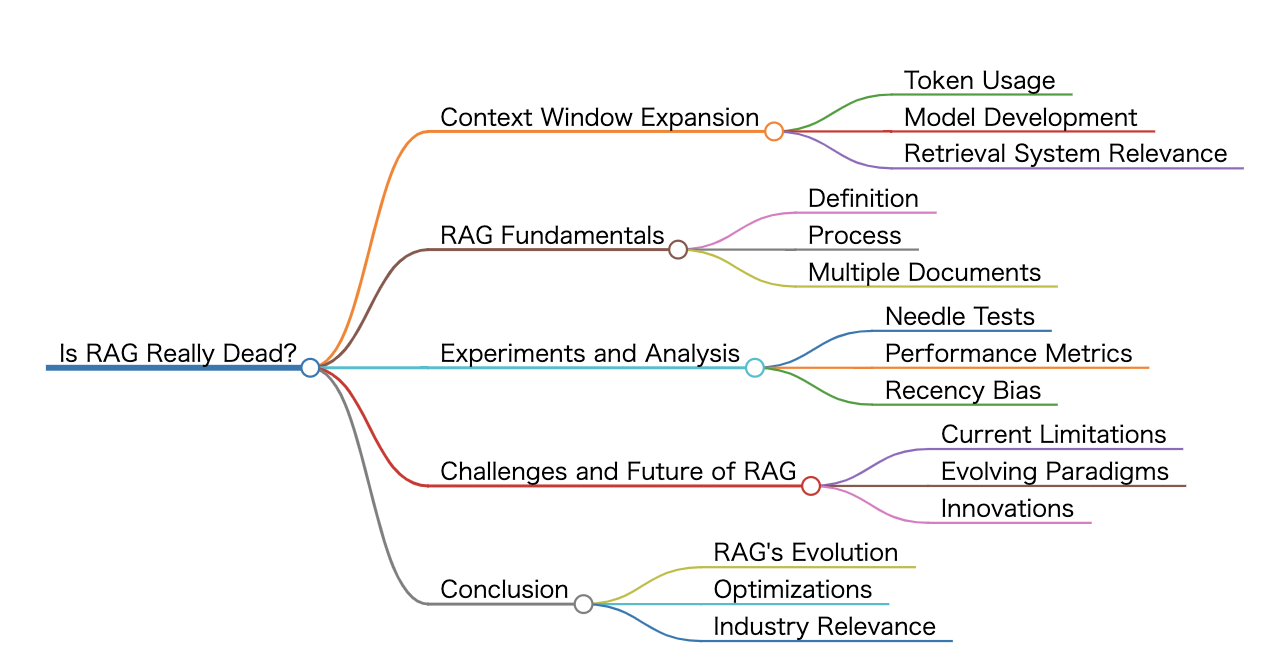
要約
導入
-
LLMのコンテキスト・ウィンドウはますます大きくなっており、独自のモデルでは2兆トークンを超えている。
一昔前の最先端モデルは4,000~8,000トークンを使っていたが、今ではクラウド3やジェミニのようなモデルは100万トークンを使っている。 -
LLMの大きなコンテキストウィンドウのために、RAGは終わったのではないかという疑問が生じる。
-
ランスは、グレッグ・キャメロンとチームを組み、大規模なコンテキストモデルにおけるマルチニードル検索と推論の有効性をテストした。
実験
- この研究では、ニードルが増えるほど、また推論が関与するほど性能が低下することがわかり、推論は検索よりも難しいことが示された。
- コンテキストの最初のほうにある針は、最後のほうにある針よりも検索が困難である。
- 長いコンテキストのLLMは検索を保証するものではなく、複数の事実や背景コンテクストに対する微妙さにはまだ課題がある。
結論
- RAGは滅びるのではなく、変化し、関連する文書群の正確な検索に焦点を当て、ロングコンテキストモデルと共に進化する。
- 文書中心のRAGは、チャンク化するよりもむしろ完全な文書に対して動作し、これは長いコンテキストモデルの体制ではより最適かもしれない。
- マルチプレゼンテーションインデクシングは、検索のために文書の要約をインデックス化し、最終生成のために完全な文書をLMに渡す手法である。
- Raptorは文書クラスタの階層的インデックスを用いる手法である。
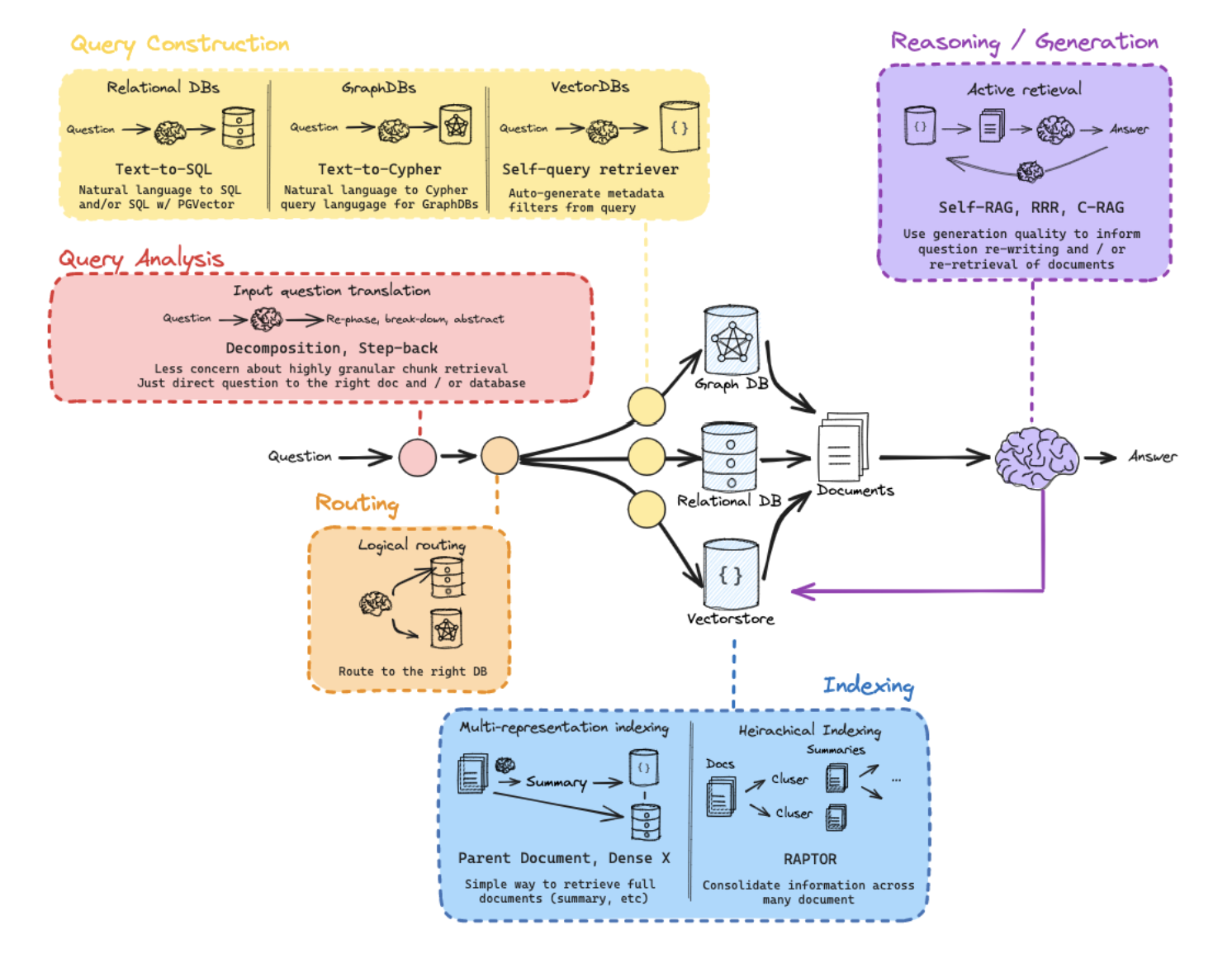
用語まとめ
Context Windows
文脈ウィンドウは、LLMsが一度に処理できるテキストの長さを指します。文脈ウィンドウが大きくなることで、モデルはより多くの情報を参照できるようになり、より正確な応答を生成することができるようになります。
Needle in Haystack
特定の情報(針)を、大量のテキスト(干し草の山)の中から正確に取り出すことができるかを評価するもの。言語モデルの情報検索能力だけでなく、文脈を理解し、関連情報を抽出する能力が試されるテストです。
Recency Bias
近接性バイアスは、モデルが生成時に最近のトークンにバイアスを持っていることを指します。これは、文脈ウィンドウの先頭にある情報が、末端にある情報よりも回復されにくくなくなることを意味します。
Multi-Representation Indexing
ドキュメントを複数の方法で表現し、それらをインデックスにして検索を最適化する技術です。この方法では、例えば要約のような表現を使用して、より正確なドキュメント検索を実現することができます。
Raptor
Raptorは、複数のドキュメントから情報を統合する技術です。この方法では、ドキュメントをエミューテッドして、それらを階層的にまとめ、最終的には一つの高度な要約を作成します。これにより、複雑な質問に対しても正確な回答を生成することができます。
Self-RAG
Self-RAGは、RAGプロセスを改善するための手法で、一度の検索之后就生成された回答を評価し、必要に応じて再生成する循环的なプロセスを指します。これにより、回答の品質を向上させ、誤った情報や欠如する情報の問題を解決することができます。
C-RAG
C-RAGは、「Corrective RAG」の略で、RAGシステムを改善し、検索インデックスの外側の情報を扱う能力を追加する技術です。この方法では、質問がインデックスの範囲外にある場合でも、ウェブ検索を実行し、最終的な回答を生成することができます。
Latency
Latencyは、処理の遅延を指す技術用語です。この動画では、長文脈のLLMsを使用する際のパフォーマンスと遅延のトレードオフについて議論されています。
Document-Centric RAG
ドキュメント中心のRAGは、検索システムがドキュメント全体を扱う際に使用されるRAGのアプローチを指します。この方法では、ドキュメントをチャンク化せずに、全文を検索と生成の過程で使用します。
参考資料まとめ
- RAG From Scratch: Part 1 (Overview)
- LLMTest NeedleInAHaystack
- Multi Needle in a Haystack
- ATTENTION SORTING COMBATS RECENCY BIAS IN LONG CONTEXT LANGUAGE MODELS
- RAG From Scratch
- Query analysis
- Dense X Retrieval: What Retrieval Granularity Should We Use?
- Multi-Vector Retriever for RAG on tables, text, and images
- Parent Document Retriever
- RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
- Building long context RAG with RAPTOR from scratch
- Introducing the Together Embeddings endpoint — Higher accuracy, longer context, and lower cost
- Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
- Building Corrective RAG from scratch with open-source, local LLMs
- langgraph_self_rag.ipynb
- Corrective Retrieval Augmented Generation
- Building Corrective RAG from scratch with open-source, local LLMs
- langgraph_crag.ipynb